Web scraping is the process of extracting data from websites automatically using code. ChatGPT has emerged as a powerful tool for web scraping due to its natural language capabilities. This article provides a comprehensive guide on web scraping using ChatGPT, covering the key concepts, approaches, examples and code snippets.
Introduction
ChatGPT has opened up new possibilities for automating web scraping without writing complex code. At its core, web scraping with ChatGPT involves:
The key benefit is the ability to get scrapers created with minimal coding knowledge. However, providing the right instructions is crucial for ChatGPT to generate accurate scrapers.
This article covers various techniques for web scraping using ChatGPT with examples for scraping static and dynamic websites.
Prerequisites
Before diving into the steps, ensure the following:
Lets start simple
Its super easy for well known websites… lets take IMDB for example… We just use this prompt
web scrape https://www.imdb.com/chart/moviemeter/ and get all the movie names using python and beautifulsoupChatGPT responds with…
import requests
from bs4 import BeautifulSoup
url = "https://www.imdb.com/chart/moviemeter/"
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# Finding all the title columns which have the movie names
title_columns = soup.find_all('td', class_='titleColumn')
movies = []
for title_column in title_columns:
# Extracting movie names from the title columns
movie_name = title_column.a.get_text(strip=True)
movies.append(movie_name)
# Printing the list of movie names
for i, movie in enumerate(movies, start=1):
print(f"{i}. {movie}")
else:
print("Failed to retrieve the webpage. Status Code:", response.status_code)When you run this script, unfortunately it fails…
Failed to retrieve the webpage. Status Code: 403Now we are getting into the trenches… Lets modify the script a little bit. IMDB needs to see a browser signature for it to respond. So we add a user-agent header. This is the new script…
import requests
from bs4 import BeautifulSoup
url = "https://www.imdb.com/chart/moviemeter/"
# Define headers to mimic a browser request
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
title_columns = soup.find_all('td', class_='titleColumn')
movies = []
for title_column in title_columns:
movie_name = title_column.a.get_text(strip=True)
movies.append(movie_name)
for i, movie in enumerate(movies, start=1):
print(f"{i}. {movie}")
else:
print("Failed to retrieve the webpage. Status Code:", response.status_code)Now it downloads the webpage but it doesnt extract any data. So we need to help ChatGPT some more..
The titles are located in...<h3 class="ipc-title__text">Barbie</h3>It will change the code to this…
import requests
from bs4 import BeautifulSoup
url = "https://www.imdb.com/chart/moviemeter/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# Finding all the <h3> tags with class 'ipc-title__text' which have the movie names
title_tags = soup.find_all('h3', class_='ipc-title__text')
movies = []
for title_tag in title_tags:
# Extracting movie names from the <h3> tags
movie_name = title_tag.get_text(strip=True)
movies.append(movie_name)
# Printing the list of movie names
for i, movie in enumerate(movies, start=1):
print(f"{i}. {movie}")
else:
print("Failed to retrieve the webpage. Status Code:", response.status_code)This code works. When you run it gives use the results…

Scraping Dynamic Websites
Dynamic websites have content that changes without reloading the page, like infinite scroll, tabs, popups etc. Scraping them requires automated browsers like Selenium.
Here is an example to scrape product data from an ecommerce site:
Instructions
Extract product titles and pricing from amazon.com using Python and Selenium
Wait for 10 seconds for page load
Locate elements with:
- Tag: div
- Class: product
Within each element:
- Find <h3> tag and extract text for title
- Find <p> tag and extract text for price
Click on 'Next Page' button to load more products
Export scraped data to CSV file
ChatGPT Generated Code
from selenium import webdriver
from selenium.webdriver.common.by import By
import csv
driver = webdriver.Chrome()
driver.get("https://amazon.com")
driver.implicitly_wait(10)
products = driver.find_elements(By.CSS_SELECTOR, "div.product")
titles = []
prices = []
for product in products:
title = product.find_element(By.TAG_NAME, "h3").text
price = product.find_element(By.TAG_NAME, "p").text
titles.append(title)
prices.append(price)
next_button = driver.find_element(By.ID, "next_page")
next_button.click()
# Extract data from next pages
with open('output.csv', 'w') as file:
writer = csv.writer(file)
writer.writerow(['Title', 'Price'])
writer.writerows(zip(titles, prices))
This code uses Selenium to load dynamic content, extract data and handle pagination. The data is exported to CSV for analysis. The following section explains how you can install Selenium if you dont have it on your system
Installing Selenium
To use Selenium for scraping dynamic websites, it needs to be installed along with a browser driver.
