One of the biggest applications of Web Scraping is in scraping hotel listings from various sites. This could be to monitor prices, create an aggregator, or provide better UX on top of existing hotel booking websites.
Here is a simple script that does that. We will use BeautifulSoup to help us extract information and we will retrieve hotel information on Realtor.com.
To start with, this is the boilerplate code we need to get the Realtor.com search results page and set up BeautifulSoup to help us use CSS selectors to query the page for meaningful data.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.11 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9',
'Accept-Encoding': 'identity'
}
#'Accept-Encoding': 'identity'
url = 'https://www.realtor.com/realestateandhomes-search/San-Francisco_CA'
response=requests.get(url,headers=headers)We are also passing the user agent headers to simulate a browser call so we don't get blocked.
Now let's analyze the Realtor.com search results for a destination we want. This is how it looks.
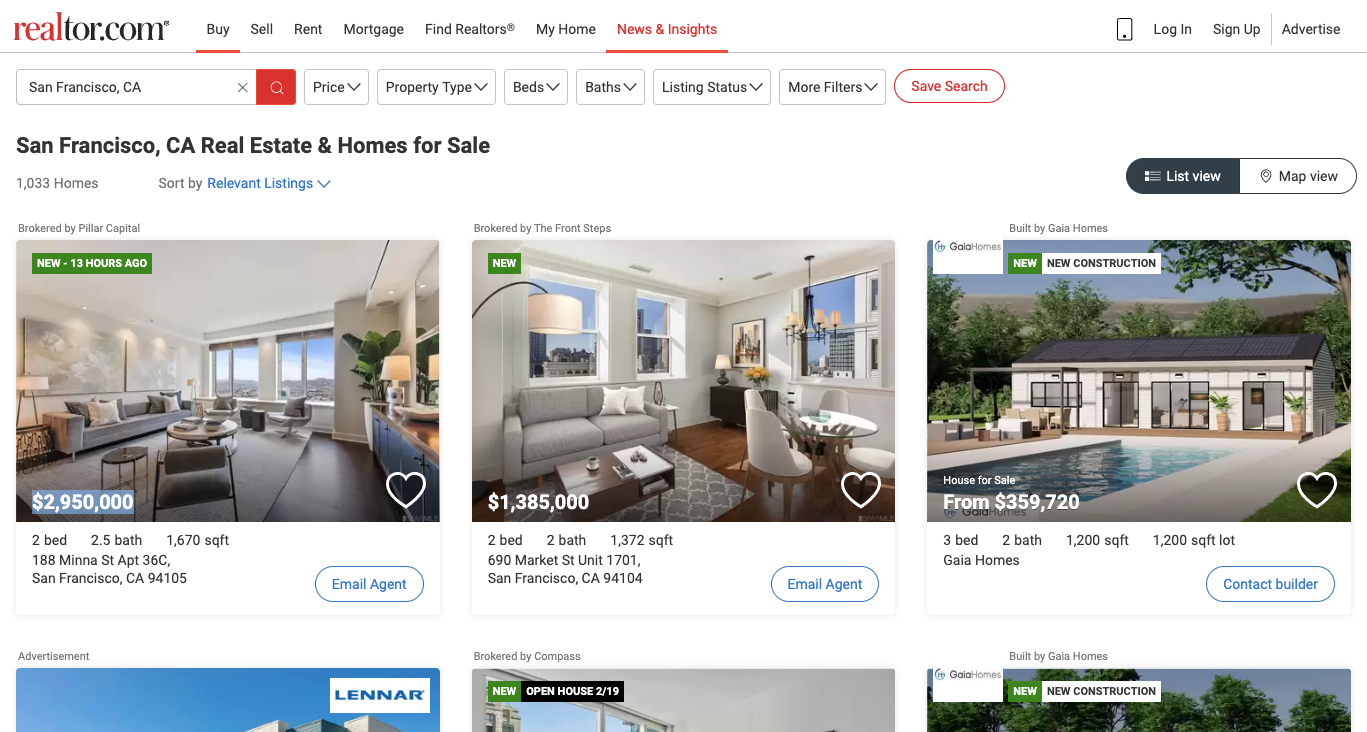
And when we inspect the page we find that each of the items HTML is encapsulated in a tag with the class component_property-card.
