In this tutorial you'll build robust web crawlers using libraries like BeautifulSoup, learn techniques to overcome real-world scraping challenges and best practices for large scale scraping.
You'll gain the skills to scrape complex sites, handle issues like rate limits, blocks, and javascript pages.
Why Python for Web Scraping?
Python is a popular language for web scraping due to its advantages:
In contrast, languages like C++ require more effort for basic scraping tasks. JavaScript platforms like Node.js can be complex for beginners when building scraping scripts.
Python's simplicity, power, and interoperability makes it ideal for scraping needs. Its high-quality libraries allow quick start to scraping at scale.
Best Python Web Scraping Libraries
Some of the most popular and robust Python libraries for web scraping are:
BeautifulSoup
Scrapy
Selenium
lxml
pyquery
Prerequisites
To follow along with the code examples in this article, you will need:
Virtual Environment (Recommended)
While optional, we highly recommended creating a virtual env for the project:
python -m venv my_web_scraping_env
The Libraries
We will be using the Requests, BeautifulSoup and OS libraries primarily:
pip install requests beautifulsoup4
This will fetch the libraries from PyPI and install them locally.
With the prerequisites installed, you are all setup! Let's start scraping.
Lets pick a target website
For demonstration purposes, we will be scraping the Wikipedia page List of dog breeds to extract information about various dog breeds.
The rationale behind choosing this page is:
This is the page we are talking about…
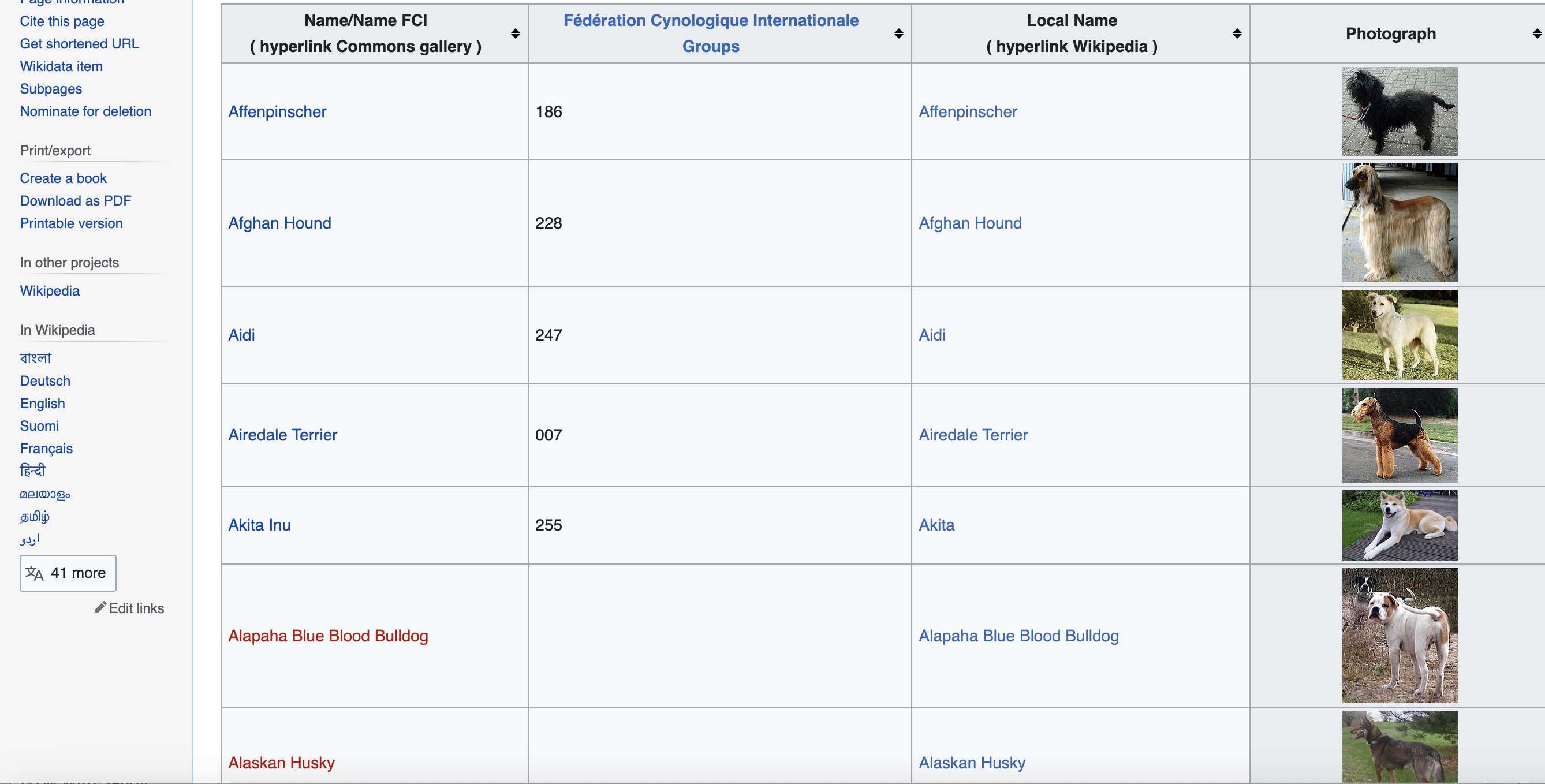
Other great pages to practice web scraping include:
The concepts covered will be applicable across any site.
Write the scraping code
Let's now closely examine the full code to understand how to systematically scrape data from the dogs breed webpage.
# Full code
import os
import requests
from bs4 import BeautifulSoup
url = '<https://commons.wikimedia.org/wiki/List_of_dog_breeds>'
# Headers to masquerade as a browser
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
# Download page HTML using requests
response = requests.get(url, headers=headers)
# Check valid response received
if response.status_code == 200:
# Parse HTML using Beautiful Soup
soup = BeautifulSoup(response.text, 'html.parser')
# CSS selector for the main tables
table = soup.find('table', {'class': 'wikitable sortable'})
