Nesting
article > div
Matches
Attributes
a[href^='/r/']
This lets us precisely target elements to extract data from.
Selecting Reddit Post Blocks
Inspecting the elements
Upon inspecting the HTML in Chrome, you will see that each of the posts have a particular element shreddit-post and class descriptors specific to them…
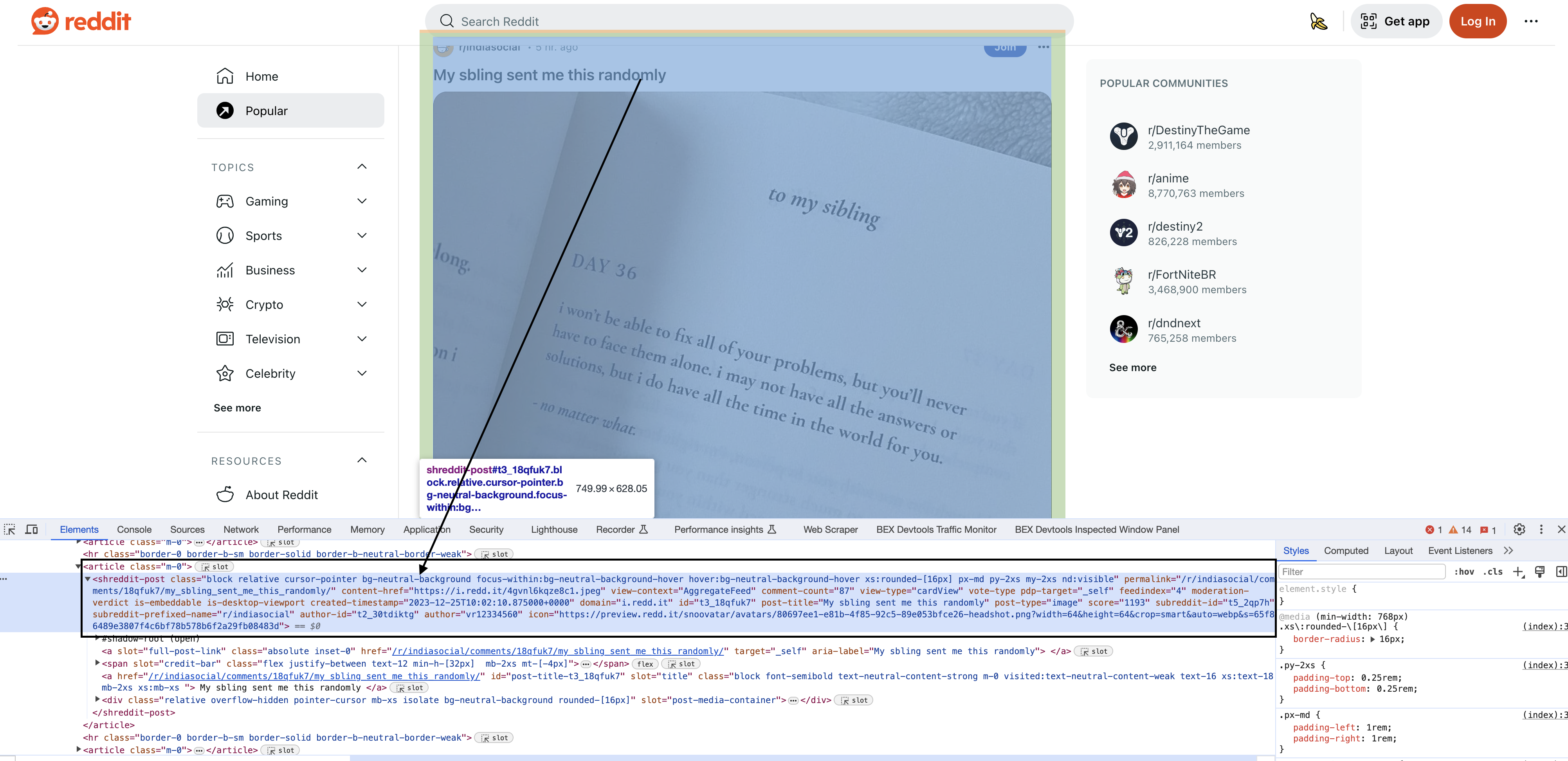
In our code, we select Reddit posts using the
val blocks = document.select("shreddit-post.block.relative.cursor-pointer.bg-neutral-background.focus-within:bg-neutral-background-hover.hover:bg-neutral-background-hover.xs:rounded-[16px].p-md.my-2xs.nd:visible")
This complex selector targets Reddit post blocks on the page. Let's break it down:
So in simple terms, we are selecting post blocks by the
Advanced selectors let us hone in on the exact set of elements we want. We could also use IDs or other attributes to target elements.
Extracting Post Data
Inside the selected post blocks, we can extract information:
for (block in blocks) {
val permalink = block.attr("permalink")
val contentHref = block.attr("content-href")
// extract other attributes..
}
The
Some key attributes we are extracting:
permalink - Post URL
contentHref - URL to comments
commentCount - Number of comments
postTitle - Title of the post
author - Username of poster
score - Upvote count
And that's it! We have extracted the data we wanted from Reddit posts. The output prints this information for each post.
The full code again:
import khttp.get
import org.jsoup.Jsoup
fun main() {
// Define the Reddit URL you want to download
val redditUrl = "https://www.reddit.com"
// Define a User-Agent header
val headers = mapOf(
"User-Agent" to "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
)
// Send a GET request to the URL with the User-Agent header
val response = get(redditUrl, headers = headers)
// Check if the request was successful (status code 200)
if (response.statusCode == 200) {
// Get the HTML content of the page
val htmlContent = response.text
// Specify the filename to save the HTML content
val filename = "reddit_page.html"
// Save the HTML content to a file
java.io.File(filename).writeText(htmlContent, Charsets.UTF_8)
println("Reddit page saved to $filename")
// Parse the HTML content
val document = Jsoup.parse(htmlContent)
// Find all blocks with the specified tag and class
val blocks = document.select("shreddit-post.block.relative.cursor-pointer.bg-neutral-background.focus-within:bg-neutral-background-hover.hover:bg-neutral-background-hover.xs:rounded-[16px].p-md.my-2xs.nd:visible")
// Iterate through the blocks and extract information from each one
for (block in blocks) {
val permalink = block.attr("permalink")
val contentHref = block.attr("content-href")
val commentCount = block.attr("comment-count")
val postTitle = block.select("div[slot=title]").text().trim()
val author = block.attr("author")
val score = block.attr("score")
// Print the extracted information for each block
println("Permalink: $permalink")
println("Content Href: $contentHref")
println("Comment Count: $commentCount")
println("Post Title: $postTitle")
println("Author: $author")
println("Score: $score")
println()
}
} else {
println("Failed to download Reddit page (status code ${response.statusCode})")
}
}While scrapers can get complex with handling JavaScript, cookies etc - this shows the basic concepts like sending requests, parsing HTML, and using selectors to extract data.