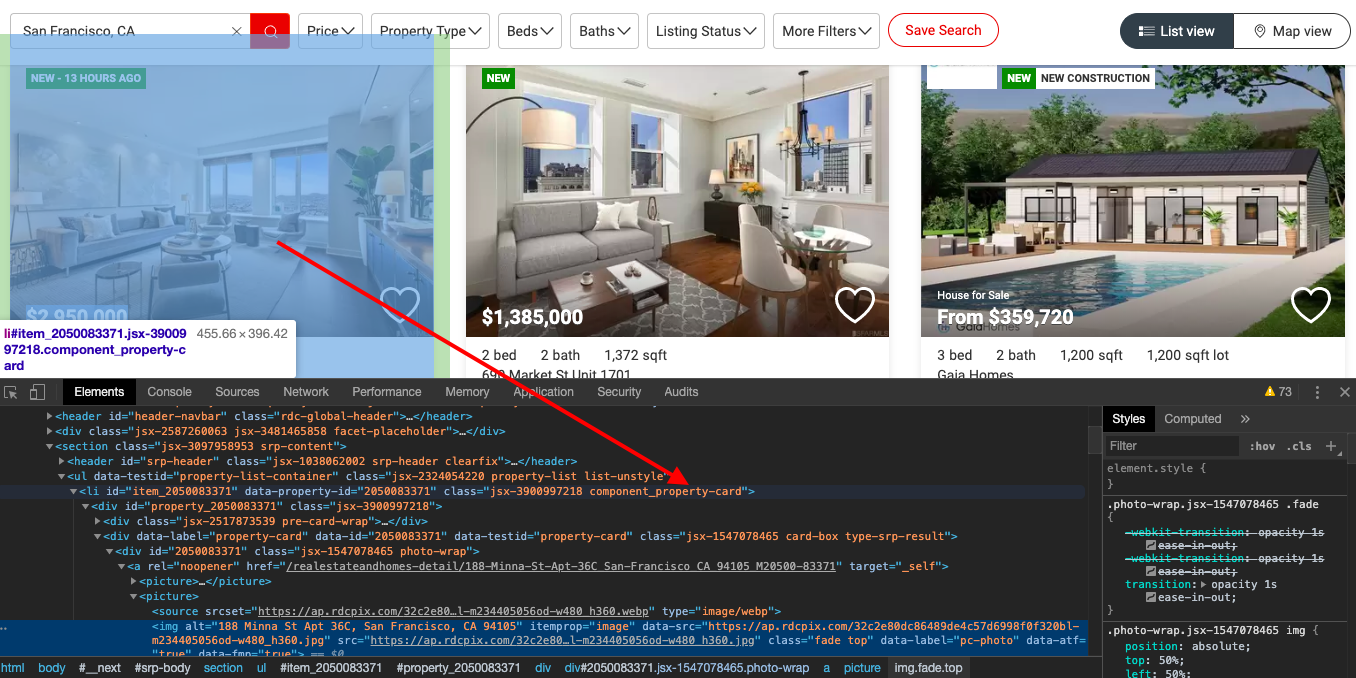
We could just use this to break the HTML document into these cards which contain individual item information like this.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.11 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9',
'Accept-Encoding': 'identity'
}
#'Accept-Encoding': 'identity'
url = 'https://www.realtor.com/realestateandhomes-search/San-Francisco_CA'
response=requests.get(url,headers=headers)
#print(response.content)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('.component_property-card'):
try:
print('**********')
print(item)
except Exception as e:
#raise e
print('')And when you run it.
python3 scraperealtor.pyYou can tell that the code is isolating the cards HTML.
