Web scraping can be an extremely useful technique for gathering and analyzing data from websites. However, many sites like Yelp have anti-scraping mechanisms in place to prevent automation. This is where using premium proxies comes in handy.
Proxies act as an intermediary between your computer and the target site, masking your identity and evading bot detection. Premium proxies are fast, reliable pools of IP addresses that imitate real organic users. By routing requests through them, we can bypass restrictions and scrape data at scale.
In this tutorial, we'll walk through a full web scraping script for extracting key details on Yelp listings, with proxies enabled for stability. We'll go line-by-line to ensure you understand exactly what's happening behind the scenes.
This is the page we are talking about
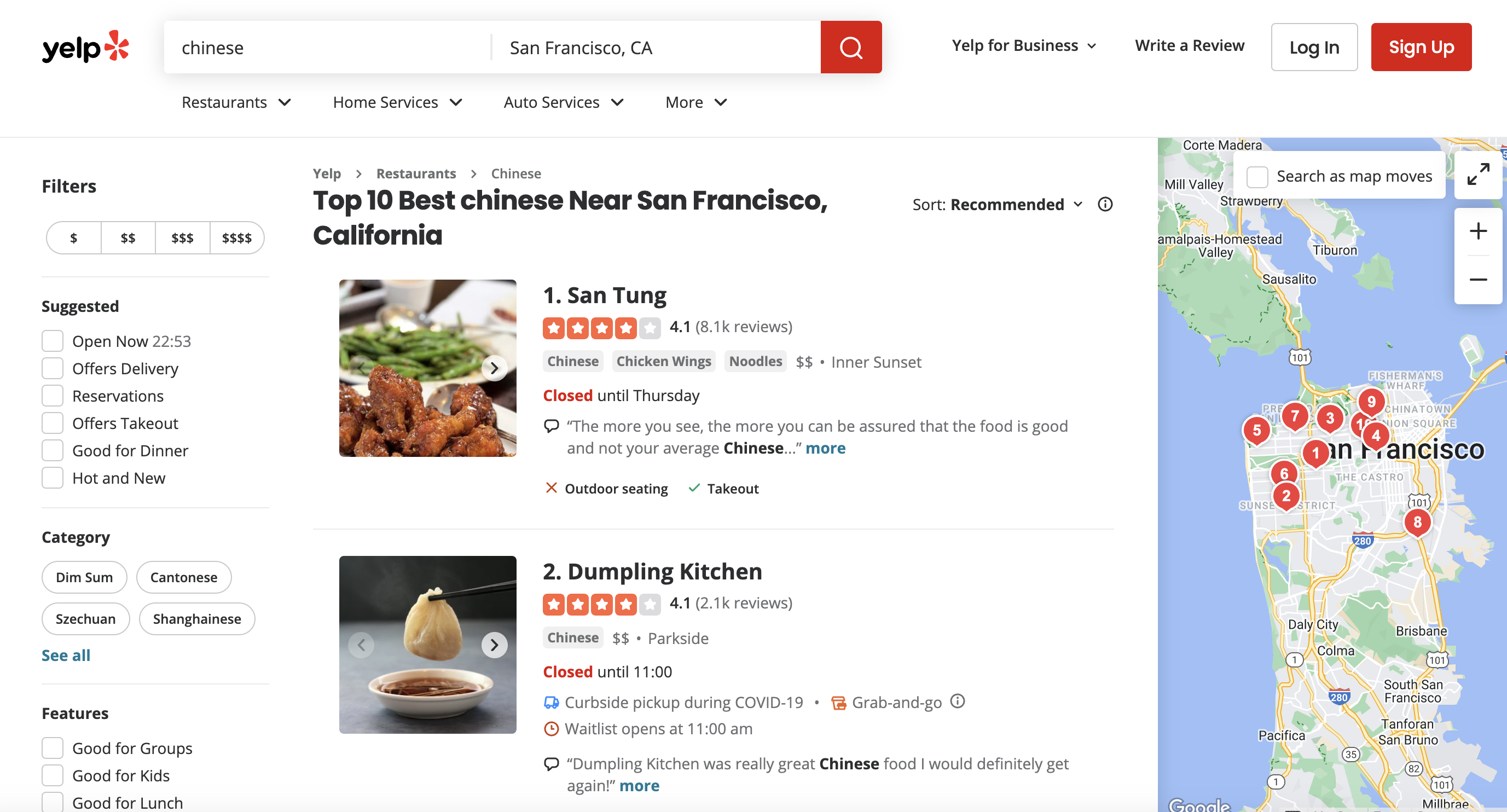
I know when I first started out, selectors were the most confusing part - so we'll take extra care there. Whether you ultimately want to analyze trends across top-rated Chinese restaurants or collect pricing info to improve your own menu, this script has you covered!
