Web scraping is the technique of automatically extracting data from websites through code. In this article, we'll walk through a full code example of scraping business listing data from Yelp using C++ and two helpful libraries - libcurl and Gumbo.
This is the page we are talking about
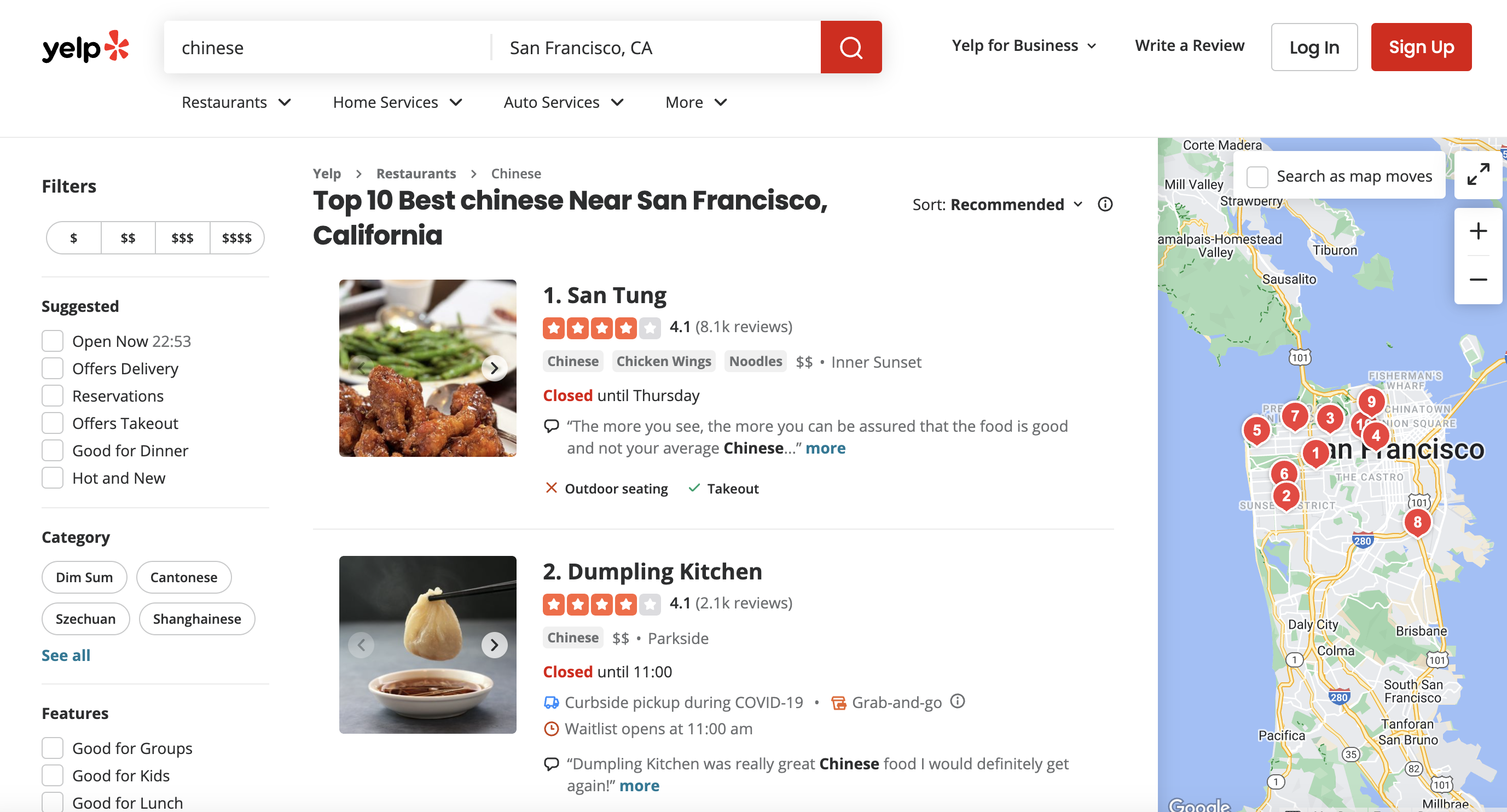
The goal is to extract key details like the business name, rating, number of reviews, price range, and location for each search result. This data could then be used for analysis, visualizations, lead generation, and more.
Why Scrape Yelp?
