Introduction
In today's data-driven world, extracting information from websites can provide valuable insights for various purposes, from market research to building recommendation systems. In this beginner-friendly guide, we'll walk you through the process of web scraping Yelp business listings using the Rust programming language. We'll cover everything from setting up your development environment to extracting and displaying business details.
This is the page we are talking about
Prerequisites
Before we dive into the code, let's ensure you have everything you need:
- Rust Installed: Make sure you have Rust installed on your system. If not, you can get it from the official Rust website.
- Dependencies: Install the required Rust dependencies using Cargo, Rust's package manager. You'll need
reqwest ,scraper , andurlencoding . You can add them to yourCargo.toml file like this: - ProxiesAPI Premium Account: To bypass Yelp's anti-bot mechanisms, you'll need a valid ProxiesAPI premium account and API key. Premium proxies are essential for this task, as they provide a level of anonymity and reliability that free proxies cannot guarantee.
Now, let's move on to the code explanation.
Code Explanation
Before we jump into the code, let's briefly explain what each library does and understand the structure of Yelp's business listings page.
Now, let's explore Yelp's business listings structure. Yelp's business listings are typically structured with various elements for each business, including the business name, rating, price range, and more. We'll be targeting these elements in our code.
<div class="arrange-unit__09f24__rqHTg.arrange-unit-fill__09f24__CUubG.css-1qn0b6x">
<a class="css-19v1rkv">Business Name</a>
<span class="css-gutk1c">Rating</span>
<span class="priceRange__09f24__mmOuH">Price Range</span>
<span class="css-chan6m">Number of Reviews</span>
<span class="css-chan6m">Location</span>
</div>
Now, let's break down the code into step-by-step instructions.
Step-by-Step Guide
Step 1: Import Dependencies
use reqwest;
use scraper::{Html, Selector};
use urlencoding::encode;
#[tokio::main]
async fn main() {
// Rest of the code goes here
}
Step 2: Set the Yelp URL
let url = "<https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco%2C+CA>";
In this step, we set the target URL to search for Chinese restaurants in San Francisco.
Step 3: Encode the URL
let encoded_url = encode(url);
URL encoding is essential to handle special characters properly in the URL.
Step 4: Prepare the API URL
let api_url = format!("<http://api.proxiesapi.com/?premium=true&auth_key=YOUR_AUTH_KEY&url={}>", encoded_url);
We create the API URL by incorporating your ProxiesAPI premium authentication key. This URL will be used to route our request through premium proxies.
Step 5: Create a Reqwest Client
let client = reqwest::Client::new();
We create a Reqwest client, which will be responsible for making HTTP requests. We also set headers to mimic a real browser's request.
Step 6: Send the Request
let res = client.get(&api_url)
.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36")
.header("Accept-Language", "en-US,en;q=0.5")
.header("Accept-Encoding", "gzip, deflate, br")
.header("Referer", "<https://www.google.com/>")
.send()
.await;
In this step, we send an HTTP GET request using the client we created earlier. We also set headers to make our request look like it's coming from a legitimate browser.
Step 7: Parse HTML
if response.status().is_success() {
let body = response.text().await.unwrap();
parse_html(&body);
} else {
println!("Failed to retrieve data. Status Code: {:?}", response.status());
