In this article, we'll go through R code to scrape various data from Reddit posts. We'll look at how to send requests, handle responses, extract information, and iterate through multiple posts.
here is the page we are talking about
Setup
We'll utilize two useful R packages for scraping web pages:
library(httr)
library(rvest)
The
Define Target URL
We first store the Reddit homepage URL that we want to scrape:
reddit_url <- "<https://www.reddit.com>"
Set User-Agent Header
Many sites check request headers to identify automated traffic. So we define a browser User-Agent to seem like a normal visitor:
headers <- list(
"User-Agent" = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
)
Send GET Request
We use the
response <- httr::GET(url = reddit_url, add_headers(.headers=headers))
Check Status Code
It's important to verify that the request succeeded by checking the status code:
if (httr::status_code(response) == 200) {
# Request succeeded logic
} else {
# Request failed logic
}
Status code 200 means our request succeeded. Other codes usually signify an error.
Save Raw HTML
Since our request succeeded, we can save the raw HTML to a file for later parsing:
html_content <- httr::content(response, "text")
filename <- "reddit_page.html"
cat(html_content, file = filename, sep = "", encoding = "UTF-8")
We use
Read HTML Content
To start extracting information, we need to read the HTML content into R using the
parsed_html <- read_html(html_content)
Understand CSS Selectors
Inspecting the elements
Upon inspecting the HTML in Chrome, you will see that each of the posts have a particular element shreddit-post and class descriptors specific to them…
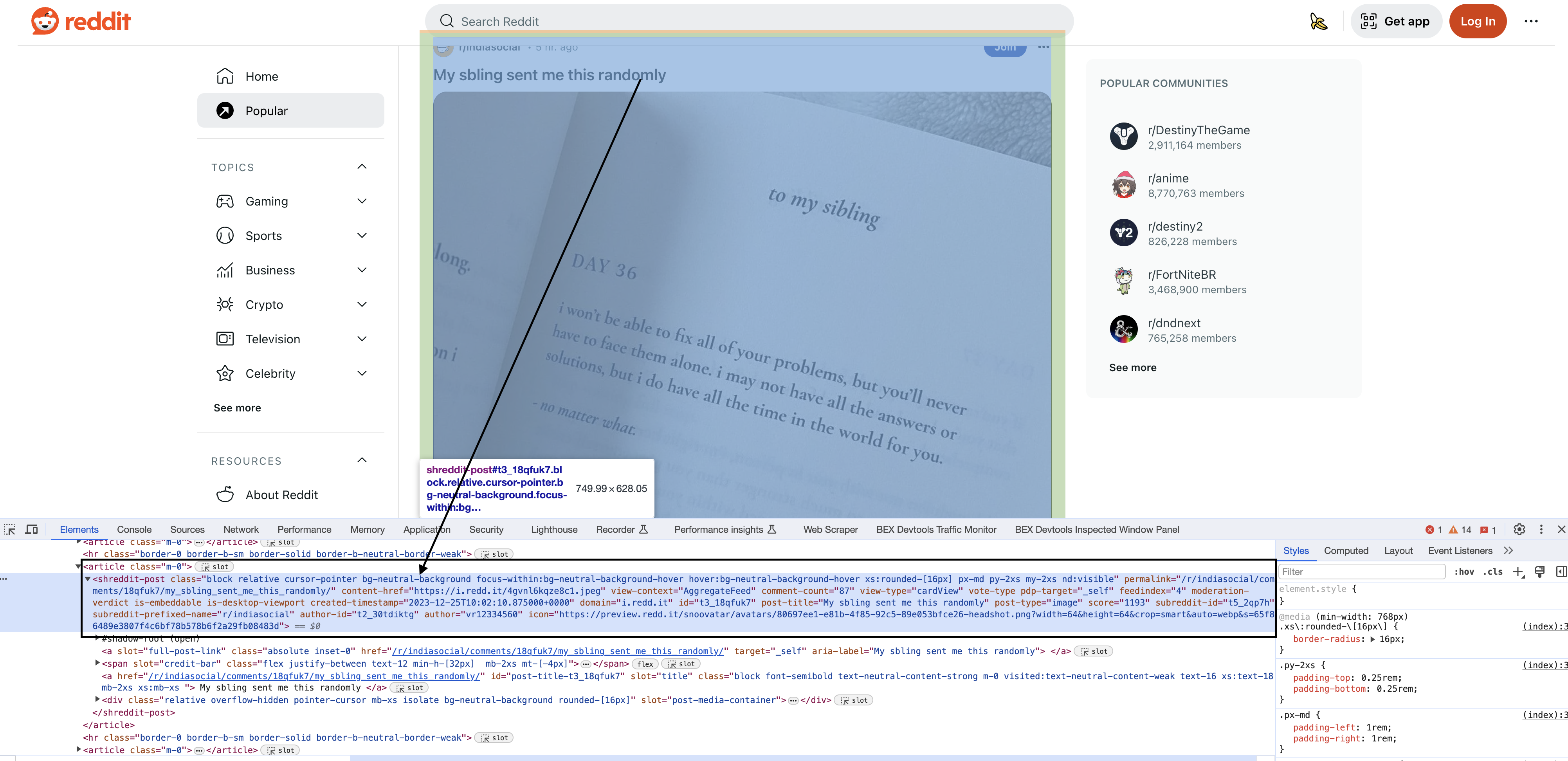
CSS selectors allow us to target specific elements in HTML/XML documents. They are extremely powerful but can be confusing for beginners.
