Step 1: Introduction
Imagine you're researching the best Chinese restaurants in San Francisco, and you want to gather data from Yelp to make an informed decision. Web scraping can be your secret weapon in this quest. In this article, we'll walk through the process of scraping Yelp business listings step by step.
This is the page we are talking about
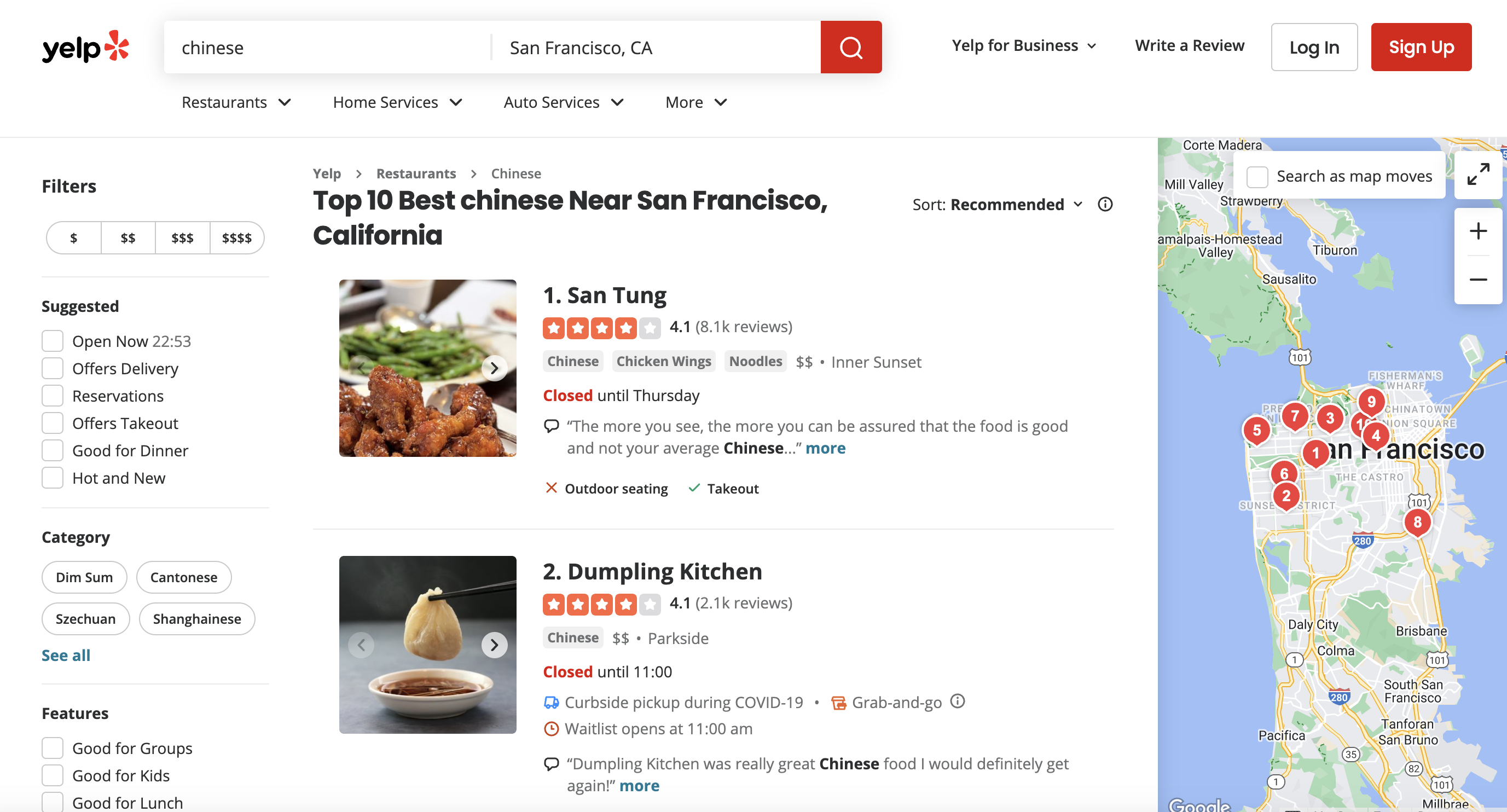
We'll be using Ruby and Nokogiri, powerful tools for web scraping. So, if you're a beginner in web scraping, don't worry; we've got you covered.
