Introduction
Are you eager to dive into web scraping and unlock the treasure trove of data within Yelp business listings? This step-by-step guide is tailor-made for beginners, offering in-depth explanations and invaluable insights. We'll use Scala to extract data from Yelp, and you can apply these techniques to various other websites as well.
This is the page we are talking about
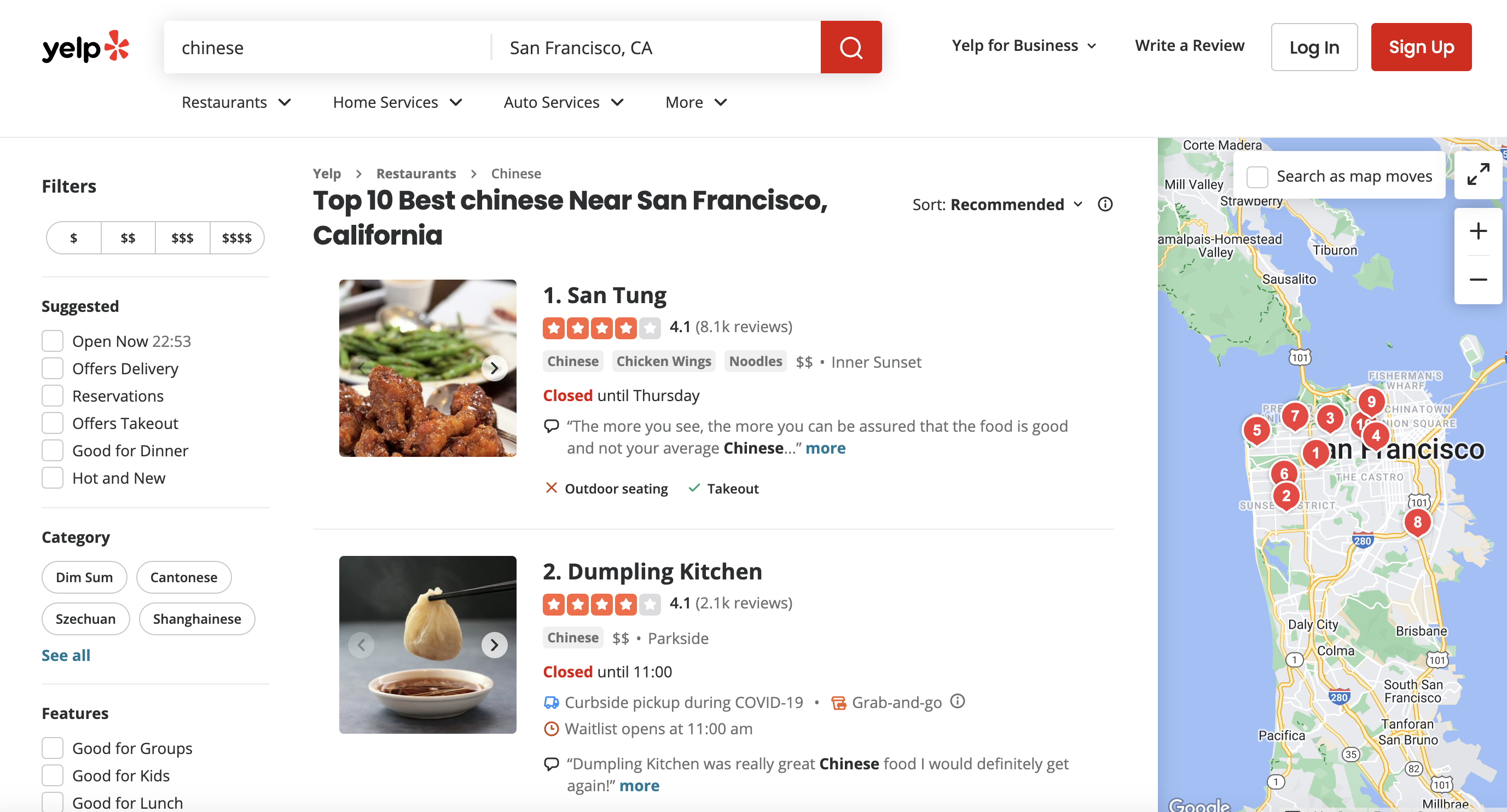
Prerequisites
Before we embark on our data extraction journey, ensure you have the following prerequisites in place:
- Scala: Make sure you have Scala installed on your system. If not, you can download it here.