Yelp has rich data on local businesses across many categories like restaurants, shops, services, etc. Manually extracting this data would be tedious. Scraping allows us to extract thousands of listings programmatically. The structured data can then be used for all sorts of purposes:
Of course, check Yelp's terms and conditions before scraping. Now let's dive into the code!
Imports and Initialization
We start with including the necessary header files for I/O streams, strings, vectors, CURL, and Gumbo:
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <algorithm>
#include <curl/curl.h>
#include <gumbo.h>
Then we initialize libcurl, which handles making web requests:
CURL* curl = curl_easy_init();
if (!curl) {
std::cerr << "Failed to initialize libcurl.\\n";
return 1;
}
And that's it for setup! We'll explain Gumbo when we get to parsing.
Constructing the URLs
We need two URLs - one for the Yelp search page, and one for the ProxiesAPI service API:
// Yelp search page
std::string url = "<https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco%2C+CA>";
// Encode URL for API
std::string encoded_url = curl_easy_escape(curl, url.c_str(), url.length());
// Proxy API URL
std::string api_url = "<http://api.proxiesapi.com/?premium=true&auth_key=><key>&url=" + encoded_url;
The proxy API allows us to tunnel through proxies on each request, avoiding detection as scrapers by Yelp.
We URL-encode the Yelp URL before inserting it into the proxy API URL. This makes sure special characters pass safely.
Setting CURL Options
To mimic a real browser, we construct header strings and pass them to CURL:
struct curl_slist* headers = NULL;
headers = curl_slist_append(headers, "User-Agent: Mozilla/5.0 (...) Chrome/58.0");
headers = curl_slist_append(headers, "Accept-Language: en-US,en;q=0.5");
curl_easy_setopt(curl, CURLOPT_URL, api_url.c_str());
curl_easy_setopt(curl, CURLOPT_HTTPHEADER, headers);
The key things set here:
Without these options, Yelp may detect us as bots!
Making the Request
With CURL configured, we can make the GET request and store the response:
std::string response_data;
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
CURLcode res = curl_easy_perform(curl);
if (res != CURLE_OK) {
std::cerr << "Request failed, error: " << res;
return 1;
}
WriteCallback handles saving the response data into our string buffer. We check
At this point
Parsing the HTML
To extract structured data, we need to parse the HTML content and identify the key data elements. This is where the Gumbo parser comes in handy.
First we parse and get the root node:
GumboOutput* output = gumbo_parse(response_data.c_str());
if (!output) {
std::cerr << "Failed to parse response.";
return 1;
}
GumboNode* root = output->root;
Extracting Listing Data
The key part is identifying patterns in the HTML related to each business listing. We can then extract data for all listings:
Inspecting the page
When we inspect the page we can see that the div has classes called arrange-unit__09f24__rqHTg arrange-unit-fill__09f24__CUubG css-1qn0b6x
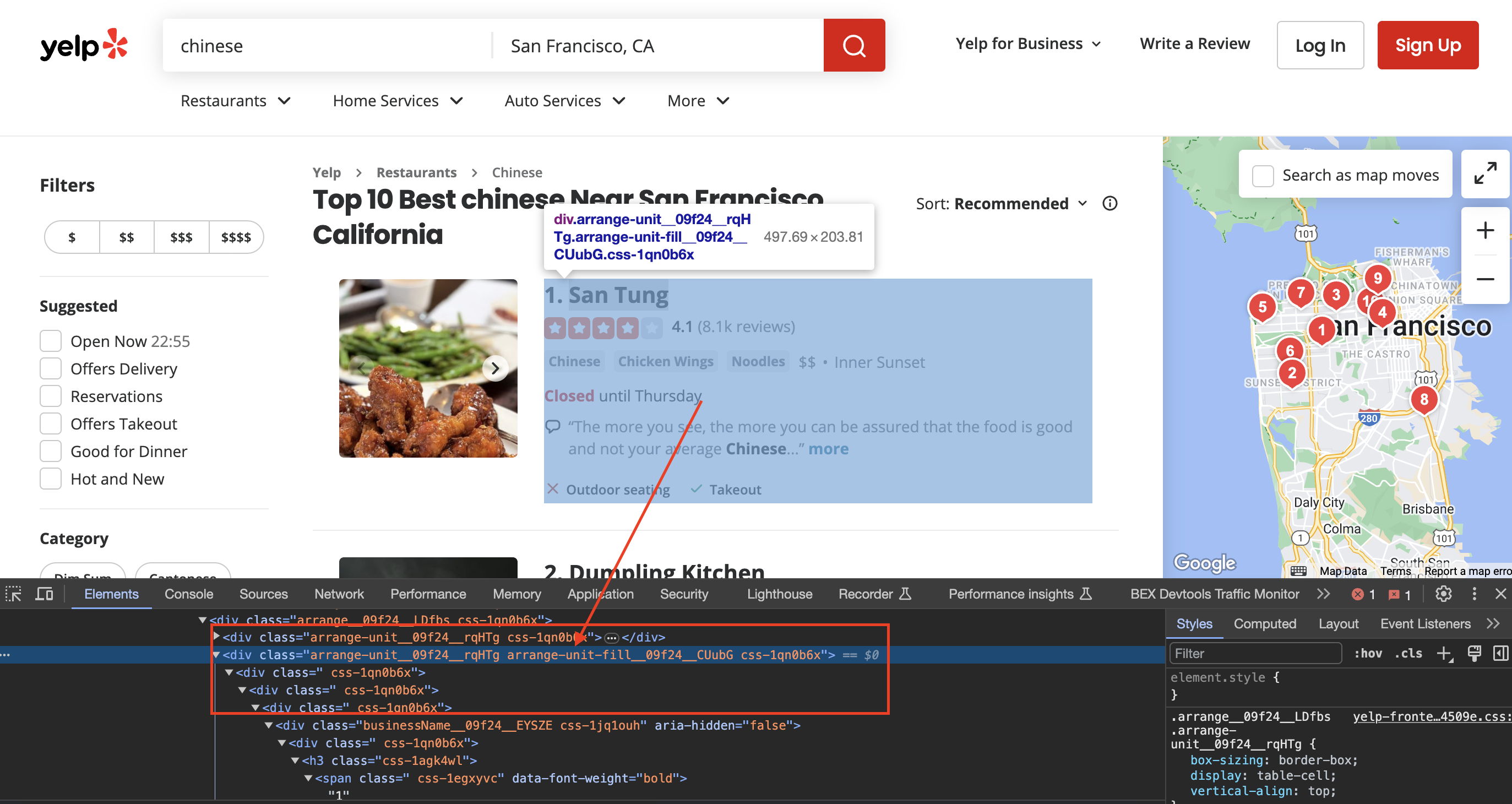
GumboAttribute* class_attr = gumbo_get_attribute(¤t->v.element.attributes, "class");