Step 2: Set Up the Environment
Before we dive into the code, you'll need to make sure you have Ruby installed on your system. If you haven't already, head over to the official Ruby website (https://www.ruby-lang.org/en/documentation/installation/) to download and install Ruby.
Additionally, we'll be using some Ruby gems (libraries) to help us with web scraping. Open your terminal and run the following commands to install them:
gem install net-http
gem install nokogiri
Now, create a new Ruby script file in your preferred code editor and name it something like
Step 3: Import Necessary Libraries
In our Ruby script, we'll start by importing the necessary libraries. Here's what each library does:
Now, let's move on to the next step.
Step 4: Define the Yelp Search URL
Our first task is to define the URL of the Yelp search page we want to scrape. In our case, we're searching for Chinese restaurants in San Francisco, so our URL looks like this:
url = "<https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco%2C+CA>"
But before we proceed, we need to URL-encode this URL to ensure it's correctly formatted for use in our code. To do this, we'll use the
encoded_url = URI.escape(url, /[:?&=]/)
Now, let's move on to the next step where we'll handle premium proxies to bypass Yelp's anti-bot mechanisms.
Step 5: Generate the API URL with Premium Proxies
Here's where things get interesting. Yelp, like many websites, has defenses against web scraping. To circumvent these measures and ensure uninterrupted scraping, we'll use premium proxies.
In our code, we construct an
api_url = "<http://api.proxiesapi.com/?premium=true&auth_key=YOUR_AUTH_KEY&url=#{encoded_url}>"
Make sure to replace
Step 6: Set Up Request Headers
Before we make the request to Yelp, we need to simulate a browser request. This is essential to avoid being flagged as a bot. To do this, we define a
headers = {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language" =>
"en-US,en;q=0.5",
"Accept-Encoding" => "gzip, deflate, br",
"Referer" => "<https://www.google.com/>", # Simulate a referrer
}
These headers make your requests look more like they're coming from a real web browser.
Step 7: Send an HTTP GET Request
With our URL, premium proxies, and headers in place, it's time to send an HTTP GET request to the Yelp search page. We use the
uri = URI.parse(api_url)
http = Net::HTTP.new(uri.host, uri.port)
http.use_ssl = true if uri.scheme == 'https'
request = Net::HTTP::Get.new(uri.request_uri, headers)
response = http.request(request)
We'll also check if the request was successful by examining the response status code.
Step 8: Save the HTML Response
Now that we've made a successful request, we need to save the HTML response to a file for further analysis. In our code, we create a file named
File.open("yelp_html.html", "w", encoding: "utf-8") do |file|
file.write(response.body)
end
It's important to preserve the data as it is for accuracy and future reference.
Step 9: Parsing HTML with Nokogiri
With the Yelp HTML data saved, we can move on to parsing it with Nokogiri. Nokogiri will help us navigate the HTML structure and extract the information we need.
doc = Nokogiri::HTML(response.body)
Now, let's tackle the next step: extracting business information.
Step 10: Extract Business Information
Our goal is to extract details like the business name, rating, number of reviews, price range, and location for each listing on the Yelp page. Let's walk through this step by step.
