Web scraping is a cool way to gather a ton of data from websites by using a bit of code. This friendly guide dives into how you can use it with high-performance C++.
We'll touch on the basics like HTTP requests and HTML parsing, and even take a look at some important libraries.
There's even a fun tutorial where we'll scrape Wikipedia together! Also, we'll tackle real-world challenges you might face, such as handling bots and scraping on a large scale.
Is C++ a Good Language for Web Scraping?
C++ excels in web scraping due to its speed, efficiency, and integration with various libraries and tools. Its benefits include:
While Python is simpler and faster to write, C++ may be preferable for large-scale scraping due to its performance.
Best C++ Web Scraping Libraries
Here are popular C++ scrapers:
Other options include libcurl and Poco.
Prerequisites
To follow along with the web scraping example, you will need:
C++ compiler
This scraping code uses C++17 features so you need a modern C++ compiler like GCC 8+, Clang 6+ or MSVC 2019+.
cpp-httplib
We will use this library for the HTTP client and networking. To install:
git clone <https://github.com/yhirose/cpp-httplib.git>
cd cpp-httplib
cmake -Bbuild -H.
cmake --build build
pugixml
For fast XML parsing, we rely on pugixml which you can setup as:
git clone <https://github.com/zeux/pugixml>
cd pugixml
cmake -Bbuild -H.
cmake --build build
selector-lib
To simplify selecting elements from HTML, we use selector-lib:
git clone <https://github.com/amiremohamadi/selector-lib.git>
cd selector-lib
cmake -Bbuild -H.
cmake --build build
That covers the external dependencies needed to run the scraper code shown later.
Let's pick a target website
For this web scraping tutorial, we will scrape Wikipedia's list of dog breeds to extract information like names, breed groups, alternative names and images for various breeds.
The reasons this page makes a good scraping target are:
You could also try scraping other Wikipedia lists, news sites, blogs or really any site with data you want to collect.
For now, this is the page we are talking about…
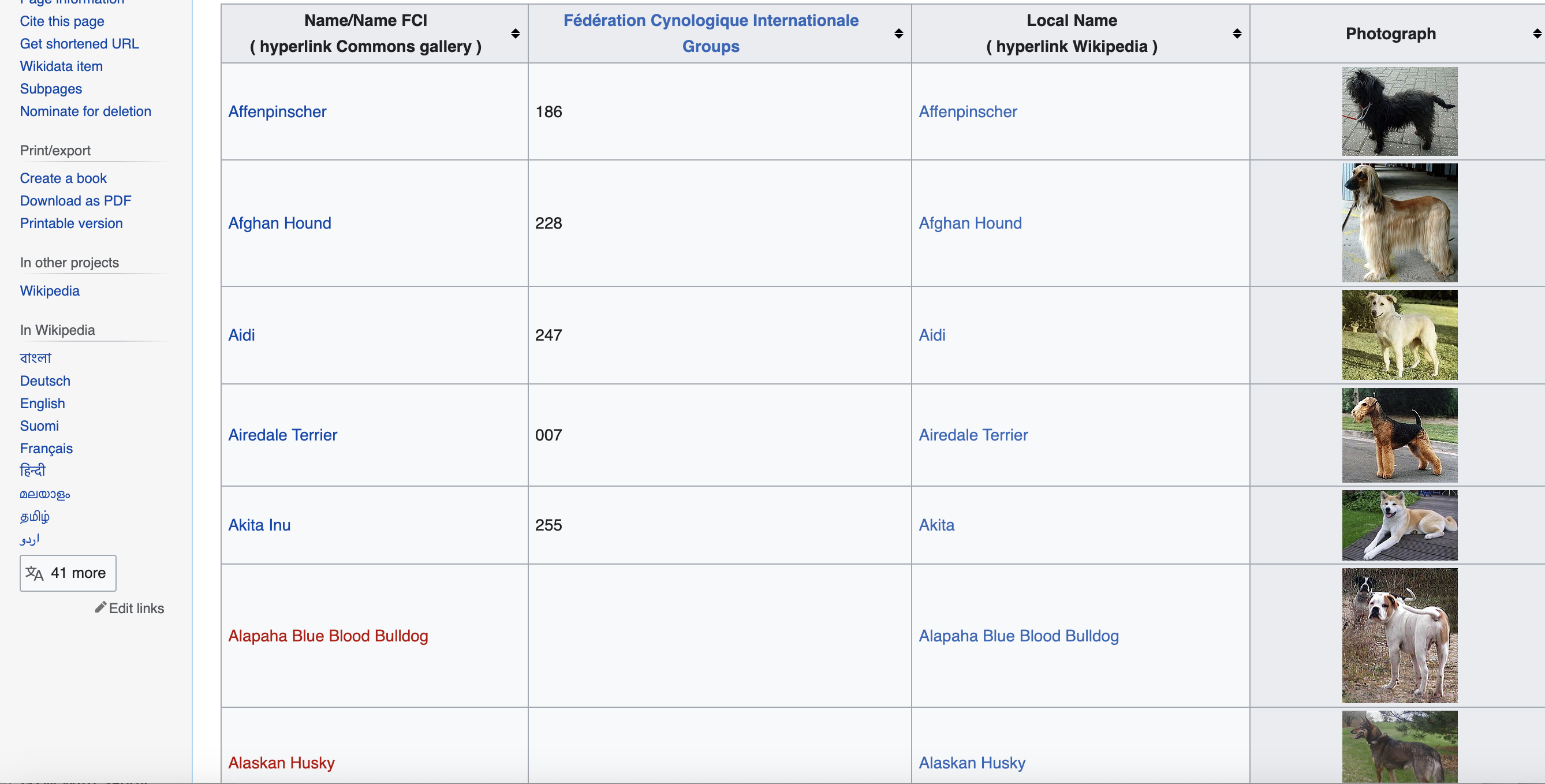
Write the scraping code
Below is the full code we will walkthrough piece-by-piece to scrape the dog breeds page.
// Includes
#include <httplib.h>
#include <selector/selector.h>
#include <fstream>
#include <vector>
// Vectors to store data
std::vector<std::string> names;
std::vector<std::string> groups;