Steps
Install Selenium:
pip install selenium
Install browser driver:
For Chrome:
pip install chromedriver-autoinstaller
For Firefox:
pip install geckodriver-autoinstaller
Import Selenium:
from selenium import webdriver
driver = webdriver.Chrome() # For Chrome
# driver = webdriver.Firefox() # For Firefox
Pass driver to ChatGPT code:
Provide the driver object to ChatGPT for dynamic scraping:
Use the provided driver object for dynamic scraping:
driver = webdriver.Chrome()
ChatGPT will then generate code using this driver to scrape dynamic pages.
This covers the basics of setting up Selenium for web scraping with ChatGPT. The driver will automatically handle JavaScript, AJAX calls, infinite scrolls etc. making scraping seamless.
Key Takeaways
Alternative Approach - Using ChatGPT “Advanced Data Analysis”
An alternative approach provided by ChatGPT is using its code interpreter or Advanced Data Analysis. Here, instead of providing scraping instructions, the target page HTML can directly be uploaded.
Suppose we want to scrape Amazon search results page…
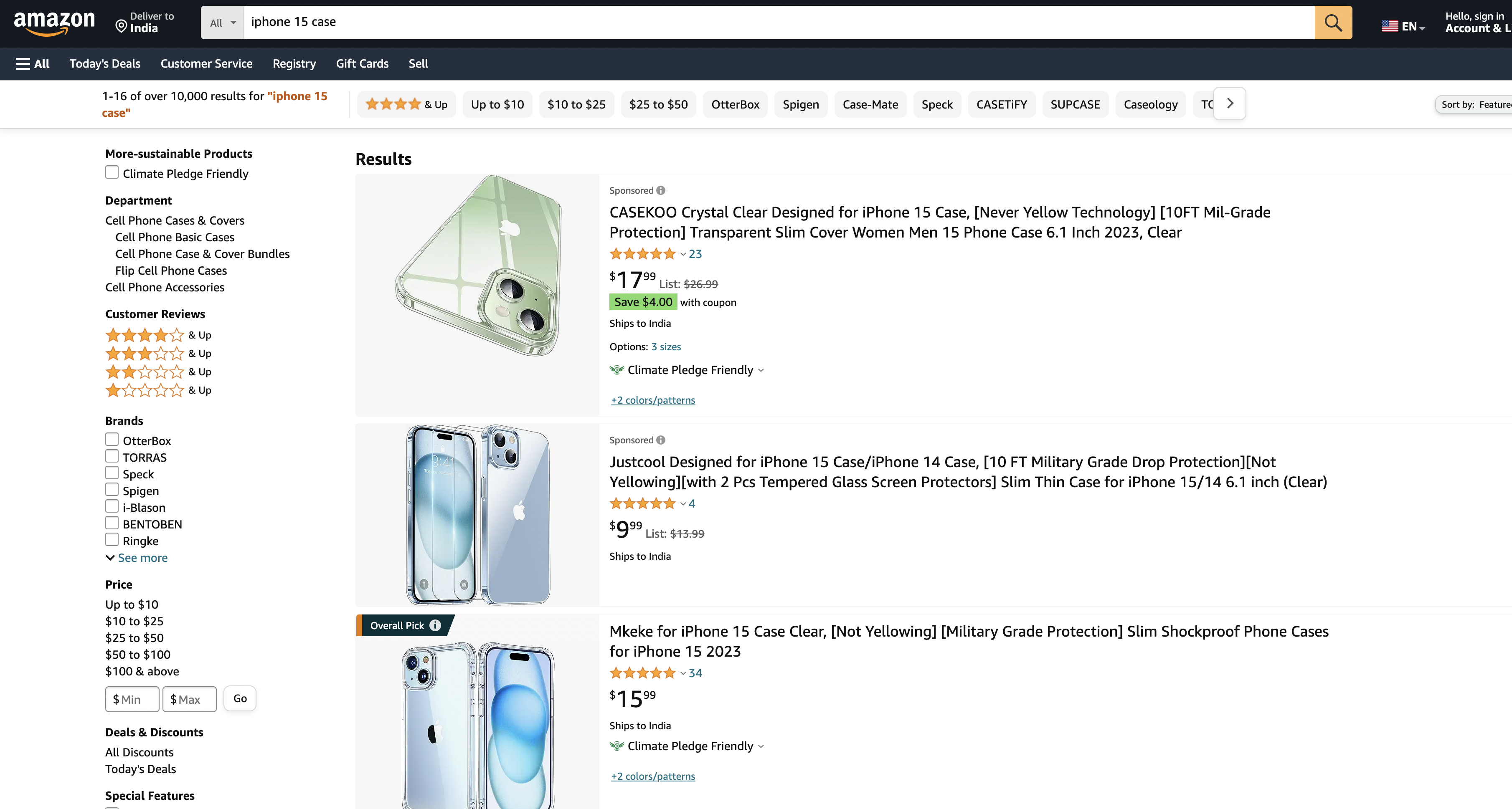
Just save the page as HTML on your disk.
Then just drag and drop it into the GPT4 - Advanced Data Analysis section.
ChatGPT might need some help here in locating the title… We notice using Chrome’s Inspect element that the title is in the H2 tag. We paste the whole thing into ChatGPT
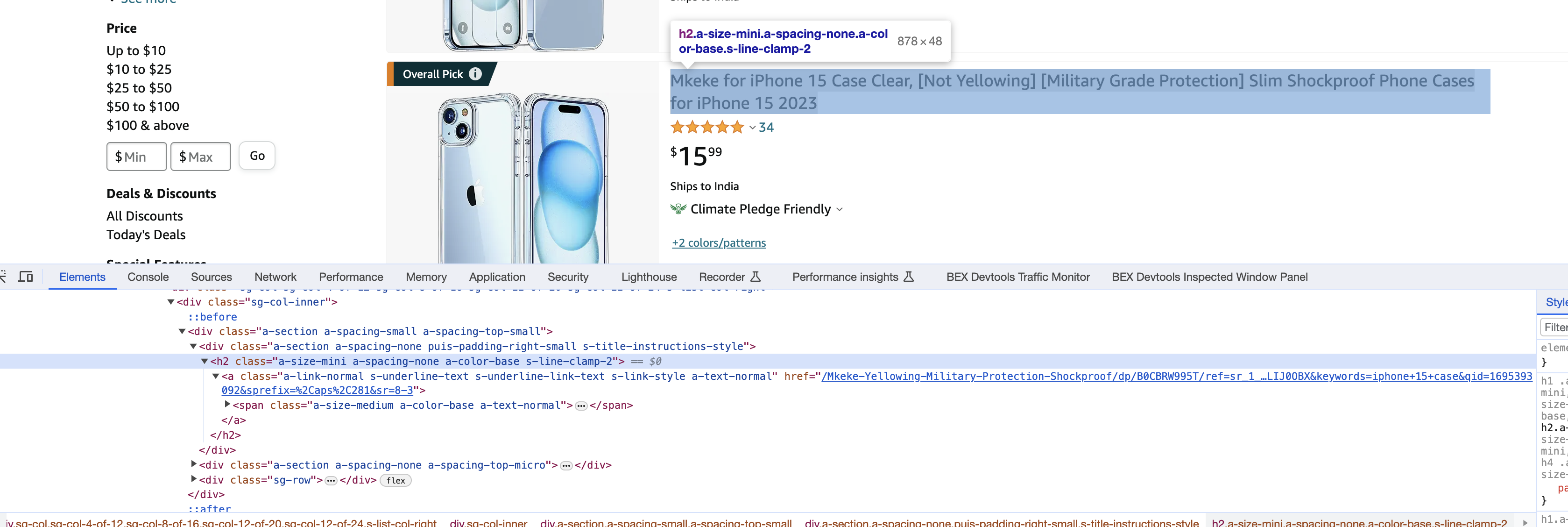
Here is the prompt…
Extract product title and price from the attached page HTML using Python and BeautifulSoup. Export results to CSV. Tht Title tag is in H2 like this... <h2 class="a-size-mini a-spacing-none a-color-base s-line-clamp-2">
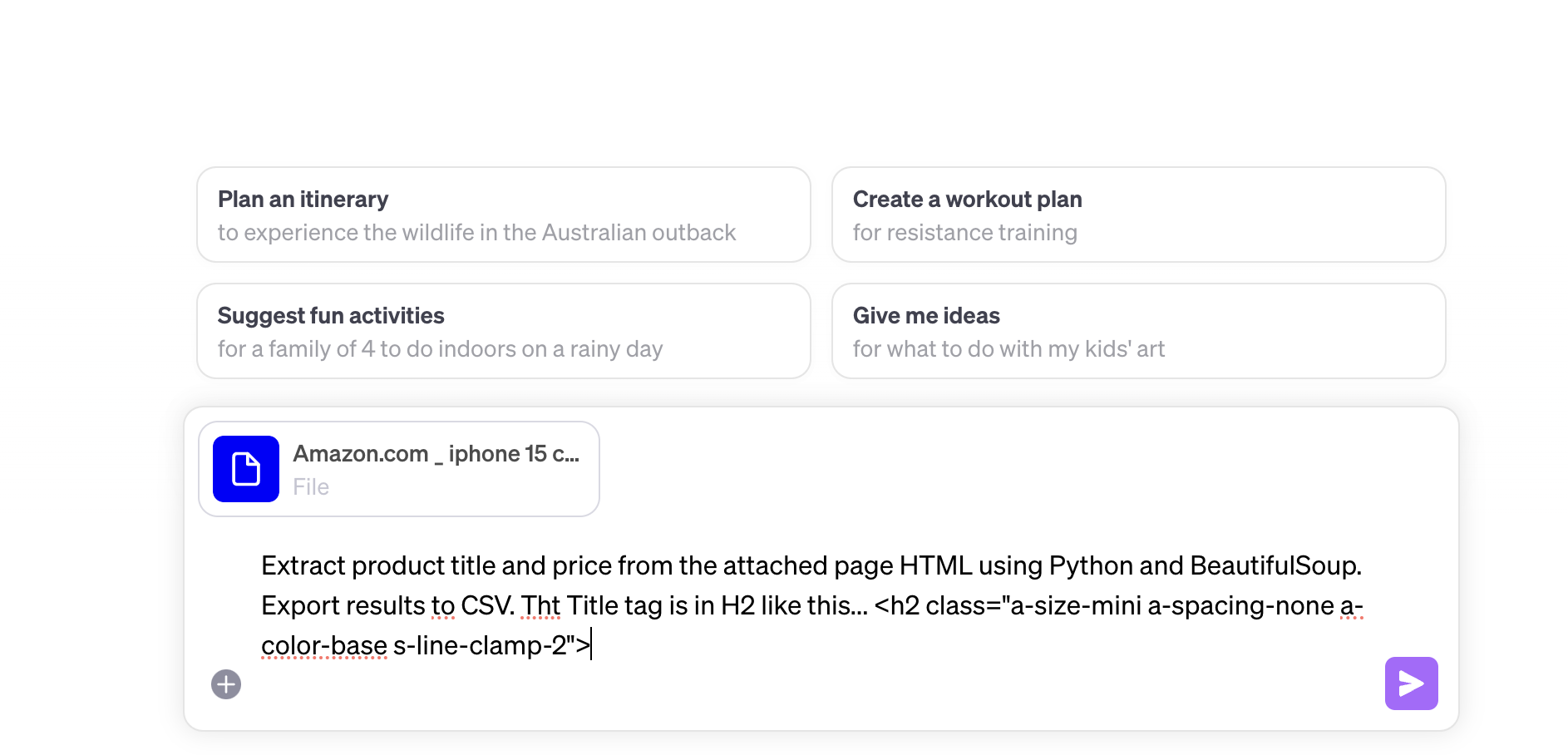
