In this article, we'll be walking through code that scrapes Reddit to extract information about posts. We'll go step-by-step to understand what's happening behind the scenes.
here is the page we are talking about
Prerequisites
To follow along, you'll need:
To install Rust, follow the instructions here.
The reqwest and select crates handle making web requests and HTML parsing respectively. To add them, run:
$ cargo add reqwest
$ cargo add select
With those done, you're all set! Let's get scraping.
Walkthrough
We first import the crates and types we need:
extern crate reqwest;
extern crate select;
use reqwest::header;
use select::document::Document;
use select::node::Node;
Then we define the target URL and User-Agent string:
let reddit_url = "<https://www.reddit.com>";
let user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36";
The user agent helps make requests look like they're coming from a real browser.
Next, we create a reqwest client with that user agent:
let client = reqwest::blocking::Client::builder()
.user_agent(user_agent)
.build()?;
We use a blocking client for simplicity here.
Then we send a GET request to the Reddit URL:
let response = client.get(reddit_url).send()?;
We check if it was successful (200 status code):
if response.status().is_success() {
// ...
}
Inside the if statement is the scraping logic.
First we get the HTML content as a string:
let html_content = response.text()?;
We save it to a file:
let filename = "reddit_page.html";
std::fs::write(filename, &html_content)?;
Then we parse the HTML into a document using Select:
let document = Document::from_read(html_content.as_bytes()).unwrap();
Inspecting the elements
Upon inspecting the HTML in Chrome, you will see that each of the posts have a particular element shreddit-post and class descriptors specific to them…
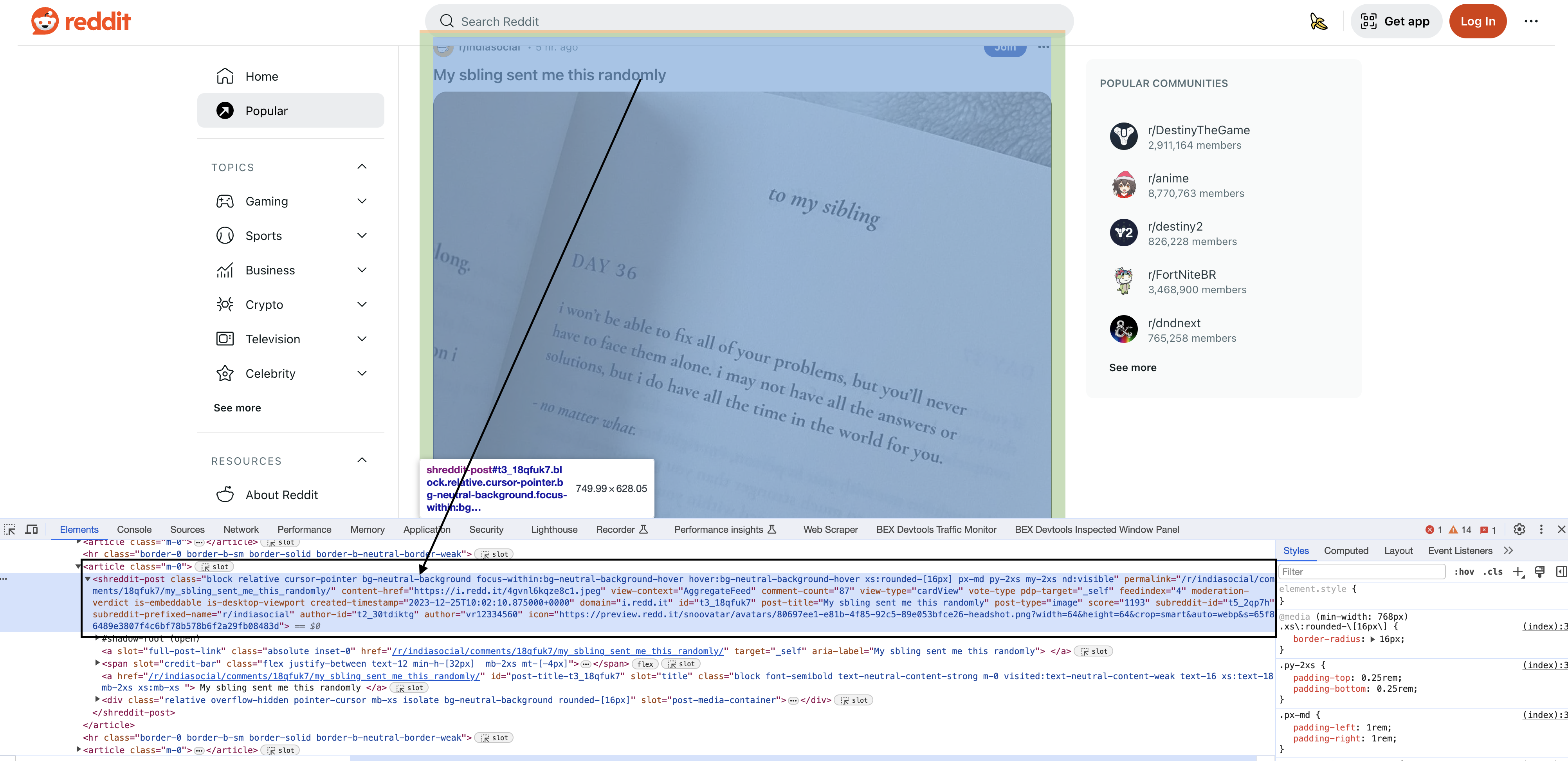
This is where things get interesting! We find all posts with:
for node in document.find(Name("shreddit-post").and(Class("block relative cursor-pointer bg-neutral-background focus-within:bg-neutral-background-hover hover:bg-neutral-background-hover xs:rounded-[16px] p-md my-2xs nd:visible"))) {
}
This selector searches for elements with:
The key thing is that it finds Reddit post blocks.
Inside the loop, we extract post data by chaining more Select calls:
Permalink
let permalink = node.attr("permalink").unwrap_or("");
Gets the
Content URL
let content_href = node.attr("content-href").unwrap_or("");
Gets
Comment Count