std::vector<std::string> localNames;
std::vector<std::string> photographs;
// HTTP client
httplib::Client cli("commons.wikimedia.org");
// Send request
auto res = cli.Get("/wiki/List_of_dog_breeds",
{{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"}});
if(res) {
// Parse HTML
pugi::xml_document doc;
doc.load(res->body.c_str());
auto html = doc.child("html");
// Find table
auto table = html.select_node("table.wikitable.sortable").node();
// Iterate rows
for (auto& row : table.select_nodes("tr")) {
// Get cells
auto cells = row.select_nodes("td, th");
// Extract data
auto name = cells[0].child("a").text().get();
auto group = cells[1].text().get();
auto localNameNode = cells[2].select_node("span");
auto localName = localNameNode.text().get("");
auto img = cells[3].select_node("img");
auto photograph = img.attribute("src").value();
// Download image
if (!photograph.empty()) {
auto img_data = cli.Get(photograph.c_str());
std::ofstream file("dog_images/" + name + ".jpg", std::ios::binary);
file << img_data->body;
}
// Store data
names.push_back(name);
groups.push_back(group);
localNames.push_back(localName);
photographs.push_back(photograph);
}
}
Let's break this down section by section to understand what it's doing behind the scenes.
The includes
We start by including the necessary libraies:
#include <httplib.h> // cpp-httplib
#include <selector/selector.h> // selector-lib
#include <fstream> // file io
#include <vector> // dynamic arrays
No tricky setup needed here, just import what we need to scrape.
Downloading the page
Next we setup the HTTP client and make the request:
// HTTP client
httplib::Client cli("commons.wikimedia.org");
// Send request
auto res = cli.Get("/wiki/List_of_dog_breeds",
{{"User-Agent", "cpp-httplib"}});
Here we:
By default APIs these days will block vague requests lacking a user agent. So it's important to always spoof one to avoid access issues.
Setting User-Agent
We explicitly set a user agent even though it has a default:
auto res = cli.Get("/wiki/List_of_dog_breeds",
{{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"}});
This helps avoid blocks from sites limiting anonymous traffic without user agents.
Some tips for setting scrappy looking user agents:
Rotating user agents helps distribute requests across many identities making your scraper seem more human rather than bot-like.
Inspecting the code
Viewing the page in Chrome or Firefox inspector, we can see it has an HTML table with dog breed data we want.