}
We check if the response is successful and then parse the HTML content using the
Step 8: Iterate through Listings
Inspecting the page
When we inspect the page we can see that the div has classes called arrange-unit__09f24__rqHTg arrange-unit-fill__09f24__CUubG css-1qn0b6x
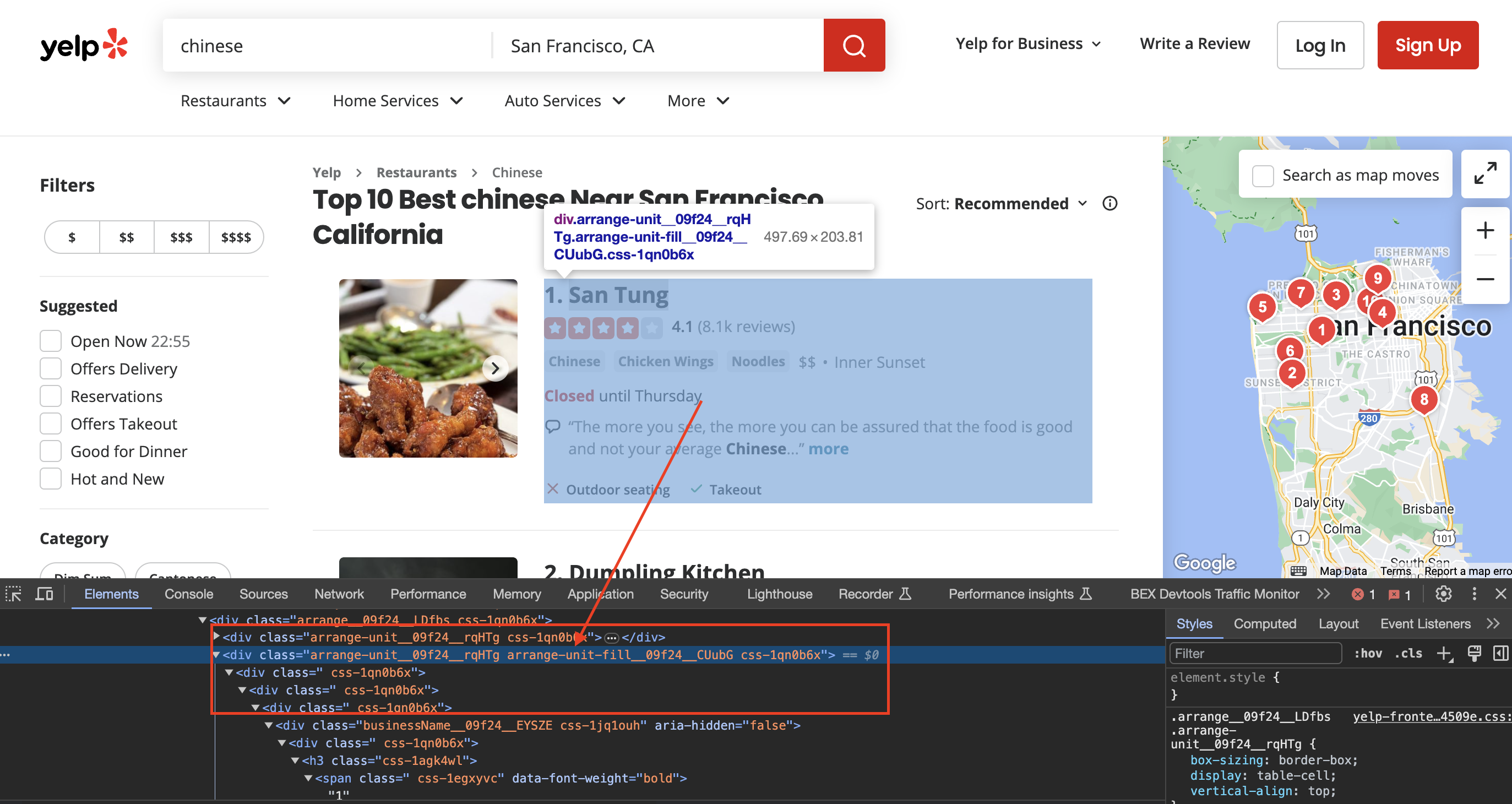
let listings_selector = Selector::parse("div.arrange-unit__09f24__rqHTg.arrange-unit-fill__09f24__CUubG.css-1qn0b6x").unwrap();
for listing in listings {
// Extract business details
// Print the details to the console
}
We iterate through the scraped listings, targeting specific elements using selectors, and extract business details such as the name, rating, price range, number of reviews, and location.
Step 9: Display Results
println!("Business Name: {}", business_name);
println!("Rating: {}", rating);
println!("Number of Reviews: {}", num_reviews);
println!("Price Range: {}", price_range);
println!("Location: {}", location);
println!("==============================");
Finally, we print the extracted information to the console.
Next Steps and Further Learning
Web scraping opens up a world of possibilities for data gathering and analysis. Here are some next steps and resources for further learning:
Here is the full code:
use reqwest;
use scraper::{Html, Selector};
use urlencoding::encode;
#[tokio::main]
async fn main() {
let url = "https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco%2C+CA";
let encoded_url = encode(url);
let api_url = format!("http://api.proxiesapi.com/?premium=true&auth_key=YOUR_AUTH_KEY&url={}", encoded_url);
let client = reqwest::Client::new();
let res = client.get(&api_url)
.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36")
.header("Accept-Language", "en-US,en;q=0.5")
.header("Accept-Encoding", "gzip, deflate, br")
.header("Referer", "https://www.google.com/")
.send()
.await;
match res {
Ok(response) => {
if response.status().is_success() {
let body = response.text().await.unwrap();
parse_html(&body);
} else {
println!("Failed to retrieve data. Status Code: {:?}", response.status());
}
},
Err(e) => println!("Request failed: {:?}", e),
}
}
fn parse_html(html: &str) {
let document = Html::parse_document(html);
let listings_selector = Selector::parse("div.arrange-unit__09f24__rqHTg.arrange-unit-fill__09f24__CUubG.css-1qn0b6x").unwrap();
let business_name_selector = Selector::parse("a.css-19v1rkv").unwrap();
let rating_selector = Selector::parse("span.css-gutk1c").unwrap();
let price_range_selector = Selector::parse("span.priceRange__09f24__mmOuH").unwrap();
let span_selector = Selector::parse("span.css-chan6m").unwrap();
let listings = document.select(&listings_selector);
for listing in listings {
let business_name = listing.select(&business_name_selector).next().map(|e| e.inner_html()).unwrap_or("N/A".to_string());
let rating = listing.select(&rating_selector).next().map(|e| e.inner_html()).unwrap_or("N/A".to_string());
let price_range = listing.select(&price_range_selector).next().map(|e| e.inner_html()).unwrap_or("N/A".to_string());
let span_elements: Vec<_> = listing.select(&span_selector).collect();
let num_reviews = match span_elements.get(0) {
Some(element) => element.inner_html().trim().to_string(),
None => "N/A".to_string(),
};
let location = match span_elements.get(1) {
Some(element) => element.inner_html().trim().to_string(),
None => "N/A".to_string(),
};
println!("Business Name: {}", business_name);
println!("Rating: {}", rating);
println!("Number of Reviews: {}", num_reviews);
println!("Price Range: {}", price_range);
println!("Location: {}", location);
println!("==============================");
}
}