Setting up the Tools
We'll use R and two handy libraries - httr for sending HTTP requests, and rvest for parsing the HTML response to extract data.
Run the first two lines to import these:
library(httr)
library(rvest)
Make sure you have them installed. If not, a quick
Constructing the Target URL
Now, we define our Yelp search URL to target. Let's go after Chinese restaurants in San Francisco.
url <- "<https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco%2C+CA>"
Easy enough! find_desc filters by category, and find_loc specifies the location.
Encoding the URL
Here's an insider trick - we URL-encode this to handle any special characters:
encoded_url <- URLencode(url, reserved = TRUE)
This formats the URL properly for sending off to the proxy service next.
Setting up the Proxy API Request
ProxiesAPI offers a handy premium proxy API with fast residential IPs to evade bot checks. We'll append our encoded target url to their endpoint:
api_url <- paste0("<http://api.proxiesapi.com/?premium=true&auth_key=YOUR_AUTH_KEY&url=>", encoded_url)
Remember to add your own auth_key so the request goes through!
Configuring the HTTP Request Headers
To really mimic a true browser visit, we can modify the HTTP request headers:
headers <- c(
"User-Agent" = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language" = "en-US,en;q=0.5",
"Accept-Encoding" = "gzip, deflate, br",
"Referer" = "<https://www.google.com/>"
)
This fakes a Chrome browser on Windows, with English language preference, gzip compression enabled, and a Google referer. The more real we seem, the better chance of avoiding blocks!
Sending the Request and Parsing the HTML
Now we can fire off the GET request through ProxiesAPI and parse the HTML response:
response <- httr::GET(api_url, httr::add_headers(.headers = headers))
if (httr::status_code(response) == 200) {