- ProxiesAPI: This code employs ProxiesAPI to bypass Yelp's anti-bot measures. You'll need a premium ProxiesAPI account. Sign up here and obtain your API key.
Plan of Action
Here's our comprehensive plan to extract data from Yelp business listings:
- URL Encoding: We'll start by encoding the Yelp search URL to handle special characters properly.
- Simulate Browser Request: To avoid detection as a bot by Yelp, we'll send an HTTP GET request with simulated browser headers.
- Save HTML Content: We'll save the HTML content to a file for further analysis.
- HTML Parsing: We'll use Jsoup, a powerful HTML parsing library, to parse the HTML content.
- Data Extraction: The heart of the process – we'll extract relevant information from the HTML.
Now, let's delve into each step with detailed explanations.
Step 1: URL Encoding
The very first step is to ensure our Yelp search URL is properly encoded. This is crucial to handle special characters and format the URL correctly for use in the API request.
val url = "<https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco%2C+CA>"
val encodedUrl = java.net.URLEncoder.encode(url, "UTF-8")
Step 2: Simulating a Browser Request
Yelp employs anti-bot mechanisms, so we'll simulate a browser request by sending an HTTP GET request with headers. This is essential to avoid detection.
val headers = Map(
"User-Agent" -> "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language" -> "en-US,en;q=0.5",
"Accept-Encoding" -> "gzip, deflate, br",
"Referer" -> "<https://www.google.com/>"
)
val response = Http(apiUrl).headers(headers).option(HttpOptions.allowUnsafeSSL).asString
Step 3: Saving HTML Content
Before we proceed, we save the HTML content to a file. This step ensures we have a local copy for analysis and future reference.
val htmlContent = response.body
val outputFile = new File("yelp_html.html")
val writer = new PrintWriter(outputFile)
writer.write(htmlContent)
writer.close()
