In this article, we'll walk through a Ruby script that scrapes various data from Reddit posts.
Some common use cases for web scraping Reddit include:
While scraping does have some ethical considerations (which we won't get into here), it can be a useful skill for programmers to acquire.
here is the page we are talking about
So let's jump right into the code!
Setting Up
We'll be using the
gem install open-uri
gem install nokogiri
The
Okay, with the dependencies handled, let's start going through the script:
Defining Constants
First we set some constant values that will be reused throughout the program:
reddit_url = "<https://www.reddit.com>"
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
Browser user agent strings identify what type of browser is making the request. Spoofing a common desktop user agent helps avoid bot detection.
Making the Initial Request
Next, we use the handy
begin
html_content = URI.open(reddit_url, "User-Agent" => user_agent).read
rescue OpenURI::HTTPError => e
# error handling
end
Breaking this down:
At this point
Saving the HTML
Next we write the HTML content to a local file:
filename = "reddit_page.html"
File.open(filename, "w:UTF-8") do |file|
file.write(html_content)
end
puts "Reddit page saved to #{filename}"
Here we:
Saving the HTML locally allows us to scrape the content multiple times without needing to re-download.
Parsing the HTML with Nokogiri
Now we have the Reddit homepage HTML saved locally, and can parse it using the Nokogiri gem:
doc = Nokogiri::HTML(html_content)
Nokogiri gives us very powerful selectors to extract the exact pieces of information we want.
Extracting Reddit Posts
Inspecting the elements
Upon inspecting the HTML in Chrome, you will see that each of the posts have a particular element shreddit-post and class descriptors specific to them…
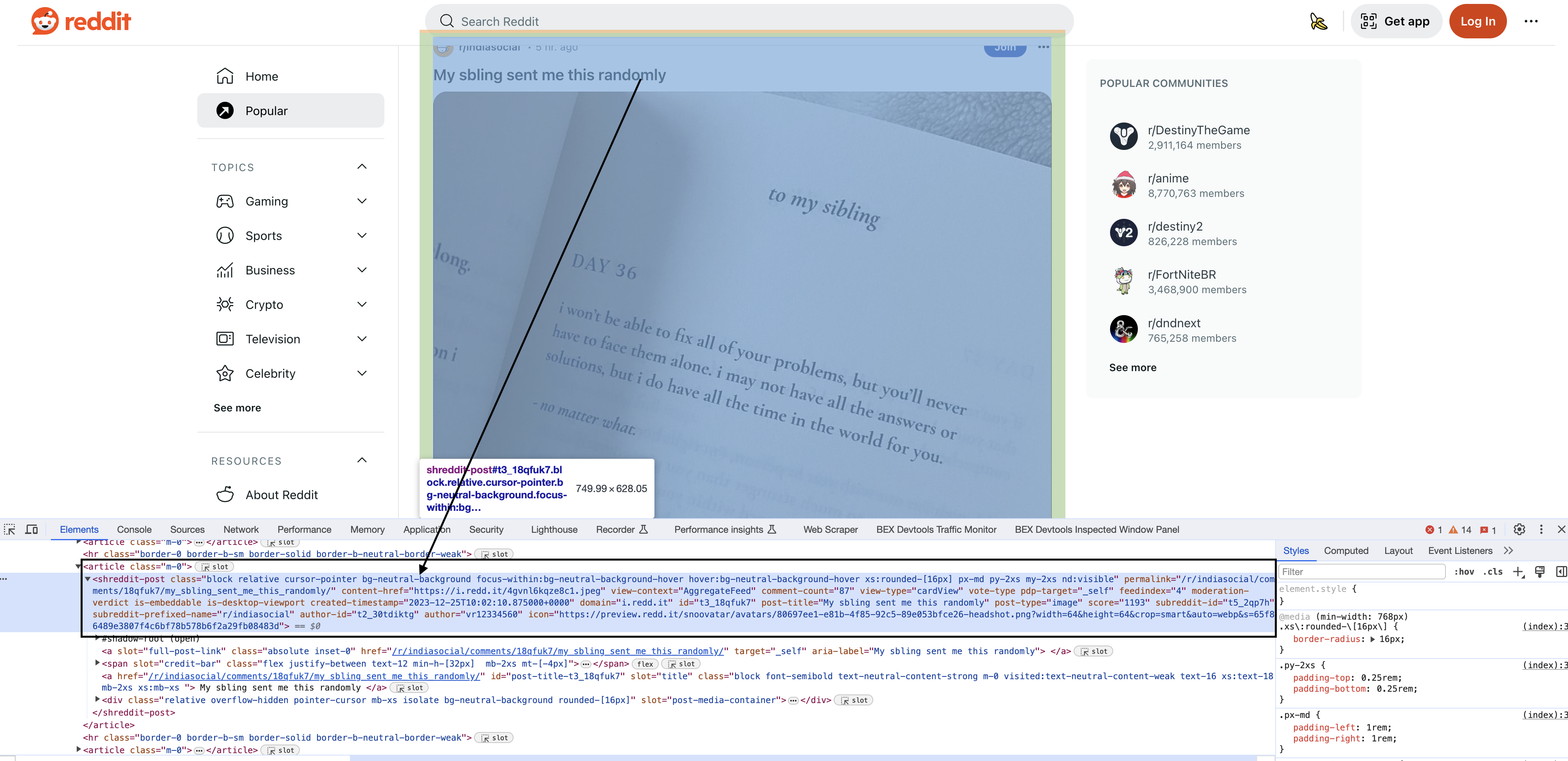
In the longest and perhaps trickiest part of the script, we use a complex CSS selector to extract Reddit post blocks from the parsed HTML document:
blocks = doc.css('shreddit-post.block.relative.cursor-pointer.bg-neutral-background.focus-within\\\\:bg-neutral-background-hover.hover\\\\:bg-neutral-background-hover.xs\\\\:rounded-\\\\\\[16px\\\\\\].p-md.my-2xs.nd\\\\:visible')
Let's break down what this selector is doing to understand it:
So in plain English, we're finding all Reddit post blocks on the page that have these very specific CSS classes styling and positioning them. This took some trail and error to pinpoint.
The key things to remember are:
This returns a
Looping Through the Posts