soup <- read_html(httr::content(response, "text"))
}
A status code of 200 means success. We pass the HTML content to rvest's read_html parser to create a soup object for scraping.
Extracting Listing Data with Selectors
Inspecting the page
When we inspect the page we can see that the div has classes called arrange-unit__09f24__rqHTg arrange-unit-fill__09f24__CUubG css-1qn0b6x
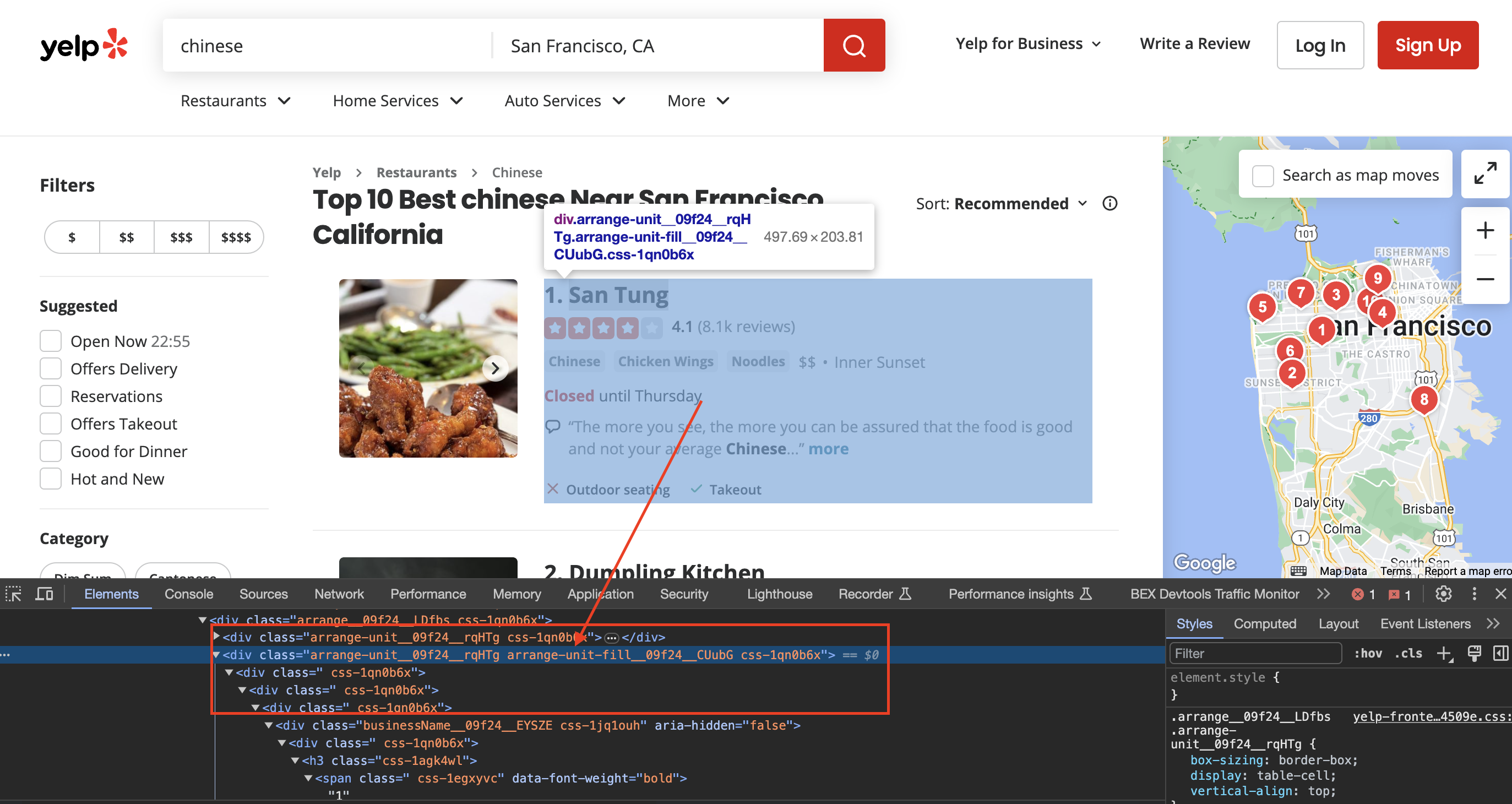
Now's when the real magic happens! We use CSS selectors to pinpoint elements and extract listing details one-by-one:
We first grab all the individual listings on the search page using this long selector:
listings <- soup %>% html_nodes(".arrange-unit__09f24__rqHTg.arrange-unit-fill__09f24__CUubG.css-1qn0b6x")
Breaking it down:
Together, these classes uniquely identify the components we want.
We store all those listing divs in
Next, for each individual listing, we extract data elements by their own classes:
for (listing in listings) {
business_name_elem <- listing %>% html_node(".css-19v1rkv")
business_name <- html_text(business_name_elem)
}
Some listings have extra elements like ratings and review counts. We handle those cases by first checking if the element exists before extracting:
We locate all the tags within each listing first:
Copy codespan_elements <- listing %>% html_nodes(".css-chan6m")
The
Now we need to figure out which holds what data. Some listings have 2 spans, some only 1.
So we check:
Copy codeif (length(span_elements) >= 2) {
# First span is reviews
# Second is location
} else if (length(span_elements) == 1) {
# Could be either reviews or location
}
If there are 2 spans:
We extract and save accordingly:
Copy codenum_reviews <- html_text(span_elements[1])
location <- html_text(span_elements[2])
If only 1 span, we have to programmatically determine if it is reviews or location.