# Initialize data lists to store scraped info
names = []
groups = []
local_names = []
photographs = []
# Create directory to store images
os.makedirs('dog_images', exist_ok=True)
# Loop through rows omitting header
for row in table.find_all('tr')[1:]:
# Extract each column data using CSS selectors
columns = row.find_all(['td', 'th'])
name = columns[0].find('a').text.strip()
group = columns[1].text.strip()
# Extract local name if exists
span_tag = columns[2].find('span')
local_name = span_tag.text.strip() if span_tag else ''
# Extract photo url if exists
img_tag = columns[3].find('img')
photograph = img_tag['src'] if img_tag else ''
# Download + Save image if url exists
if photograph:
response = requests.get(photograph)
if response.status_code == 200:
image_filename = os.path.join('dog_images', f'{name}.jpg')
with open(image_filename, 'wb') as img_file:
img_file.write(response.content)
names.append(name)
groups.append(group)
local_names.append(local_name)
photographs.append(photograph)
print(names)
print(groups)
print(local_names)
print(photographs)
The imports include standard Python libraries that provide HTTP requests functionality (
The
Together they form a very handy toolkit for scraping!
Downloading the page
We first construct the target URL and initialize a requests
url = '<https://commons.wikimedia.org/wiki/List_of_dog_breeds>'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
response = requests.get(url, headers=headers)
We also setup a custom
After getting the response, we can check the status code to ensure we received a proper HTML document:
if response.status_code == 200:
# Success!
print(response.text)
In case of errors (e.g. 404 or 500), we do not proceed with scraping and handle the failure.
Parsing the html
Since we received a valid HTML response, we can parse the text content using Beautiful Soup:
soup = BeautifulSoup(response.text, 'html.parser')
Beautiful Soup transforms the messy HTML into a parse tree that mirrors the DOM structure of tags, attributes and text. We can use CSS selectors and traversal methods to quickly isolate the data we need from this tree.
The Magic of Selectors for Data Extraction
One of the most magical parts of web scraping with Python's BeautifulSoup library is using CSS selectors to extract specific content from HTML pages.
Selectors allow us to visually target the tags enclosing the data we want scraped. BeautifulSoup makes selecting elements a breeze.