if (class_attr && std::string(class_attr->value) == "arrange-unit__09f24__rqHTg arrange-unit-fill__09f24__CUubG css-1qn0b6x") {
listings.push_back(current);
}The key things to understand:
With these patterns, we can extract any data we want from structured HTML.
The full code contains additional examples for other data points like number of reviews and price range.
Next Steps
The final code puts all the pieces together to scrape Yelp results and extract business listings.
Some ideas for building on this:
Web scraping opens up many possibilities for harnessing structured public data! Check the laws in your area and respect sites terms before scraping.
Let me know if any part of the explanation needs more detail! Here is the full code again for reference:
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <algorithm>
#include <curl/curl.h>
#include <gumbo.h>
// Function to write HTTP response data to a string
size_t WriteCallback(void* contents, size_t size, size_t nmemb, std::string* output) {
size_t total_size = size * nmemb;
output->append(static_cast<char*>(contents), total_size);
return total_size;
}
int main() {
// URL of the Yelp search page
std::string url = "https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco%2C+CA";
// Initialize libcurl
CURL* curl = curl_easy_init();
if (!curl) {
std::cerr << "Failed to initialize libcurl." << std::endl;
return 1;
}
// URL-encode the URL
std::string encoded_url = curl_easy_escape(curl, url.c_str(), url.length());
// API URL with the encoded Yelp URL
std::string api_url = "http://api.proxiesapi.com/?premium=true&auth_key=YOUR_AUTH_KEY&url=" + encoded_url;
// Define a user-agent header to simulate a browser request
struct curl_slist* headers = NULL;
headers = curl_slist_append(headers, "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36");
headers = curl_slist_append(headers, "Accept-Language: en-US,en;q=0.5");
headers = curl_slist_append(headers, "Accept-Encoding: gzip, deflate, br");
headers = curl_slist_append(headers, "Referer: https://www.google.com/");
// Configure libcurl
curl_easy_setopt(curl, CURLOPT_URL, api_url.c_str());
curl_easy_setopt(curl, CURLOPT_HTTPHEADER, headers);
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
std::string response_data;
// Send an HTTP GET request to the URL with the headers
CURLcode res = curl_easy_perform(curl);
// Check if the request was successful (status code 200)
if (res == CURLE_OK) {
// Write the response data to a file
std::ofstream file("yelp_html.html", std::ios::out | std::ios::binary);
file.write(response_data.c_str(), response_data.length());
file.close();
// Use Gumbo to parse the HTML content
GumboOutput* output = gumbo_parse(response_data.c_str());
if (output) {
GumboNode* root = output->root;
// Find all the listings
std::vector<GumboNode*> listings;
GumboNode* current = root;
while (current) {
if (current->type == GUMBO_NODE_ELEMENT && current->v.element.tag == GUMBO_TAG_DIV) {
GumboAttribute* class_attr = gumbo_get_attribute(¤t->v.element.attributes, "class");
if (class_attr && std::string(class_attr->value) == "arrange-unit__09f24__rqHTg arrange-unit-fill__09f24__CUubG css-1qn0b6x") {