We grab the text, then use a regular expression to test if it's a number (indicating reviews):
Copy codetext <- html_text(span_elements[1])
if (grepl("^\\d+$", text)) {
num_reviews <- text
} else {
location <- text
}
This shows the importance of handling edge cases and missing data properly when scraping! Let me know if you have any other specific questions.
The key is finding unique CSS classes or ids on the page that point to the data you want. This takes some trial-and-error - use browser Dev Tools to inspect elements and tweak selectors until you pinpoint the right tags.
Handling Paginated Results
One challenge is Yelp displays listings across multiple pages. To scrape them all, we'd need to:
- Check for a "Next" link and click until last page
- Concatenate all page results into one final data set
- Remove any duplicates before analyzing
Pagination can get tricky - we won't implement it here but just be aware!
Full Code
Below is the complete R script to scrape Yelp listings with proxies enabled.
You should be able to simply plug in your ProxiesAPI key and run it successfully! Try tweaking the search query or selectors to adapt it.
library(httr)
library(rvest)
# URL of the Yelp search page
url <- "https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco%2C+CA"
# URL-encode the URL
encoded_url <- URLencode(url, reserved = TRUE)
# API URL with the encoded URL
api_url <- paste0("http://api.proxiesapi.com/?premium=true&auth_key=YOUR_AUTH_KEY&url=", encoded_url)
# Define a user-agent header to simulate a browser request
headers <- c(
"User-Agent" = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language" = "en-US,en;q=0.5",
"Accept-Encoding" = "gzip, deflate, br",
"Referer" = "https://www.google.com/" # Simulate a referrer
)
# Send an HTTP GET request to the URL with the headers
response <- httr::GET(api_url, httr::add_headers(.headers = headers))
# Check if the request was successful (status code 200)
if (httr::status_code(response) == 200) {
# Parse the HTML content of the page using rvest
soup <- read_html(httr::content(response, "text"))
# Find all the listings
listings <- soup %>% html_nodes(".arrange-unit__09f24__rqHTg.arrange-unit-fill__09f24__CUubG.css-1qn0b6x")
print(length(listings))
# Loop through each listing and extract information
for (listing in listings) {
# Assuming you've already extracted the information as shown in your code
# Check if business name exists
business_name_elem <- listing %>% html_node(".css-19v1rkv")
business_name <- ifelse(!is.null(business_name_elem), html_text(business_name_elem), "N/A")
# If business name is not "N/A," then print the information
if (business_name != "N/A") {
# Check if rating exists
rating_elem <- listing %>% html_node(".css-gutk1c")
rating <- ifelse(!is.null(rating_elem), html_text(rating_elem), "N/A")
# Check if price range exists
price_range_elem <- listing %>% html_node(".priceRange__09f24__mmOuH")
price_range <- ifelse(!is.null(price_range_elem), html_text(price_range_elem), "N/A")
# Find all <span> elements inside the listing
span_elements <- listing %>% html_nodes(".css-chan6m")
# Initialize num_reviews and location as "N/A"
num_reviews <- "N/A"
location <- "N/A"
# Check if there are at least two <span> elements
if (length(span_elements) >= 2) {
# The first <span> element is for Number of Reviews
num_reviews <- trimws(html_text(span_elements[1]))
# The second <span> element is for Location
location <- trimws(html_text(span_elements[2]))
} else if (length(span_elements) == 1) {
# If there's only one <span> element, check if it's for Number of Reviews or Location
text <- trimws(html_text(span_elements[1]))
if (grepl("^\\d+$", text)) {
num_reviews <- text
} else {
location <- text
}
}
# Print the extracted information
cat("Business Name:", business_name, "\n")
cat("Rating:", rating, "\n")
cat("Number of Reviews:", num_reviews, "\n")
cat("Price Range:", price_range, "\n")
cat("Location:", location, "\n")
cat("==================================\n")
}
}
} else {
cat(paste("Failed to retrieve data. Status Code:", httr::status_code(response), "\n"))
}There you have it - a battle-tested Yelp scraper complete with proxy workaround ready for your analytics needs! As a next step, look into storing the extracted data into databases or CSVs.