For example, consider extracting book titles from this snippet:
<div class="book-listing">
<img src="/covers/harry-potter.jpg">
<span class="title">Harry Potter and the Goblet of Fire</span>
<span class="rating">9.1</span>
</div>
<div class="book-listing">
<img src="/covers/lord-of-the-rings.jpg">
<span class="title">The Fellowship of the Ring</span>
<span class="rating">9.3</span>
</div>
We can directly target the
soup.select("div.book-listing > span.title")
This says - find all
And voila, we have exactly the titles isolated:
[<span class="title">Harry Potter and the Goblet of Fire</span>,
<span class="title">The Fellowship of the Ring</span>]
We can chain
[Harry Potter and the Goblet of Fire, The Fellowship of the Ring]
Selectors provide incredible precision during data extraction by leveraging the innate hierarchy of structured HTML tags surrounding it.
Some other examples of selectors:
# Select id attribute
soup.select("#book-title")
# Attribute equality match
soup.select('a[href="/login"]')
# Partial attribute match
soup.select('span[class^="title"]')
# Select direct descendant
soup.select("ul > li")
As you can see, by mastering different selector types and combining multiple selectors where needed - you gain immense power to zone in on and extract the exact data you need from any HTML document, eliminating nearly all guesswork. Lets get back to the task at hand now…
Finding the table
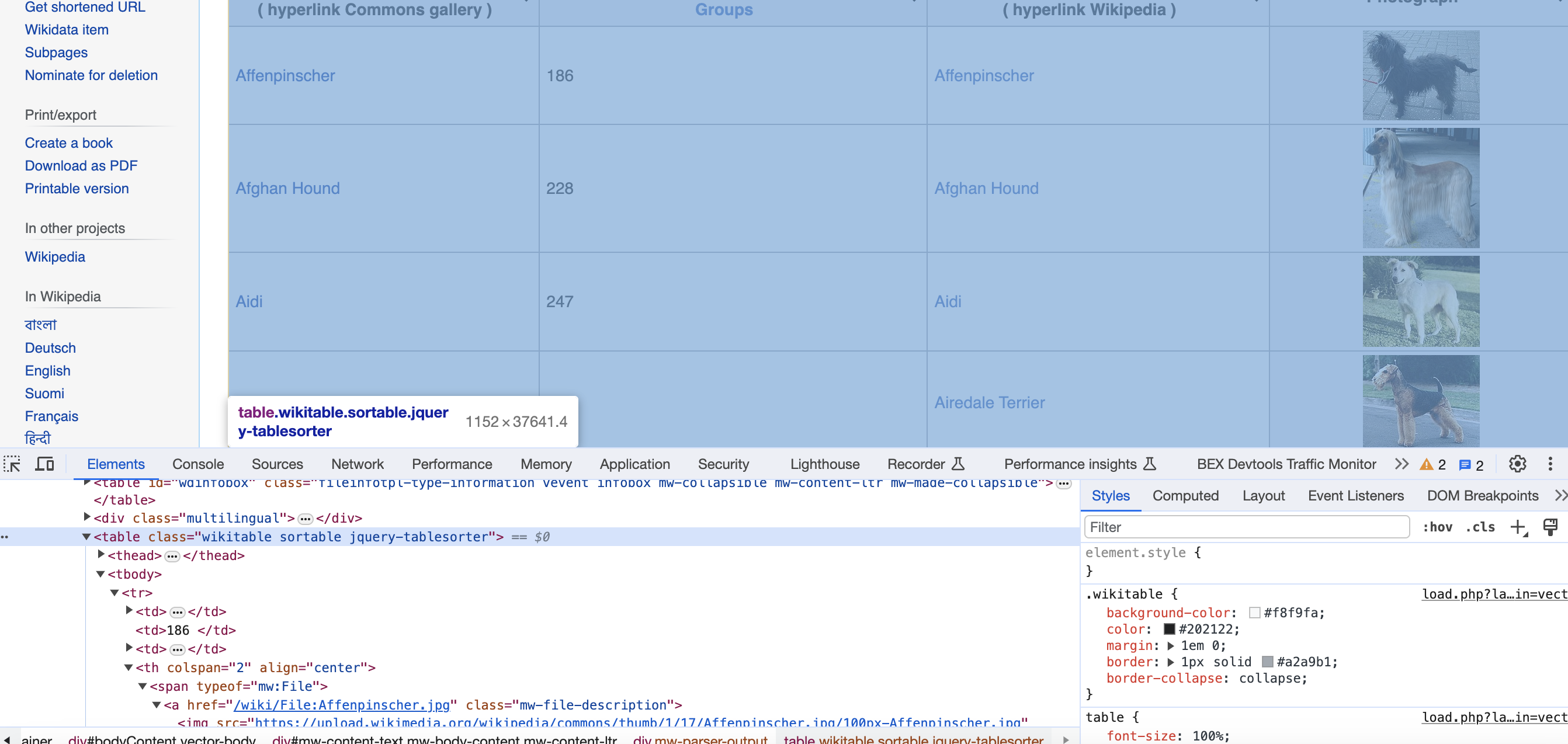
Looking at the Raw HTML, we notice a
We can simply select this using:
table = soup.find('table', {'class': 'wikitable sortable'})
This searches the parse tree for any
Extracting all the fields
With the table isolated, we loop through every
for row in table.find_all('tr')[1:]:
columns = row.find_all(['td', 'th'])
name = columns[0].find('a').text.strip()
group = columns[1].text.strip()
Here,
Using positional indexes in this columns list, we can extract the data within each cell cleanly:
name = columns[0].find('a').text.strip()
This grabs the anchor
Similarly for cells containing just text:
group = columns[1].text.strip()
We fetch
The power of CSS selectors in quickly isolating specific tags, ids, classes or attributes makes data extraction very precise and straightforward in Beautiful Soup.
Downloading and saving the images
After scraping textual data like names, groups etc in each row, we check the last cell for an image link:
img_tag = columns[3].find('img')
photograph = img_tag['src'] if img_tag else ''
This tries detecting and fetching src attribute on any image tag if exists.
We can then download and save images using this url if present:
if photograph:
response = requests.get(photograph)
