Scrapy is one of the most accessible tools that you can use to scrape and also spider a website with effortless ease.
Today lets see how we can scrape Yelp to get restaurant phone numbers for let says the San Fransisco location.
Here is the URL we are going to scrape https://www.yelp.com/search?find_desc=Restaurants&find_loc=San Francisco, CA&ns=1

First, we need to install scrapy if you haven't already.
pip install scrapyOnce installed, go ahead and create a project by invoking the startproject command.
scrapy startproject scrapingprojectThis will output something like this.
New Scrapy project 'scrapingproject', using template directory '/Library/Python/2.7/site-packages/scrapy/templates/project', created in:
/Applications/MAMP/htdocs/scrapy_examples/scrapingproject
You can start your first spider with:
cd scrapingproject
scrapy genspider example example.comAnd create a folder structure like this.
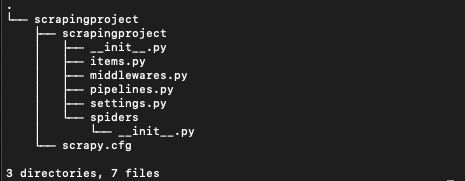
Now CD into the scrapingproject. You will need to do it twice like this.
cd scrapingproject
cd scrapingprojectNow we need a spider to crawl through the Yelp results page. So we use the genspider to tell scrapy to create one for us. We call the spider ourfirstbot and pass it to the URL of the yelp page.
scrapy genspider ourfirstbot www.yelp.com/search?find_desc=Restaurants&find_loc=San Francisco, CA&ns=1This should return successfully like this.
Created spider 'ourfirstbot' using template 'basic' in module:
scrapingproject.spiders.ourfirstbotGreat. Now open the file ourfirstbot.py in the spider's folder. It should look like this.
# -*- coding: utf-8 -*-
import scrapy
class OurfirstbotSpider(scrapy.Spider):
name = 'ourfirstbot'
allowed_domains = ['www.yelp.com/search?find_desc=Restaurants&find_loc=San Francisco, CA&ns=1']
start_urls = ['https://www.yelp.com/search?find_desc=Restaurants&find_loc=San Francisco, CA&ns=1']
def parse(self, response):
passLet's examine this code before we proceed.
The allowed_domains array restricts all further crawling to the domain paths specified here.
start_urls is the list of URLs to crawl. For us, in this example, we only need one URL.