Step 4: HTML Parsing
Now, it's time to bring in Jsoup, a popular HTML parsing library. We'll parse the HTML content to make it accessible and manipulable.
val document: Document = Jsoup.parse(htmlContent)
Step 5: Data Extraction
The highlight of our journey – data extraction. This is where we unearth valuable information from the HTML content. Let's break down the process:
Inspecting the page
When we inspect the page we can see that the div has classes called arrange-unit__09f24__rqHTg arrange-unit-fill__09f24__CUubG css-1qn0b6x
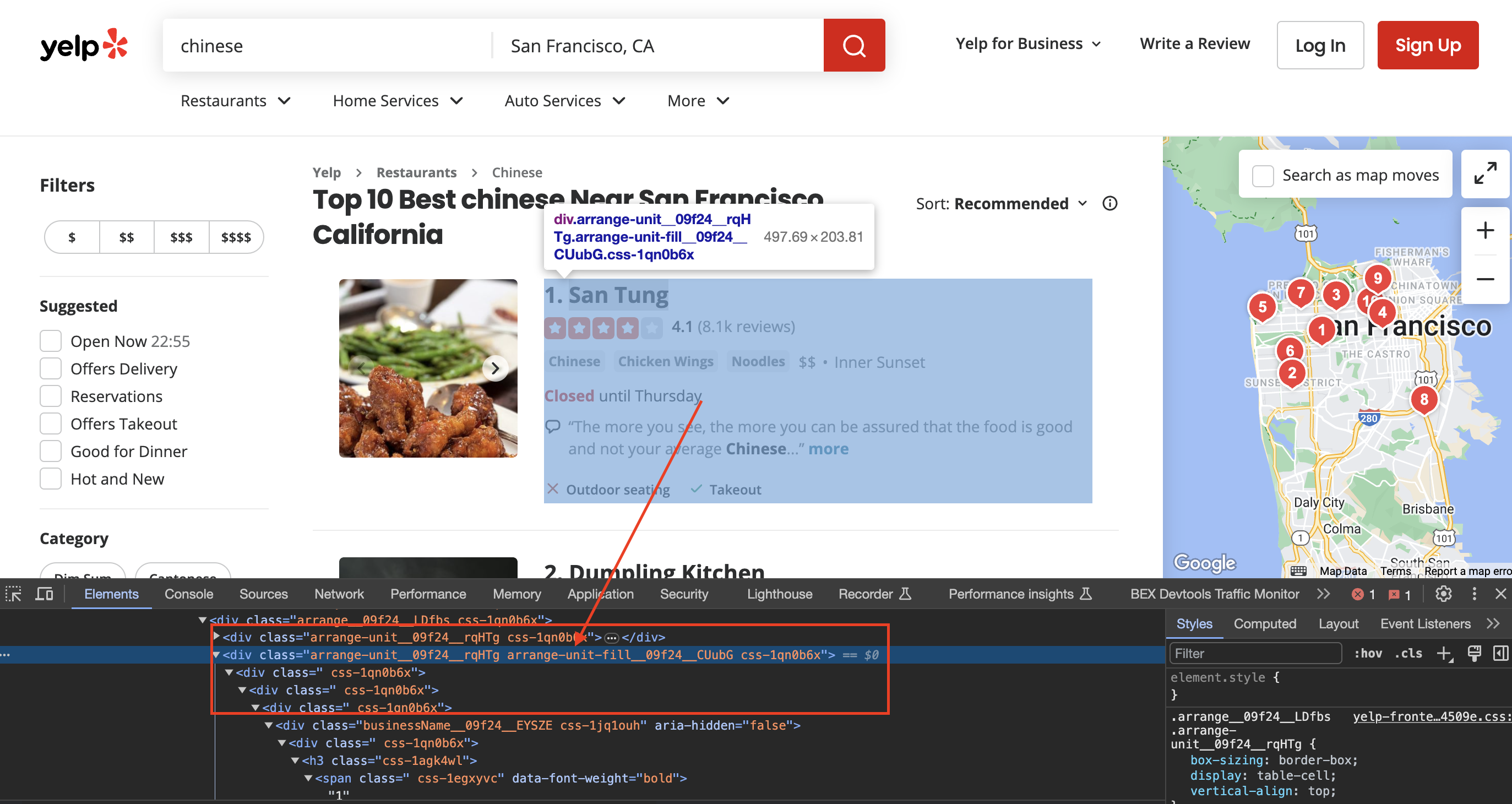
val listings: Elements = document.select("div.arrange-unit__09f24__rqHTg.arrange-unit-fill__09f24__CUubG.css-1qn0b6x")
The
For each listing, we extract details like business name, rating, number of reviews, price range, and location. Here's how:
val businessNameElem: Element = listing.selectFirst("a.css-19v1rkv")
val businessName: String = if (businessNameElem != null) businessNameElem.text() else "N/A"
val ratingElem: Element = listing.selectFirst("span.css-gutk1c")
val rating: String = if (ratingElem != null) ratingElem.text() else "N/A"
val priceRangeElem: Element = listing.selectFirst("span.priceRange__09f24__mmOuH")
val priceRange: String = if (priceRangeElem != null) priceRangeElem.text() else "N/A"
val spanElements: Elements = listing.select("span.css-chan6m")
var numReviews: String = "N/A"
var location: String = "N/A"
// Check for at least two <span> elements
if (spanElements.size() >= 2) {
numReviews = spanElements.get(0).text().trim
location = spanElements.get(1).text().trim
} else if (spanElements.size() == 1) {
// Handle cases with only one <span> element
val text: String = spanElements.get(0).text().trim
if (text.forall(_.isDigit)) {
numReviews = text
} else {
location = text
}
}
Practical Considerations and Challenges
- Premium Proxies: Premium ProxiesAPI is crucial to bypass Yelp's anti-bot mechanisms effectively. Free proxies might not work.