image_filename = os.path.join('dog_images', f'{name}.jpg')
with open(file_path, 'wb') as img_file:
img_file.write(response.content)
We reuse the
And that's it! By using
Alternative libraries and tools for web scraping
While requests and BeautifulSoup form the most popular combination, here are some alternatives worth considering:
Scrapy
An open source modular scraping framework meant for large scale crawling that handles throttling, cookies, proxy rotation automatically. Recommended for complex needs.
Selenium
Performs actual browser automation by controlling Chrome, Firefox etc. Enables scraping dynamic content that renders via JavaScript. More complex setup.
pyppeteer
Headless browser automation like Selenium driven through Python code. Good for javascript rendered websites.
pyquery
Offers jQuery style element selection. Scrape code looks very clean due to chaining syntax similar to jQuery.
lxml
A very fast XML/HTML parser. Great when raw parsing performance is critical.
Challenges of Web Scraping in the real world: Some tips & best practices
While basic web scraping is easy, building robust production-grade scalable crawlers brings its own challenges:
Handling Dynamic Content
Many websites rely heavily on JavaScript to render content dynamically. Static scraping then fails. Solutions: Use browser automation tools like Selenium or scraper specific solutions like Scrapy's splash integration.
Here is a simple Hello World example to handle dynamic content using Selenium browser automation:
from selenium import webdriver
from selenium.webdriver.common.by import By
# Initialize chrome webdriver
driver = webdriver.Chrome()
# Load page
driver.get("<https://example.com>")
# Wait for title to load from dynamic JS execution
driver.implicitly_wait(10)
# Selenium can extract dynamically loaded elements
print(driver.title)
# Selenium allows clicking buttons triggering JS events
driver.find_element(By.ID, "dynamicBtn").click()
# Inputs can be handled as well
search = driver.find_element(By.NAME, 'search')
search.send_keys('Automate using Selenium')
search.submit()
# Teardown browser after done
driver.quit()
The key capabilities offered by Selenium here are:
- Launches a real Chrome browser to load JavaScript
- Finds elements only available after execution of JS
- Can interact with page by clicking, entering text etc thereby triggering JavaScript events
- Experience mimics an actual user browsing dynamically generated content
Together this allows handling complex sites primarily driven by JavaScript for dynamic content. Selenium provides full programmatic control to automate browsers directly thereby scraping correctly.