listings.push_back(current);
}
}
current = current->next;
}
std::cout << "Number of Listings: " << listings.size() << std::endl;
// Loop through each listing and extract information
for (GumboNode* listing : listings) {
// Initialize variables to store extracted information
std::string business_name = "N/A";
std::string rating = "N/A";
std::string num_reviews = "N/A";
std::string price_range = "N/A";
std::string location = "N/A";
// Find the business name element
GumboNode* business_name_elem = nullptr;
current = listing->v.element.children.data;
while (current) {
if (current->type == GUMBO_NODE_ELEMENT) {
GumboAttribute* class_attr = gumbo_get_attribute(¤t->v.element.attributes, "class");
if (class_attr && std::string(class_attr->value) == "css-19v1rkv") {
business_name_elem = current;
break;
}
}
current = current->next;
}
// Extract business name if found
if (business_name_elem) {
business_name = business_name_elem->v.text.text;
}
// Find the rating element
GumboNode* rating_elem = nullptr;
current = listing->v.element.children.data;
while (current) {
if (current->type == GUMBO_NODE_ELEMENT) {
GumboAttribute* class_attr = gumbo_get_attribute(¤t->v.element.attributes, "class");
if (class_attr && std::string(class_attr->value) == "css-gutk1c") {
rating_elem = current;
break;
}
}
current = current->next;
}
// Extract rating if found
if (rating_elem) {
rating = rating_elem->v.text.text;
}
// Find the span elements for number of reviews and location
current = listing->v.element.children.data;
while (current) {
if (current->type == GUMBO_NODE_ELEMENT) {
GumboAttribute* class_attr = gumbo_get_attribute(¤t->v.element.attributes, "class");
if (class_attr && std::string(class_attr->value) == "css-chan6m") {
if (current->v.element.children.length > 0 && current->v.element.children.data->type == GUMBO_NODE_TEXT) {
std::string text = current->v.element.children.data->v.text.text;
if (num_reviews == "N/A" && std::isdigit(text[0])) {
num_reviews = text;
} else {
location = text;
}
}
}
}
current = current->next;
}
// Find the price range element
GumboNode* price_range_elem = nullptr;
current = listing->v.element.children.data;
while (current) {
if (current->type == GUMBO_NODE_ELEMENT) {
GumboAttribute* class_attr = gumbo_get_attribute(¤t->v.element.attributes, "class");
if (class_attr && std::string(class_attr->value) == "priceRange__09f24__mmOuH") {
price_range_elem = current;
break;
}
}
current = current->next;
}
// Extract price range if found
if (price_range_elem) {
price_range = price_range_elem->v.text.text;
}
// Print the extracted information
std::cout << "Business Name: " << business_name << std::endl;
std::cout << "Rating: " << rating << std::endl;
std::cout << "Number of Reviews: " << num_reviews << std::endl;
std::cout << "Price Range: " << price_range << std::endl;
std::cout << "Location: " << location << std::endl;
std::cout << "=============================" << std::endl;
}
// Clean up Gumbo
gumbo_destroy_output(&kGumboDefaultOptions, output);
}
} else {
std::cerr << "Failed to retrieve data. Status Code: " << res << std::endl;
}
// Clean up libcurl
curl_easy_cleanup(curl);
curl_slist_free_all(headers);
return 0;
}