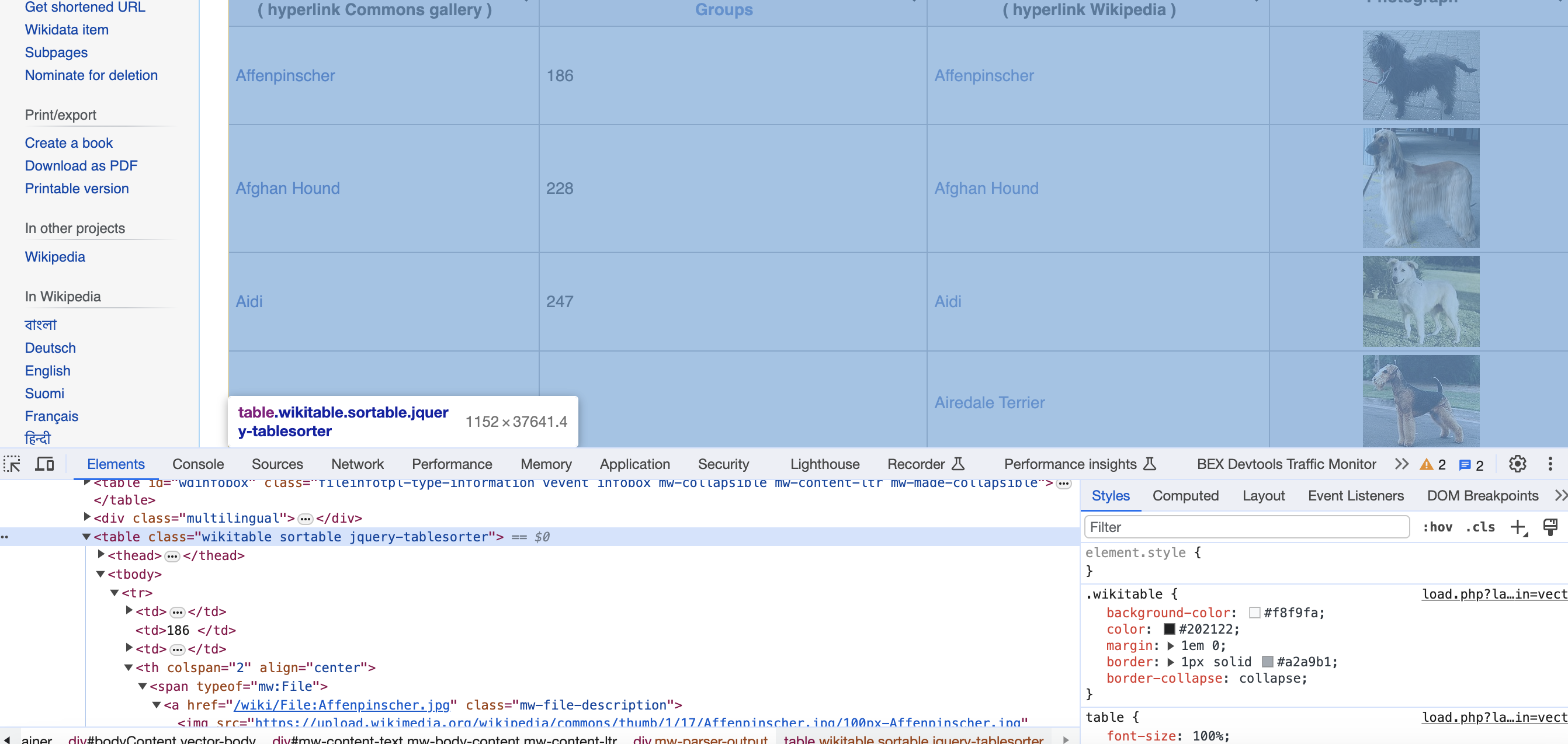
The key highlights in inspector:
This structure makes selecting the data straight forward as we'll see next.
Parsing the HTML
After downloading the page successfully, we can parse the HTML content:
if(res) {
// Parse HTML
pugi::xml_document doc;
doc.load(res->body.c_str());
auto html = doc.child("html");
}
Key points:
At this point
The Magic of CSS Selectors
One of the most powerful tools for extracting data out of HTML documents are CSS selectors. The pugixml library we use allows querying nodes using this simple yet flexible syntax.
Some examples of CSS selectors:
// By element tag
div
// By id
#container
// By class
.item
// Descendants
div span
// Direct children
div > span
We can compose these together to target nearly any elements on an HTML page.
For example, here is sample HTML:
<table class="breed-table">
<tr>
<td>Labrador</td>
<td>Sporting</td>
</tr>
</table>
And C++ code with pugixml to extract the breed name:
// Parse document
pugi::xml_document doc;
doc.load_string(html);
// Get breed name
auto breed = doc.select_node(".breed-table tr td:nth-child(1)").node().text();
The selector combination lets us directly target the text element we want to extract!
Selectors provide a concise, flexible way to query HTML. Rather than complex parsing code, we declaratively describe elements to extract. This simplicity is part of what makes scraping so accessible.