Getting Blocked
Websites often block scrapers via blocked IP ranges or blocking characteristic bot activity through heuristics. Solutions: Slow down requests, properly mimic browsers, rotate user agents and proxies.
Rate Limiting
Servers fight overload by restricting number of requests served per time. Hitting these limits lead to temporary bans or denied requests. Solutions: Honor crawl delays, use proxies and ration requests appropriately.
Here is sample code to handle rate limiting while scraping:
Many websites have protection mechanisms that temporarily block scrapers when they detect too many frequent requests coming from a single IP address.
We can counter getting blocked by rate limits by adding throttling, proxies and random delays in our code.
import time
import random
import requests
from urllib.request import ProxyHandler, build_opener
# List of free public proxies
PROXIES = ["104.236.141.243:8080", "104.131.178.157:8085"]
# Pause 5-15 seconds between requests randomly
def get_request():
time.sleep(random.randint(5, 15))
proxy = random.choice(PROXIES)
opener = build_opener(ProxyHandler({'https': proxy}))
resp = opener.open("<https://example.com>")
return resp
for i in range(50):
response = get_request()
print("Request Success")
Here each request first waits for a random interval before executing. This prevents continuous rapid requests.
We also route every alternate request through randomly chosen proxy servers via rotated IP addresses.
Together, throttling down overall crawl pace and distributing requests over different proxy IPs prevents hitting site-imposed rate limits.
Additional improvements like automatically detecting rate limit warnings in responses and reacting accordingly can enhance the scraper's resilience further.
Rotating User Agents
Websites often try to detect and block scraping bots by tracking characteristic user agent strings.
To prevent blocks, it is good practice to rotate multiple well-disguised user agents randomly to mimic a real browser flow.
Here is sample code to pick a random desktop user agent from a predefined list using Python's random library before making each request:
import requests
import random
# List of desktop user agents
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36 OPR/43.0.2442.991"
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/604.4.7 (KHTML, like Gecko) Version/11.0.2 Safari/604.4.7"
]
# Pick a random user agent string
user_agent = random.choice(user_agents)
# Set request headers with user agent before making request
headers = {"User-Agent": user_agent}
response = requests.get(url, headers=headers)
By varying the user agent across requests in code runs, websites have a tougher time profiling traffic as coming from an automated bot using a static user agent. This allows the scraper to fly under the radar without getting blocked.
Some additional enhancements include:
With effective user agent rotation and an ever expanding list of strings, scrapers enjoy better longevity undetected before site administrators can profile and actively block them.
Browser Fingerprinting
Beyond simplistic user agent checks, websites have adopted advanced browser fingerprinting techniques to identify bots.
This involves browser attribute profiling - collecting information regarding device screen size, installed fonts, browser plugins etc. together called browser fingerprints.
These fingerprints tend to remain largely consistent, stable and unique for standard tool-based bots and automation software.
Dynamic websites track fingerprints of scrapers accessing them. By detecting known crawler fingerprints they can block them even if the user agents are rotated constantly.
Minimizing detection risks
Some ways to minimize exposing scraper fingerprints:
Essentially by mimicking the natural randomness and variability across genuine user browsers, scraper fingerprints can avoid easy profiling by sites simply as another standard browser.
Here is a code example to dynamically modify browser attributes to avoid fingerprinting:
from selenium import webdriver
import random
# List of common screen resolutions
screen_res = [(1366, 768), (1920, 1080), (1024, 768)]
# List of common font families
font_families = ["Arial", "Times New Roman", "Verdana"]
#Pick random resolution
width, height = random.choice(screen_res)
#Create chrome options
opts = webdriver.ChromeOptions()
# Set random screen res
opts.add_argument(f"--window-size={width},{height}")
# Set random user agent
opts.add_argument("--user-agent=Mozilla/5.0...")