While it succeeded it getting the titles, you can see that it is struggling to get the prices… So we help ChatGPT out again…
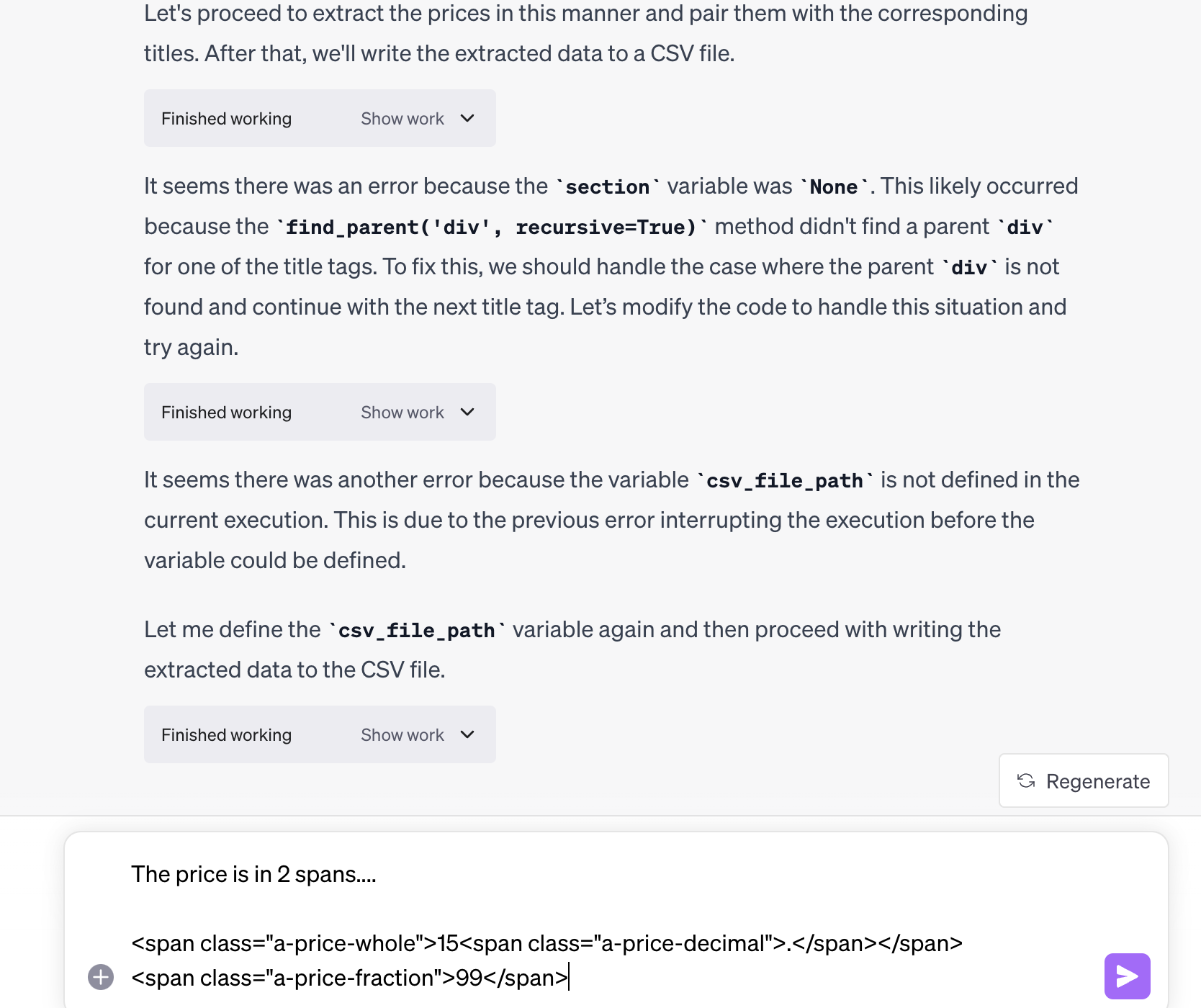
Success! ChatGPT gives us the data…
But, lets not stop there. Lets ask it for the code that made the data possible. Use this prompt…
give me the code that makes this possibleChatGPT should gladly return the code like this…
import re
import csv
from bs4 import BeautifulSoup
# Define the path to the HTML file
file_path = 'path_to_your_html_file.html'
# Read the HTML file and create a BeautifulSoup object
with open(file_path, 'r', encoding='utf-8') as file:
soup = BeautifulSoup(file.read(), 'html.parser')
# Function to extract price from a specific section of the HTML
def extract_price(section):
# Look for span tags with class 'a-price' which usually contains the price
price_tag = section.find('span', class_='a-price')
# If a price tag is found, extract the price value from it
if price_tag:
# Extract the whole and fraction parts of the price and concatenate them
whole_part_tag = price_tag.find('span', class_='a-price-whole')
fraction_part_tag = price_tag.find('span', class_='a-price-fraction')
if whole_part_tag and fraction_part_tag:
# Concatenate the whole part, decimal point, and fraction part to form the full price
whole_part = whole_part_tag.get_text(strip=True).replace(',', '') # Remove commas in whole part
fraction_part = fraction_part_tag.get_text(strip=True)
return f"${whole_part}.{fraction_part}"
return None # Return None if no price is found
# List to hold the extracted product title and price pairs
products = []
# Loop through each product title tag to extract title and price pairs
for title_tag in soup.find_all('h2', class_='a-size-mini a-spacing-none a-color-base s-line-clamp-2'):
title = title_tag.get_text(strip=True) # Extract the product title
# Get the parent section of the title tag which likely contains the price tag as well
section = title_tag.find_parent('div', recursive=True)
if section: # Check if a parent div is found
price = extract_price(section) # Extract the price from the section
products.append({'Title': title, 'Price': price})
# Define the path to the CSV file
csv_file_path = 'path_where_you_want_to_save_csv_file.csv'
# Write the extracted data to the CSV file
with open(csv_file_path, 'w', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=['Title', 'Price'])
writer.writeheader()
writer.writerows(products)
print(f"Data has been written to {csv_file_path}")When to use ChatGPT Code Interpreter?
Some benefits of using the code interpreter are:
Use this when the target site has:
However, the code instructions approach provides more control over the scraping logic.