- Selector Clarification: Selectors can be puzzling for newcomers. In this code, we've retained the original selectors without any changes. They serve as patterns to locate specific HTML elements.
Main Takeaways
Next Steps
Having successfully extracted data from Yelp listings, you can now broaden your web scraping knowledge. Explore advanced techniques, tackle pagination, or automate data storage for more complex projects.
Always respect websites' terms of service and adhere to ethical and legal guidelines when scraping.
Here's the complete code for your reference:
import java.io.{File, PrintWriter}
import org.jsoup.Jsoup
import org.jsoup.nodes.{Document, Element}
import org.jsoup.select.Elements
import scalaj.http.{Http, HttpOptions}
object YelpScraper {
def main(args: Array[String]): Unit = {
// URL of the Yelp search page
val url = "https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco%2C+CA"
// URL-encode the URL
val encodedUrl = java.net.URLEncoder.encode(url, "UTF-8")
// API URL with the encoded Yelp URL
val apiUrl = s"http://api.proxiesapi.com/?premium=true&auth_key=YOUR_AUTH_KEY&url=$encodedUrl"
// Define headers to simulate a browser request
val headers = Map(
"User-Agent" -> "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language" -> "en-US,en;q=0.5",
"Accept-Encoding" -> "gzip, deflate, br",
"Referer" -> "https://www.google.com/"
)
// Send an HTTP GET request to the URL with the headers
val response = Http(apiUrl).headers(headers).option(HttpOptions.allowUnsafeSSL).asString
// Check if the request was successful (status code 200)
if (response.isSuccess) {
// Save the HTML content to a file
val htmlContent = response.body
val outputFile = new File("yelp_html.html")
val writer = new PrintWriter(outputFile)
writer.write(htmlContent)
writer.close()
// Parse the HTML content using Jsoup
val document: Document = Jsoup.parse(htmlContent)
// Find all the listings
val listings: Elements = document.select("div.arrange-unit__09f24__rqHTg.arrange-unit-fill__09f24__CUubG.css-1qn0b6x")
println(s"Number of Listings: ${listings.size()}")
// Loop through each listing and extract information
listings.forEach { listing: Element =>
// Assuming you've already extracted the information as shown in your code
// Check if business name exists
val businessNameElem: Element = listing.selectFirst("a.css-19v1rkv")
val businessName: String = if (businessNameElem != null) businessNameElem.text() else "N/A"
// If business name is not "N/A," then print the information
if (businessName != "N/A") {
// Check if rating exists
val ratingElem: Element = listing.selectFirst("span.css-gutk1c")
val rating: String = if (ratingElem != null) ratingElem.text() else "N/A"
// Check if price range exists
val priceRangeElem: Element = listing.selectFirst("span.priceRange__09f24__mmOuH")
val priceRange: String = if (priceRangeElem != null) priceRangeElem.text() else "N/A"
// Find all <span> elements inside the listing
val spanElements: Elements = listing.select("span.css-chan6m")
// Initialize numReviews and location as "N/A"
var numReviews: String = "N/A"
var location: String = "N/A"
// Check if there are at least two <span> elements
if (spanElements.size() >= 2) {
// The first <span> element is for Number of Reviews
numReviews = spanElements.get(0).text().trim
// The second <span> element is for Location
location = spanElements.get(1).text().trim
} else if (spanElements.size() == 1) {
// If there's only one <span> element, check if it's for Number of Reviews or Location
val text: String = spanElements.get(0).text().trim
if (text.forall(_.isDigit)) {
numReviews = text
} else {
location = text
}
}
// Print the extracted information
println(s"Business Name: $businessName")
println(s"Rating: $rating")
println(s"Number of Reviews: $numReviews")
println(s"Price Range: $priceRange")
println(s"Location: $location")
println("=" * 30)
}
}
} else {
println(s"Failed to retrieve data. Status Code: ${response.code}")
}
}
}