let comment_count = node.attr("comment-count").unwrap_or("");
Gets
Post Title
let post_title = node.find(Name("div").and(Attr("slot", "title"))).next().unwrap().text();
Finds the title
Author
let author = node.attr("author").unwrap_or("");
Gets
Score
let score = node.attr("score").unwrap_or("");
Gets
Finally, we print out all extracted fields!
The key things to note are:
And that's it! Full code:
extern crate reqwest;
extern crate select;
use reqwest::header;
use select::document::Document;
use select::node::Node;
fn main() -> Result<(), reqwest::Error> {
// Define the Reddit URL you want to download
let reddit_url = "https://www.reddit.com";
// Define a User-Agent header
let user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36";
// Create a reqwest client with the User-Agent header
let client = reqwest::blocking::Client::builder()
.user_agent(user_agent)
.build()?;
// Send a GET request to the URL
let response = client.get(reddit_url).send()?;
// Check if the request was successful (status code 200)
if response.status().is_success() {
// Get the HTML content of the page as a string
let html_content = response.text()?;
// Specify the filename to save the HTML content
let filename = "reddit_page.html";
// Save the HTML content to a file
std::fs::write(filename, &html_content)?;
println!("Reddit page saved to {}", filename);
// Parse the HTML content
let document = Document::from_read(html_content.as_bytes()).unwrap();
// Find all blocks with the specified tag and class
for node in document.find(Name("shreddit-post").and(Class("block relative cursor-pointer bg-neutral-background focus-within:bg-neutral-background-hover hover:bg-neutral-background-hover xs:rounded-[16px] p-md my-2xs nd:visible"))) {
let permalink = node.attr("permalink").unwrap_or("");
let content_href = node.attr("content-href").unwrap_or("");
let comment_count = node.attr("comment-count").unwrap_or("");
let post_title = node.find(Name("div").and(Attr("slot", "title"))).next().unwrap().text();
let author = node.attr("author").unwrap_or("");
let score = node.attr("score").unwrap_or("");
// Print the extracted information for each block
println!("Permalink: {}", permalink);
println!("Content Href: {}", content_href);
println!("Comment Count: {}", comment_count);
println!("Post Title: {}", post_title);
println!("Author: {}", author);
println!("Score: {}", score);
println!("\n");
}
} else {
println!("Failed to download Reddit page (status code {})", response.status());
}
Ok(())
}