# Set random font list
random_fonts = random.choices(font_families, k=2)
opts.add_argument(f'--font-list="{random_fonts[0]};{random_fonts[1]}"')
# Initialize driver with options
driver = webdriver.Chrome(options=opts)
# Access webpage
driver.get(target_url)
# Webpage sees every scraper request originating
# from distinct unpredictable browser profiles
Here we randomly configure our Selenium controlled Chrome instance with different screen sizes, user agents and font sets per request.
and here is how you do it using Python Requests…
import requests
import random
# Device profiles
desktop_config = {
'user-agent': 'Mozilla/5.0...',
'accept-language': ['en-US,en', 'en-GB,en'],
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'upgrade-insecure-requests': '1',
'sec-fetch-site': 'none',
'sec-fetch-mode': 'navigate',
'sec-fetch-user': '?1',
'sec-fetch-dest': 'document',
'cache-control': 'max-age=0'
}
mobile_config = {
'user-agent': 'Mozilla/5.0... Mobile',
'accept-language': ['en-US,en', 'en-GB,en'],
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'x-requested-with': 'mark.via.gp',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'navigate',
'sec-fetch-user': '?1',
'sec-fetch-dest': 'document',
'referer': '<https://www.example.com/>',
'accept-encoding': 'gzip, deflate, br',
'cache-control': 'max-age=0'
}
device_profiles = [desktop_config, mobile_config]
def build_headers():
profile = random.choice(device_profiles)
headers = {
'User-Agent': random.choice(profile['user-agent']),
'Accept-Language': random.choice(profile['accept-language']),
# Other headers
...
}
return headers
Now instead of hard coding, the scraper randomly selects from plausible configuration profiles including several identifying request headers - providing realistic and human-like mutations necessary to avoid fingerprint tracking.
Parsing Complex HTML
Scrape targets often have complex HTML structures, obfuscated tags and advanced client side code packing logic which break parsers. Solutions: Careful inspection of rendered source, using robust parsers like lxml and enhancing selectors.
Here are some common types of bad HTML scrape targets exhibit and techniques to handle them:
Improper Nesting
HTML can often have incorrectly nested tags:
<b>Latest News <p>Impact of oil prices fall...</b></p>
Solution: Use a parser like lxml that handles bad nesting and uneven tags more robustly.
Broken Markup
Tags could be unclosed:
<div>
<span class="title">Python Web Scraping <span>
Lorem ipsum...
</div>
Solution: Specify tag close explicitly while parsing:
title = soup.find("span", class_="title").text
Non-standard Elements
Vendor specific unrecognized custom tags may exist:
<album>
<cisco:song>Believer</cisco:song>
</album>
Solution: Search for standard tags in namespace:
song = soup.find("cisco:song").text
Non-text Content
Tables, images embedded between text tags:
<p>
Trending Now
<table>...</table>
</p>
Solution: Select child tags specifically:
paras = soup.select("p > text()")
This picks only text nodes as children ignoring other elements present under
As you can see, liberal use of selectors along with robust parsers provides the tools to handle even badly designed HTML and extract the required data reliably.
Other guidelines worth following:
Adopting these practices ensures reliable, resilient and responsible scraping operations.
Conclusion In this comprehensive guide, we took an in-depth look into web scraping using Python. We covered:
By learning core scraping paradigms, structuring code properly and applying optimization techniques, extracting accurate web data in Python at scale has become an achievable skill!
While these examples are great for learning, scraping production-level sites can pose challenges like CAPTCHAs, IP blocks, and bot detection. Rotating proxies and automated CAPTCHA solving can help.
Proxies API offers a simple API for rendering pages with built-in proxy rotation, CAPTCHA solving, and evasion of IP blocks. You can fetch rendered pages in any language without configuring browsers or proxies yourself.
This allows scraping at scale without headaches of IP blocks. Proxies API has a free tier to get started. Check out the API and sign up for an API key to supercharge your web scraping.
With the power of Proxies API combined with Python libraries like Beautiful Soup, you can scrape data at scale without getting blocked.