We will go through this complex selector step-by-step:
.block.relative.cursor-pointer.bg-neutral-background.focus-within:bg-neutral-background-hover.hover:bg-neutral-background-hover.xs:rounded-[16px].p-md.my-2xs.nd:visible
Breaking this down:
.block - Target elements with class="block"
.relative - Also match class="relative"
.cursor-pointer - And class="cursor-pointer"
And so on for each subsequent class name. We are matching elements that have ALL these classes.
The bg-neutral-background parts check for state changes on hover/focus. These help isolate interactive elements.
:visible filters out any invisible elements.
Some key things for beginners:
There is still more we could unpack about selectors but this covers the key ideas. Let's see it in action.
Extract Post Data
We apply our selector to the parsed HTML, saving post blocks into a variable:
blocks <- parsed_html %>%
html_nodes(".block.relative.cursor-pointer...")
This gives us a collection of post block elements from the page.
Loop Through Posts
Next we iterate through each block, extracting various data points:
for (block in blocks) {
permalink <- block %>% html_attr("permalink")
content_href <- block %>% html_attr("content-href")
comment_count <- block %>% html_attr("comment-count")
post_title <- block %>% html_node("[slot='title']") %>% html_text(trim = TRUE)
author <- block %>% html_attr("author")
score <- block %>% html_attr("score")
# Print extracted data
cat(permalink, "\\\\n")
cat(content_href, "\\\\n")
...
}
Breaking this down:
This gives us the ability to extract many posts systematically.
The key ideas are:
Full Code
Here is the full Reddit scraping script:
library(httr)
library(rvest)
# Define the Reddit URL you want to download
reddit_url <- "https://www.reddit.com"
# Define a User-Agent header
headers <- list(
"User-Agent" = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
)
# Send a GET request to the URL with the User-Agent header
response <- httr::GET(url = reddit_url, add_headers(.headers=headers))
# Check if the request was successful (status code 200)
if (httr::status_code(response) == 200) {
# Get the HTML content of the page
html_content <- httr::content(response, "text")
# Specify the filename to save the HTML content
filename <- "reddit_page.html"
# Save the HTML content to a file
cat(html_content, file = filename, sep = "", encoding = "UTF-8")
cat(paste("Reddit page saved to", filename), "\n", sep = "")
} else {
cat(paste("Failed to download Reddit page (status code", httr::status_code(response), ")\n"), sep = "")
}
# Parse the entire HTML content
parsed_html <- read_html(html_content)
# Find all blocks with the specified tag and class
blocks <- parsed_html %>%
html_nodes(".block.relative.cursor-pointer.bg-neutral-background.focus-within:bg-neutral-background-hover.hover:bg-neutral-background-hover.xs:rounded-[16px].p-md.my-2xs.nd:visible")
# Iterate through the blocks and extract information from each one
for (block in blocks) {
permalink <- block %>% html_attr("permalink")
content_href <- block %>% html_attr("content-href")
comment_count <- block %>% html_attr("comment-count")
post_title <- block %>% html_node("[slot='title']") %>% html_text(trim = TRUE)
author <- block %>% html_attr("author")
score <- block %>% html_attr("score")
# Print the extracted information for each block
cat("Permalink: ", permalink, "\n")
cat("Content Href: ", content_href, "\n")
cat("Comment Count: ", comment_count, "\n")
cat("Post Title: ", post_title, "\n")
cat("Author: ", author, "\n")
cat("Score: ", score, "\n\n")
}