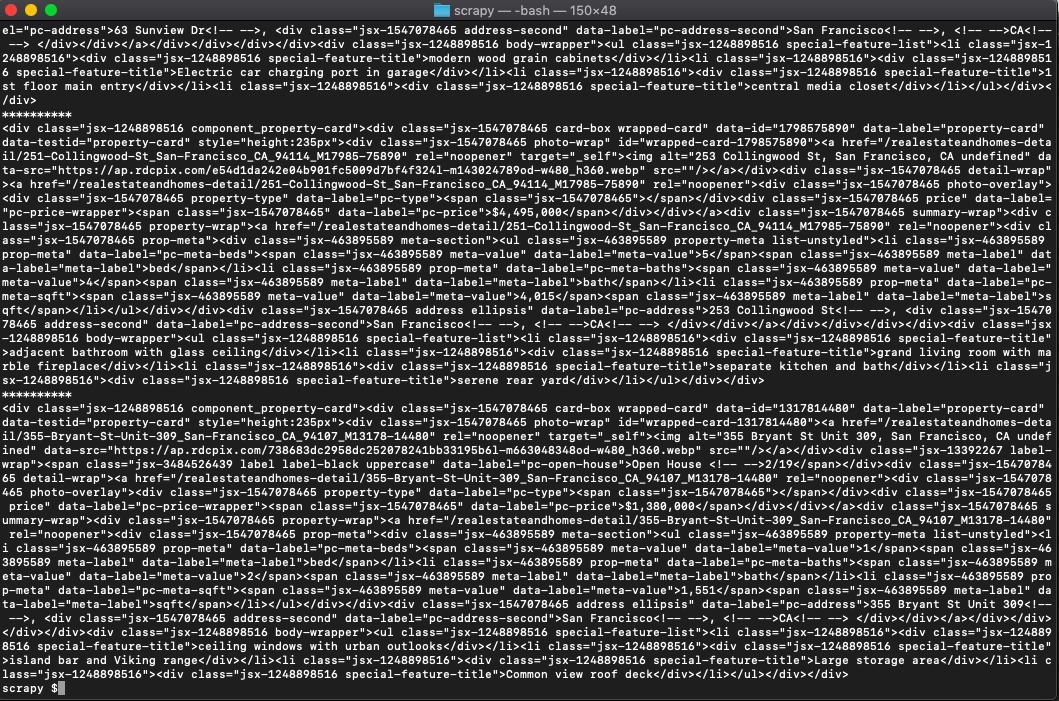
On further inspection, you can see that the cost of the place is always has the property data-label set to pc-price. So let's try and retrieve that:
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.11 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9',
'Accept-Encoding': 'identity'
}
#'Accept-Encoding': 'identity'
url = 'https://www.realtor.com/realestateandhomes-search/San-Francisco_CA'
response=requests.get(url,headers=headers)
#print(response.content)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('.component_property-card'):
try:
print('**********')
#print(item)
print(item.select('[data-label=pc-price]')[0].get_text())
except Exception as e:
#raise e
print('')That will get us the prices.
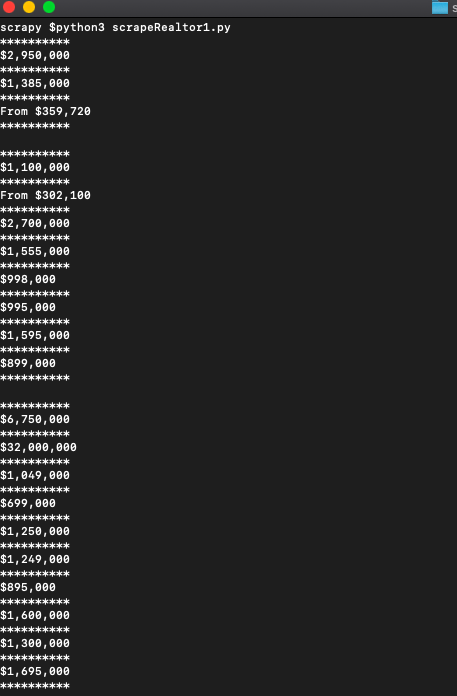
Bingo!