The def parse(self, response): function is called by scrapy after every successful URL crawl. Here is where we can write our code to extract the data we want.
We now need to find the CSS selector of the elements we need to extract the data. Go to the URL https://www.yelp.com/search?find_desc=Restaurants&find_loc=San Francisco, CA&ns=1 and right-click on the Name of one of the restaurants and click on inspecting. This will open the Google Chrome Inspector like below.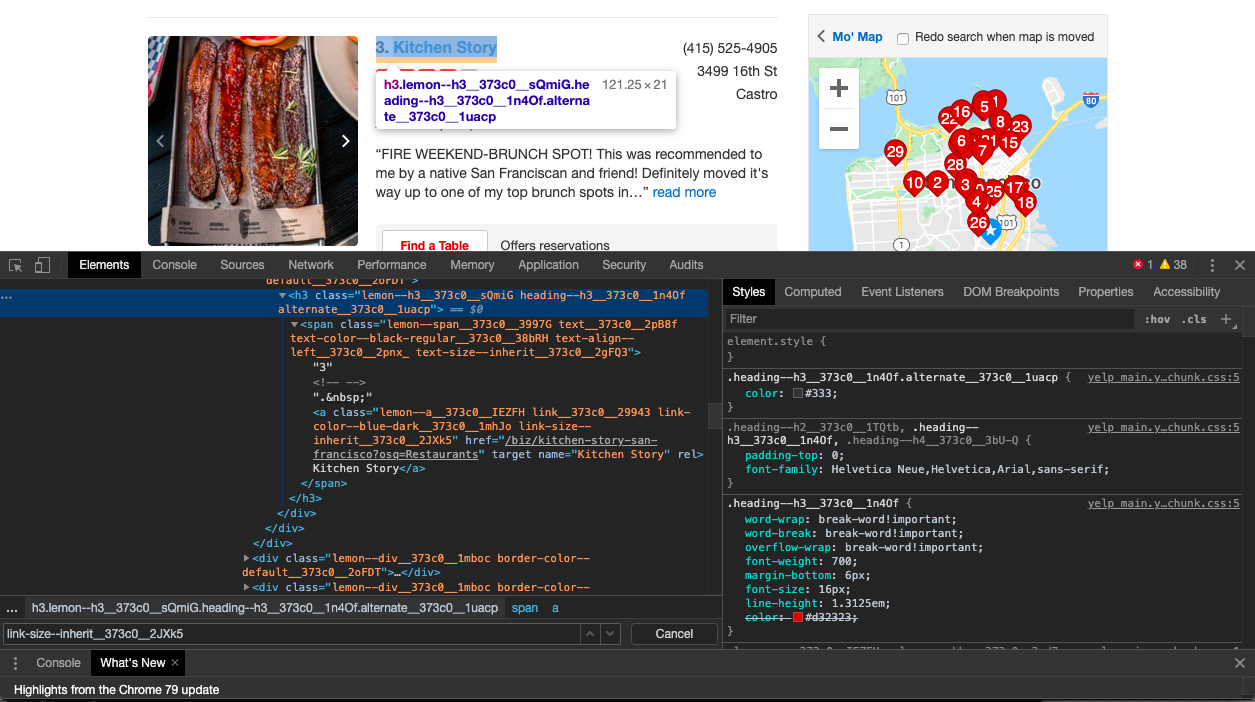
You can see that the CSS class name of the Name element is heading--h3__373c0__1n4Of, so we are going to ask scrapy to get us the contents of this class like this.
names = response.css('.heading--h3__373c0__1n4Of').extract()Similarly, we try and find the class names of the reviews element (note that the class names might change by the time you run this code)
reviews = response.css('.reviewCount__373c0__2r4xT::text').extract()If you are unfamiliar with CSS selectors, you can refer to this page by Scrapy https://docs.scrapy.org/en/latest/topics/selectors.html
We have to use the zip function now to map a similar index of multiple containers so that they can be used just using a single entity. So here is how it looks.
# -*- coding: utf-8 -*-
import scrapy
from bs4 import BeautifulSoup
class OurfirstbotSpider(scrapy.Spider):
name = 'ourfirstbot'
start_urls = [
'https://www.yelp.com/search?find_desc=Restaurants&find_loc=San Francisco, CA&ns=1',
]
def parse(self, response):
#yield response
names = response.css('.heading--h3__373c0__1n4Of').extract()
reviews = response.css('.reviewCount__373c0__2r4xT::text').extract()
#Give the extracted content row wise
for item in zip(names, reviews):
#create a dictionary to store the scraped info
all_items = {
'name' : BeautifulSoup(item[0]).text,
'reviews' : item[1],
}
#yield or give the scraped info to scrapy
yield all_itemsAnd now lets run this with the command (Notice we are turning off obeying Robots.txt)
scrapy crawl ourfirstbot -s ROBOTSTXT_OBEY=FalseBingo. You get the results below.