While the syntax may seem magical at first, a little knowledge goes a long way in wielding these querying powers!
Finding the table
Using selector-lib we can easily locate the table element:
// Find table
auto table = html.select_node("table.wikitable.sortable").node();
Breaking this down:
So with one line we've zeroed in on the exact table to scrape from the entire document! This is the magic of selectors in action.
Extracting all the fields
Now we can iterate the rows and use selectors to extract the data fields we want:
// Iterate rows
for (auto& row : table.select_nodes("tr")) {
// Get cells
auto cells = row.select_nodes("td, th");
// Extract data
auto name = cells[0].child("a").text().get();
auto group = cells[1].text().get();
auto localNameNode = cells[2].select_node("span");
auto localName = localNameNode.text().get("");
auto img = cells[3].select_node("img");
auto photograph = img.attribute("src").value();
// Store data
names.push_back(name);
groups.push_back(group);
localNames.push_back(localName);
photographs.push_back(photograph);
}
The key steps are:
Being able to concisely target elements and attributes is what makes selectors so useful for parsing HTML programmatically.
And that's it, by iterating the table rows and applying selectors, we've scraped structured data from the entire page. Vectors give us typed arrays to hold and work with the scraped content.
Downloading and saving the images
After extracting image urls, we can download and save the dog breed photos locally:
if (!photograph.empty()) {
auto img_data = cli.Get(photograph.c_str());
std::ofstream file("dog_images/" + name + ".jpg", std::ios::binary);
file << img_data->body;
}
Here's what it's doing:
This allows scraping both HTML text content as well as media like images or documents from a site.
And with that we've walked through the entire scraper code flow - hope this gives you a great template for building your own C++ scraping scripts!
Alternative libraries and tools for web scraping
While we used cpp-httplib, there are a few other popular options for web scraping in C++:
The underlying library powering cpp-httplib. Lower level but highly tunable for scraping needs.
C++ framework including HTTP clients, parsers and other network utilities.
A popular Python scraping framework that can be used from C++ via libscrapy bindings.
Automated browser testing framework useful for scraping dynamic JS sites.
So while cpp-httplib covered our use case, these alternatives may serve other needs better:
Evaluate options based on the type of site, data and workflow needing to be scraped.
Challenges of Web Scraping in the real world: Some tips & best practices
When taking scrapers beyond simple tutorial sites to real world scenarios at scale, some common challenges arise:
Getting blocked
Sites aim to prevent huge automated scraping due to bandwidth or usage policy reasons. Some tips:
Rotating User Agents
When scraping sites, using the same static user agent for all requests can get your scraper blocked. Sites may think you are a bot and ban your IP or user agent signature.
To properly mimic a real browser, you need to rotate between a set of common user agents. Here is C++ example code to achieve this with each HTTP request:
#include <vector>
#include <stdlib.h>
std::vector<std::string> userAgents{
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36",
"Mozilla/5.0 (iPhone; CPU iPhone OS 12_2 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148",
"Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
};
// Choose random user agent
std::string pickUserAgent() {
int index = rand() % userAgents.size();
return userAgents[index];
}
// Use with HTTP client
httplib::Client cli("example.com");
cli.set_header("User-Agent", pickUserAgent());
auto res = cli.Get("/page");
Here we store a vector of actual user agent strings and then randomly select one before each request. This helps properly mimic browsers across scrapers.
Make sure to refresh user agents frequently within long running scraping jobs for optimal scraping performance.
Some libraries like Scraper or Puppeteer also automatically handle rotating user agents so you don't need custom logic. But understanding how the process works is still useful.
Handling dynamic content
Modern sites rely heavily on Javascript to render content. Some approaches:
Conclusion
In this comprehensive guide we walked through web scraping end-to-end in C++, learning:
C++ provides performance benefits and scraping capabilities through various libraries. It offers speed for large-scale data collection and control for sophisticated workflows. With this guide, you can now build high-performance, resilient scrapers in C++ for your needs.
While these examples are great for learning, scraping production-level sites can pose challenges like CAPTCHAs, IP blocks, and bot detection. Rotating proxies and automated CAPTCHA solving can help.
Proxies API offers a simple API for rendering pages with built-in proxy rotation, CAPTCHA solving, and evasion of IP blocks. You can fetch rendered pages in any language without configuring browsers or proxies yourself.
This allows scraping at scale without headaches of IP blocks. Proxies API has a free tier to get started. Check out the API and sign up for an API key to supercharge your web scraping.
With the power of Proxies API combined with Python libraries like Beautiful Soup, you can scrape data at scale without getting blocked.