The Stack Behind A Production Level Rotating Proxy Service
Background
Proxies API is a rotating proxies API that developers use to fetch hard to scrape data at scale and consistently. We auto-rotate millions of proxy servers, and also handle auto retries, rotate user agent strings, handle cookies, CAPTCHAs behind the scenes.
The Constraints
The service has to scale to millions of URL fetches a day without lagging on speed and should work out of a single API like this.
curl “http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"
The Architecture
The architecture looks somewhat like this.
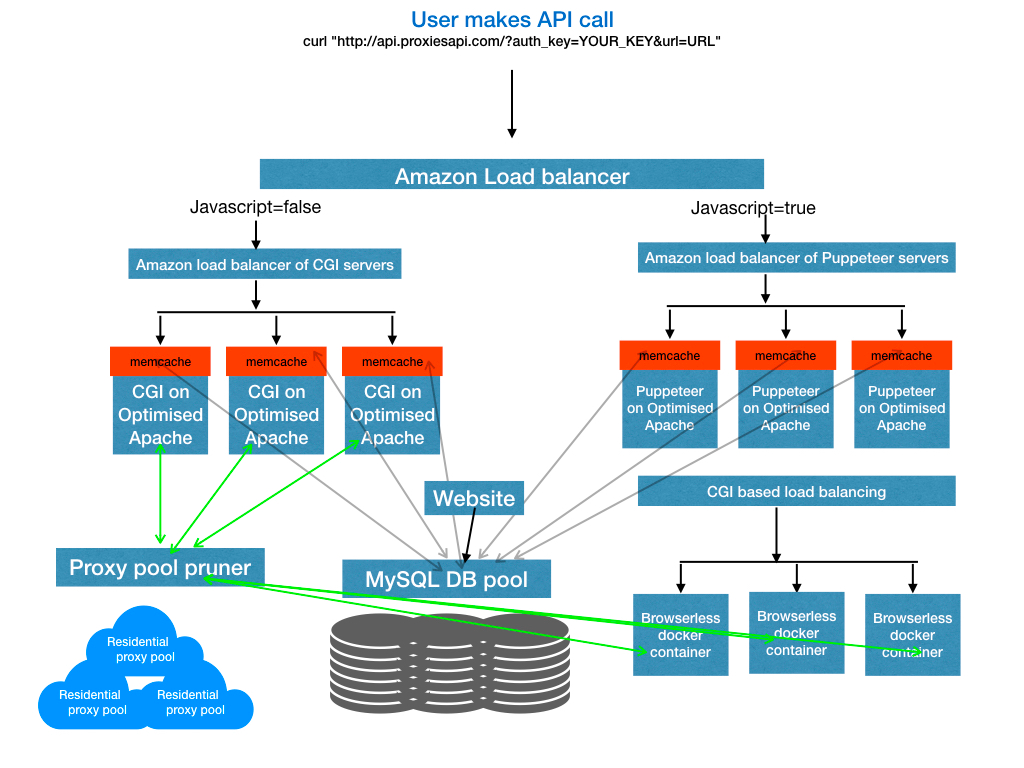
A more in-depth look at this architecture is provided in this article.
Load balancing & Serving
The whole infrastructure is on Amazon EC2. The load balancer plays a significant role in calling the right service based on just the variables passed and the API KEY that holds some secret information like what pool of servers are assigned for them etc.
Our plans have higher concurrency as customers pay more, so we need to pass them to more reliable, dedicated servers as they have higher concurrency needs.
Luckily amazon elastic load balancer can make this using rules you can set, which look at the URL patterns and direct them to different pools of servers intelligently.
Without this exact combination of facilities, we would not have been able to create it all using a single API call without compromising speed and performance somewhere.
We use Apache if there is a need for HTTP servers. Many of these are super optimized to be able to crawl data concurrently using multiple cores. We will soon write an article on how we can get the most amount of crawling ability out of Apache instances.
Proxy Components
For CGI, we use a combination of Python and even PHP where required.
Memcache is used to monitor and throttle concurrencies gracefully, so some rouge code by one of our clients doesn’t bring down the entire setup.
As I described earlier, most of this throttling happens in the way we route out requests from the load balancer.
We use the Node Js/Puppeteer library extensively as an interface to connect to Browserless docker instances located on multiple servers. Browserless is optimized to run as many ready-to-go instances of Chromium as possible, so there is no lag in loading any of them for our clients.
Database
We use good old MySQL in a Master/Slave configuration to hold user info, cache info, millions of proxy info, quality metrics for each, etc.
Maintenance tools
We have a pool pruner that’s written in Python running as a Cronjob. Uses Scrapy and Scrapyd extensively in making calls, monitoring, benchmarking, and pruning proxies from our database.
We use the Beanstalk library for Queues. We use Datadog for monitoring and PagerDuty for alerts.
The author is the founder of Proxies API, a proxy rotation API service.