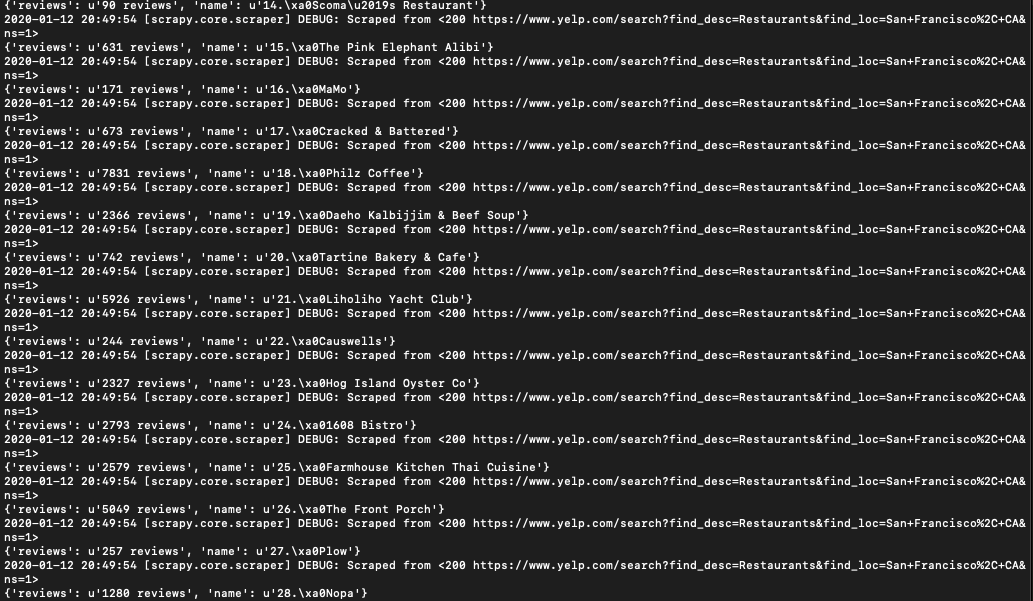
Now, let's export the extracted data to a CSV file. All you have to do is to provide an export file like this.
scrapy crawl ourfirstbot -o data.csvOr if you want the data in the JSON format.
scrapy crawl ourfirstbot -o data.jsonScaling Scrapy
The example above is ok for small scale web crawling projects. But if you try to scrape large quantities of data at high speeds from websites like Yelp, you will find that sooner or later, your access will be restricted. Yelp can tell you are a bot, so one of the things you can do is run the crawler impersonating a web browser. This is done by passing the user agent string to the Yelp web server, so it doesn't block you.
Like this
scrapy crawl ourfirstbot -s USER_AGENT="Mozilla/5.0 (Windows NT 6.1; WOW64)/
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36" /
-s ROBOTSTXT_OBEY=FalseIn more advanced implementations, you will need even to rotate this string, so Yelp cant tell it the same browser! Welcome to web scraping.
If we get a little bit more advanced, you will realize that Yelp can simply block your IP, ignoring all your other tricks. This is a bummer, and this is where most web crawling projects fail.
Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project, which gets the job done consistently and one that never really works.
Plus, with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
- With millions of high speed rotating proxies located all over the world
- With our automatic IP rotation
- With our automatic User-Agent-String rotation (which simulates requests from different, valid web browsers and web browser versions)
- With our automatic CAPTCHA solving technology
hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
A simple API can access the whole thing like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.
Once you have an API_KEY from Proxies API, you just have to change your code to this.
# -*- coding: utf-8 -*-
import scrapy
from bs4 import BeautifulSoup
class OurfirstbotSpider(scrapy.Spider):
name = 'ourfirstbot'
start_urls = [
'http://api.proxiesapi.com/?key=API_KEY&url=https://www.yelp.com/search?find_desc=Restaurants&find_loc=San Francisco, CA&ns=1',
]
def parse(self, response):
#yield response
names = response.css('.heading--h3__373c0__1n4Of').extract()
reviews = response.css('.reviewCount__373c0__2r4xT::text').extract()
#Give the extracted content row wise
for item in zip(names, reviews):
#create a dictionary to store the scraped info
all_items = {
'name' : BeautifulSoup(item[0]).text,
'reviews' : item[1],
}
#yield or give the scraped info to scrapy
yield all_itemsWe have only changed one line at the start_urls array, and that will make sure we will never have to worry about IP rotation, user agent string rotation, or even rate limits ever again.