With the posts now stored in
blocks.each do |block|
# extract data from each block
end
Let's look at what information we're extracting from every block next.
Scraping Post Data
Inside the loop, we use the post
permalink = block['permalink']
content_href = block['content-href']
comment_count = block['comment-count']
post_title = block.css('div[slot="title"]').text.strip
author = block['author']
score = block['score']
Here's what we're grabbing and how:
The data points gathered describe core aspects of posts like title, author, webpage link, comments, score.
We print this data after the loop to output and check what we scraped.
The key things to emphasize again:
And most importantly, not changing the literal strings like
Putting It All Together
Walkthrough complete! Here is the full code:
require 'open-uri'
require 'nokogiri'
# Define the Reddit URL you want to download
reddit_url = "https://www.reddit.com"
# Define a User-Agent header
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
# Send a GET request to the URL with the User-Agent header
begin
html_content = URI.open(reddit_url, "User-Agent" => user_agent).read
# Specify the filename to save the HTML content
filename = "reddit_page.html"
# Save the HTML content to a file
File.open(filename, "w:UTF-8") do |file|
file.write(html_content)
end
puts "Reddit page saved to #{filename}"
rescue OpenURI::HTTPError => e
puts "Failed to download Reddit page (status code #{e.io.status[0]})"
end
# Parse the entire HTML content
doc = Nokogiri::HTML(html_content)
# Find all blocks with the specified tag and class
blocks = doc.css('shreddit-post.block.relative.cursor-pointer.bg-neutral-background.focus-within\:bg-neutral-background-hover.hover\:bg-neutral-background-hover.xs\:rounded-\[16px\].p-md.my-2xs.nd\:visible')
# Iterate through the blocks and extract information from each one
blocks.each do |block|
permalink = block['permalink']
content_href = block['content-href']
comment_count = block['comment-count']
post_title = block.css('div[slot="title"]').text.strip
author = block['author']
score = block['score']
# Print the extracted information for each block
puts "Permalink: #{permalink}"
puts "Content Href: #{content_href}"
puts "Comment Count: #{comment_count}"
puts "Post Title: #{post_title}"
puts "Author: #{author}"
puts "Score: #{score}"
puts "\n"
endAnd that's it! We walked through the script from start to finish, explaining how Reddit is scraped at each step of the way.
Let me know if any part was confusing or needs more clarification! I'm happy to explain web scraping concepts in further detail.