Inspecting the page
When we inspect the page we can see that the div has classes called arrange-unit__09f24__rqHTg arrange-unit-fill__09f24__CUubG css-1qn0b6x
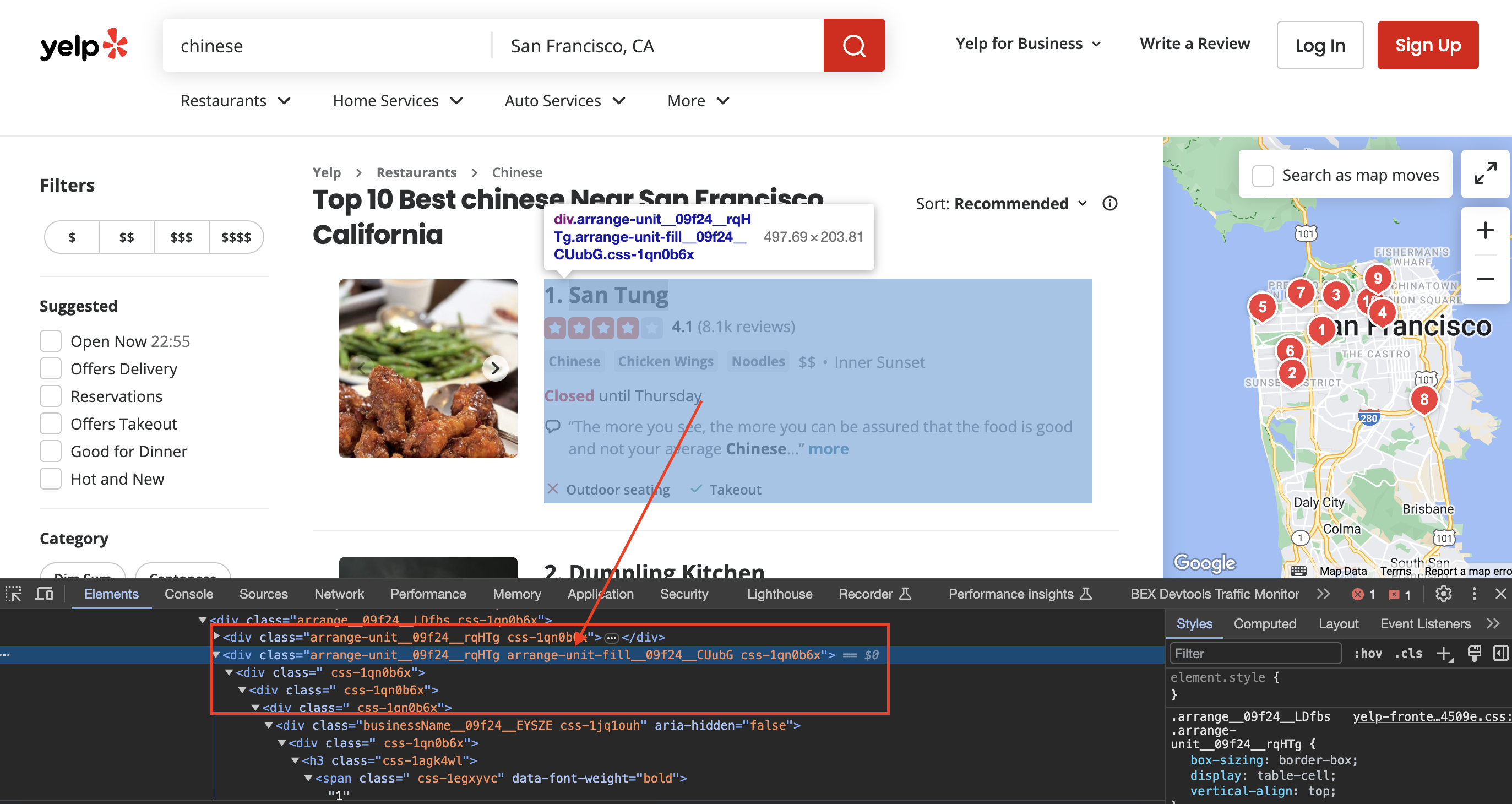
Inside our code, we find all the listings using CSS selectors:
listings = doc.css('div.arrange-unit__09f24__rqHTg.arrange-unit-fill__09f24__CUubG.css-1qn0b6x')
These CSS classes are specific to Yelp's HTML structure and may change over time, so make sure they match the current structure.
Now, we loop through each listing and extract information. We'll assume you've already extracted the information as shown in the original code. Here's a detailed breakdown of each extraction:
business_name_elem = listing.at_css('a.css-19v1rkv')
business_name = business_name_elem ? business_name_elem.text : "N/A"
rating_elem = listing.at_css('span.css-gutk1c')
rating = rating_elem ? rating_elem.text : "N/A"
price_range_elem = listing.at_css('span.priceRange__09f24__mmOuH')
price_range = price_range_elem ? price_range_elem.text : "N/A"
span_elements = listing.css('span.css-chan6m')
num_reviews = "N/A"
location = "N/A"
if span_elements.length >= 2
num_reviews = span_elements[0].text.strip
location = span_elements[1].text.strip
elsif span_elements.length == 1
text = span_elements[0].text.strip
if text.match?(/^\\d+$/)
num_reviews = text
else
location = text
end
end
Now that we've successfully extracted the business information, it's time to move to the next step: printing this information.