Now let's get the other data pieces.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.11 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9',
'Accept-Encoding': 'identity'
}
#'Accept-Encoding': 'identity'
url = 'https://www.realtor.com/realestateandhomes-search/San-Francisco_CA'
response=requests.get(url,headers=headers)
#print(response.content)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('.component_property-card'):
try:
print('**********')
#print(item)
print(item.select('[data-label=pc-price]')[0].get_text())
print(item.select('img')[0]['data-src'])
print(item.select('.summary-wrap')[0].get_text())
print(item.select('.address')[0].get_text())
print(item.select('.property-meta')[0].get_text())
print(item.select('.special-feature-list')[0].get_text())
except Exception as e:
#raise e
print('')And when run.
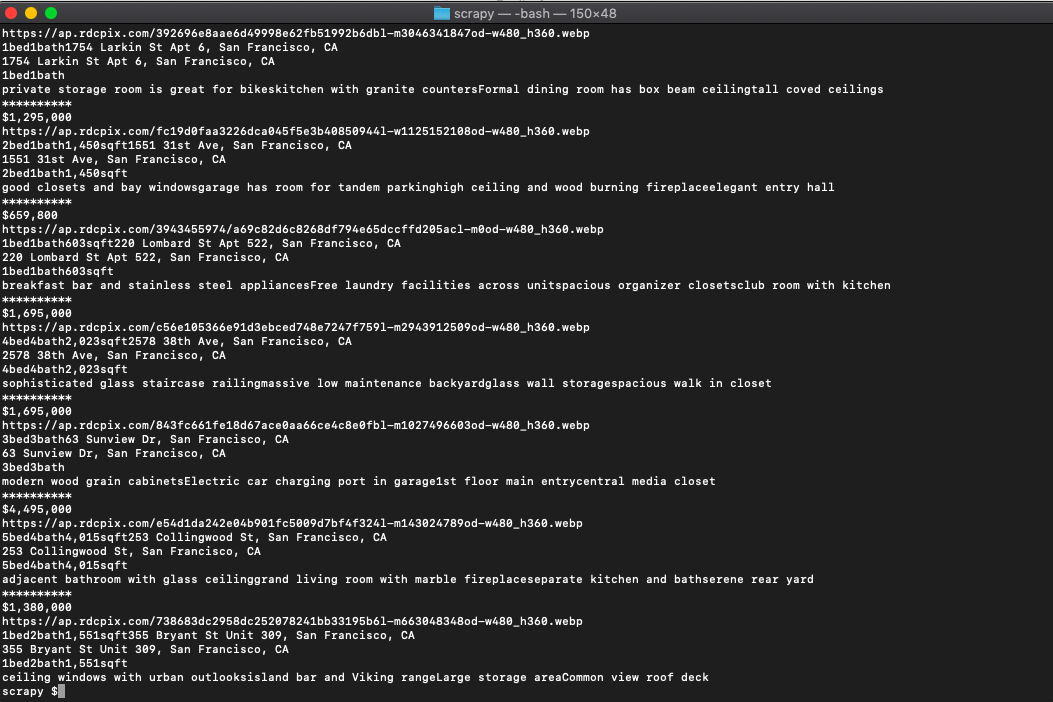
Produces all the info we need including address, summary, image link, etc.
In more advanced implementations you will need to even rotate the User-Agent string so Realtor cant tell its the same browser!
If we get a little bit more advanced, you will realize that Realtor can simply block your IP ignoring all your other tricks. This is a bummer and this is where most web crawling projects fail.
Overcoming IP Blocks
Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project which gets the job done consistently and one that never really works.
Plus with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
- With millions of high speed rotating proxies located all over the world,
- With our automatic IP rotation
- With our automatic User-Agent-String rotation (which simulates requests from different, valid web browsers and web browser versions)
- With our automatic CAPTCHA solving technology,
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.