Full Code Examples
Here are the full code samples created above for reference:
Static Site Scraping
import requests
from bs4 import BeautifulSoup
url = "https://www.imdb.com/chart/moviemeter/"
# Define headers to mimic a browser request
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
title_columns = soup.find_all('td', class_='titleColumn')
movies = []
for title_column in title_columns:
movie_name = title_column.a.get_text(strip=True)
movies.append(movie_name)
for i, movie in enumerate(movies, start=1):
print(f"{i}. {movie}")
else:
print("Failed to retrieve the webpage. Status Code:", response.status_code)
Dynamic Site Scraping
from selenium import webdriver
from selenium.webdriver.common.by import By
import csv
driver = webdriver.Chrome()
driver.get("<https://ecomsite.com>")
driver.implicitly_wait(10)
products = driver.find_elements(By.CSS_SELECTOR, "div.product")
titles = []
prices = []
for product in products:
title = product.find_element(By.TAG_NAME, "h3").text
price = product.find_element(By.TAG_NAME, "p").text
titles.append(title)
prices.append(price)
next_button = driver.find_element(By.ID, "next_page")
next_button.click()
with open('output.csv', 'w') as file:
writer = csv.writer(file)
writer.writerow(['Title', 'Price'])
writer.writerows(zip(titles, prices))
Code Interpreter Scraping
import re
import csv
from bs4 import BeautifulSoup
# Define the path to the HTML file
file_path = 'path_to_your_html_file.html'
# Read the HTML file and create a BeautifulSoup object
with open(file_path, 'r', encoding='utf-8') as file:
soup = BeautifulSoup(file.read(), 'html.parser')
# Function to extract price from a specific section of the HTML
def extract_price(section):
# Look for span tags with class 'a-price' which usually contains the price
price_tag = section.find('span', class_='a-price')
# If a price tag is found, extract the price value from it
if price_tag:
# Extract the whole and fraction parts of the price and concatenate them
whole_part_tag = price_tag.find('span', class_='a-price-whole')
fraction_part_tag = price_tag.find('span', class_='a-price-fraction')
if whole_part_tag and fraction_part_tag:
# Concatenate the whole part, decimal point, and fraction part to form the full price
whole_part = whole_part_tag.get_text(strip=True).replace(',', '') # Remove commas in whole part
fraction_part = fraction_part_tag.get_text(strip=True)
return f"${whole_part}.{fraction_part}"
return None # Return None if no price is found
# List to hold the extracted product title and price pairs
products = []
# Loop through each product title tag to extract title and price pairs
for title_tag in soup.find_all('h2', class_='a-size-mini a-spacing-none a-color-base s-line-clamp-2'):
title = title_tag.get_text(strip=True) # Extract the product title
# Get the parent section of the title tag which likely contains the price tag as well
section = title_tag.find_parent('div', recursive=True)
if section: # Check if a parent div is found
price = extract_price(section) # Extract the price from the section
products.append({'Title': title, 'Price': price})
# Define the path to the CSV file
csv_file_path = 'path_where_you_want_to_save_csv_file.csv'
# Write the extracted data to the CSV file
with open(csv_file_path, 'w', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=['Title', 'Price'])
writer.writeheader()
writer.writerows(products)
print(f"Data has been written to {csv_file_path}")
Questions you may have
Does ChatGPT allow web scraping?
Yes. It is legal as far ChatGPT terms are concerned.
How to get chatgpt to read a website?
You can use the Advanced data analysis tool to just upload the HTML of the webpage and then ask it to scrape it using various techniques described above.
Where does ChatGPT scrape data from?
It can’t scrape the internet on its own at the moment.
Can ChatGPT read a web page?
It can’t browse the internet at the moment but you can use the Advanced data analysis tool to just upload the HTML of the webpage and then ask it to scrape it using various techniques described above.
Conclusion
This article provided a comprehensive overview of web scraping using ChatGPT with various examples and code samples. The key takeaways are:
Web scraping can be automated without complex coding by strategically tapping into ChatGPT's capabilities. With the right techniques, it is possible to extract data from virtually any website.
ChatGPT heralds an exciting new era in intelligent automation!
However, this approach also has some limitations:
A more robust solution is using a dedicated web scraping API like Proxies API
With Proxies API, you get:
With features like automatic IP rotation, user-agent rotation and CAPTCHA solving, Proxies API makes robust web scraping easy via a simple API:
curl "https://api.proxiesapi.com/?key=API_KEY&url=targetsite.com"
Get started now with 1000 free API calls to supercharge your web scraping!