Step 11: Printing Extracted Information
For each business listing, we print the extracted information using the
puts "Business Name: #{business_name}"
puts "Rating: #{rating}"
puts "Number of Reviews: #{num_reviews}"
puts "Price Range: #{price_range}"
puts "Location: #{location}"
puts "=" * 30
This code ensures that the extracted data is presented clearly.
Step 12: Error Handling
While we've covered a lot of ground, it's crucial to handle potential errors gracefully. In case the request to Yelp fails, we check the response status code and print an error message.
if response.code.to_i == 200
# Continue with data extraction and printing
else
puts "Failed to retrieve data. Status Code: #{response.code}"
end
This ensures that if something goes wrong, you'll know about it.
Step 13: Conclusion and Next Steps
Congratulations! You've successfully scraped Yelp business listings using Ruby and Nokogiri while bypassing Yelp's anti-bot mechanisms with premium proxies. Here are some key takeaways from our journey:
Now that you have the data, you can use it for various purposes, such as data analysis, visualization, or simply making an informed decision about where to enjoy some delicious Chinese cuisine in San Francisco.
Full Code:
require 'net/http'
require 'uri'
require 'nokogiri'
# URL of the Yelp search page
url = "https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco%2C+CA"
# URL-encode the URL
encoded_url = URI.escape(url, /[:?&=]/)
# API URL with the encoded Yelp URL
api_url = "http://api.proxiesapi.com/?premium=true&auth_key=YOUR_AUTH_KEY&url=#{encoded_url}"
# Define a user-agent header to simulate a browser request
headers = {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language" => "en-US,en;q=0.5",
"Accept-Encoding" => "gzip, deflate, br",
"Referer" => "https://www.google.com/", # Simulate a referrer
}
# Send an HTTP GET request to the URL with the headers
uri = URI.parse(api_url)
http = Net::HTTP.new(uri.host, uri.port)
http.use_ssl = true if uri.scheme == 'https'
request = Net::HTTP::Get.new(uri.request_uri, headers)
response = http.request(request)
File.open("yelp_html.html", "w", encoding: "utf-8") do |file|
file.write(response.body)
end
# Check if the request was successful (status code 200)
if response.code.to_i == 200
# Parse the HTML content of the page using Nokogiri
doc = Nokogiri::HTML(response.body)
# Find all the listings
listings = doc.css('div.arrange-unit__09f24__rqHTg.arrange-unit-fill__09f24__CUubG.css-1qn0b6x')
puts listings.length
# Loop through each listing and extract information
listings.each do |listing|
# Assuming you've already extracted the information as shown in your code
# Check if business name exists
business_name_elem = listing.at_css('a.css-19v1rkv')
business_name = business_name_elem ? business_name_elem.text : "N/A"
# If business name is not "N/A," then print the information
if business_name != "N/A"
# Check if rating exists
rating_elem = listing.at_css('span.css-gutk1c')
rating = rating_elem ? rating_elem.text : "N/A"
# Check if price range exists
price_range_elem = listing.at_css('span.priceRange__09f24__mmOuH')
price_range = price_range_elem ? price_range_elem.text : "N/A"
# Find all <span> elements inside the listing
span_elements = listing.css('span.css-chan6m')
# Initialize num_reviews and location as "N/A"
num_reviews = "N/A"
location = "N/A"
# Check if there are at least two <span> elements
if span_elements.length >= 2
# The first <span> element is for Number of Reviews
num_reviews = span_elements[0].text.strip
# The second <span> element is for Location
location = span_elements[1].text.strip
elsif span_elements.length == 1
# If there's only one <span> element, check if it's for Number of Reviews or Location
text = span_elements[0].text.strip
if text.match?(/^\d+$/)
num_reviews = text
else
location = text
end
end
# Print the extracted information
puts "Business Name: #{business_name}"
puts "Rating: #{rating}"
puts "Number of Reviews: #{num_reviews}"
puts "Price Range: #{price_range}"
puts "Location: #{location}"
puts "=" * 30
end
end
else
puts "Failed to retrieve data. Status Code: #{response.code}"
end