We will walk through an example that downloads a Reddit page, parses the HTML using AngleSharp, and extracts information from posts. The key part we will focus on is properly selecting elements and extracting data.
here is the page we are talking about
Walkthrough
First, we define some namespaces to import necessary functionality:
using System;
using System.IO;
using System.Net.Http;
using AngleSharp.Html.Dom;
using AngleSharp.Html.Parser;
Next, we specify the target URL and user agent header:
string reddit_url = "<https://www.reddit.com>";
string userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36";
The user agent mimics a Chrome browser on Windows.
We create an HttpClient instance and add our custom user agent header:
HttpClient httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("User-Agent", userAgent);
Then we can send a GET request to download the page:
HttpResponseMessage response = await httpClient.GetAsync(reddit_url);
We check if the request succeeded with the 200 status code:
if (response.IsSuccessStatusCode)
{
// process page
}
Inside this block, we can access the HTML content of the page:
string htmlContent = await response.Content.ReadAsStringAsync();
We will save this HTML locally to a file named
File.WriteAllText(filename, htmlContent);
Now we have downloaded the Reddit page and saved the HTML source. Next we will parse this using AngleSharp:
var parser = new HtmlParser();
var document = await parser.ParseDocumentAsync(htmlContent);
This gives us a document object representing the parsed DOM tree.
Querying Elements to Extract Data
The key part is using the document to find elements and extract information.
Inspecting the elements
Upon inspecting the HTML in Chrome, you will see that each of the posts have a particular element shreddit-post and class descriptors specific to them…
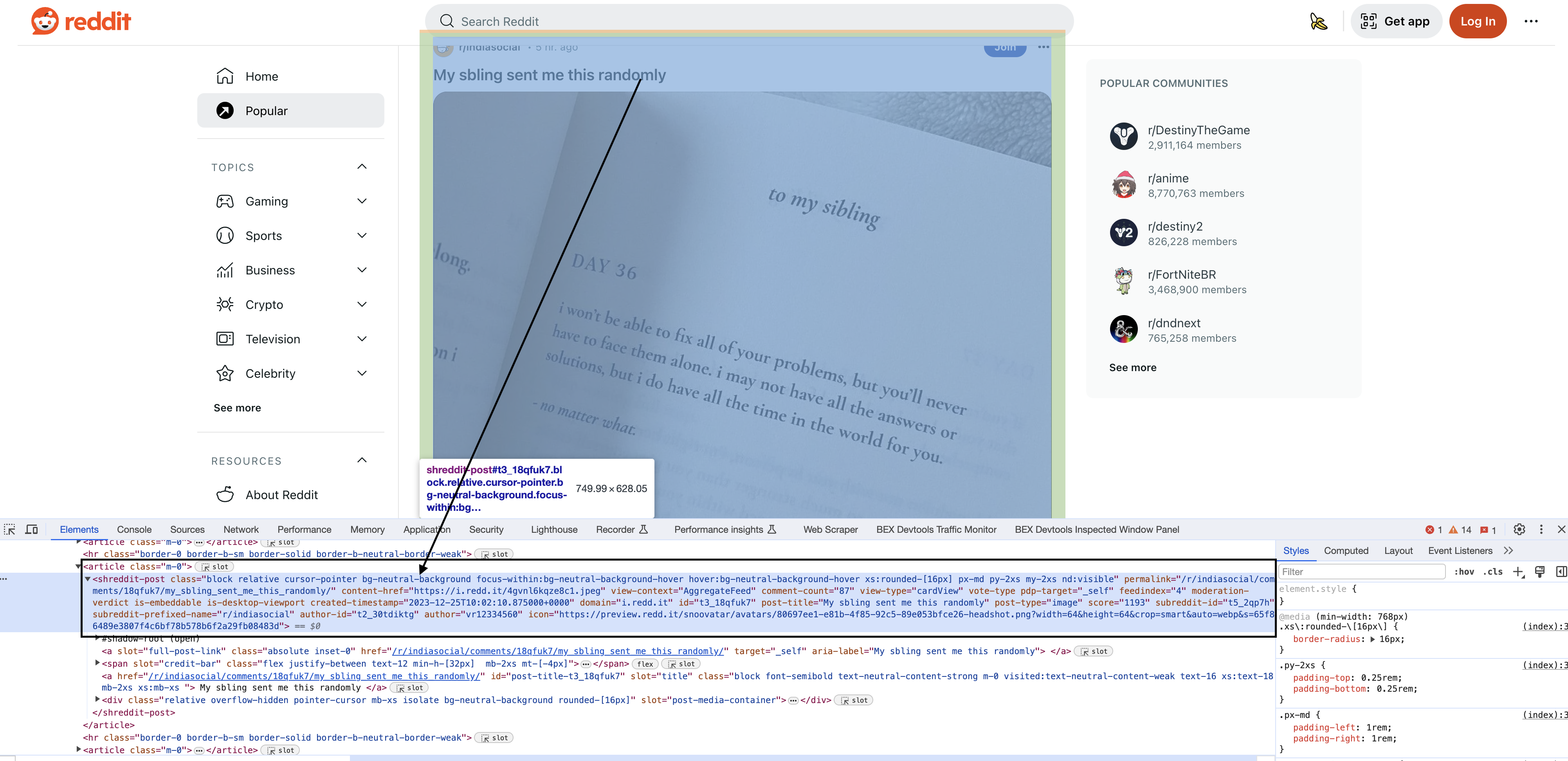
AngleSharp provides the
Here is the selector used in our example:
var blocks = document.QuerySelectorAll(".block.relative.cursor-pointer.bg-neutral-background.focus-within:bg-neutral-background-hover.hover:bg-neutral-background-hover.xs:rounded-[16px\\].p-md.my-2xs.nd:visible");
This selects elements with the class
We loop through each one to extract data:
foreach (var block in blocks)
{
// extract data from block
}
Each block contains useful information about the post:
Permalink
The page URL for the post:
string permalink = block.GetAttribute("permalink");
Content Href
URL to the content like article/video/image for that post:
string contentHref = block.GetAttribute("content-href");
Comment Count
Number of comments on the post:
string commentCount = block.GetAttribute("comment-count");
Post Title
Title of the Reddit post:
string postTitle = block.QuerySelector("div[slot='title']").TextContent.Trim();
Here we search within that block for the Author The Reddit user who authored the post: Score The net vote score of the post: And that covers extracting all the available data from a post block! We print out this information for each one: So in summary, this Selector finds Reddit post blocks, loops through them, and extracts details by: This allows collecting meaningful data from each post. The same process can be followed to scrape images or other information you need from a site. Here is the complete code sample:
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com" <!doctype html>string author = block.GetAttribute("author");
string score = block.GetAttribute("score");
Console.WriteLine($"Permalink: {permalink}");
// ...
Full Code Example
using System;
using System.IO;
using System.Net.Http;
using AngleSharp.Html.Dom;
using AngleSharp.Html.Parser;
class Program
{
static async System.Threading.Tasks.Task Main(string[] args)
{
// Define the Reddit URL you want to download
string reddit_url = "https://www.reddit.com";
// Define a User-Agent header
string userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36";
// Create an HttpClient with custom headers
HttpClient httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("User-Agent", userAgent);
// Send a GET request to the URL with the User-Agent header
HttpResponseMessage response = await httpClient.GetAsync(reddit_url);
// Check if the request was successful (status code 200)
if (response.IsSuccessStatusCode)
{
// Get the HTML content of the page as a string
string htmlContent = await response.Content.ReadAsStringAsync();
// Specify the filename to save the HTML content
string filename = "reddit_page.html";
// Save the HTML content to a file
File.WriteAllText(filename, htmlContent);
Console.WriteLine($"Reddit page saved to {filename}");
// Parse the HTML content using AngleSharp
var parser = new HtmlParser();
var document = await parser.ParseDocumentAsync(htmlContent);
// Find all blocks with the specified tag and class
var blocks = document.QuerySelectorAll(".block.relative.cursor-pointer.bg-neutral-background.focus-within:bg-neutral-background-hover.hover:bg-neutral-background-hover.xs:rounded-[16px].p-md.my-2xs.nd:visible");
// Iterate through the blocks and extract information from each one
foreach (var block in blocks)
{
string permalink = block.GetAttribute("permalink");
string contentHref = block.GetAttribute("content-href");
string commentCount = block.GetAttribute("comment-count");
string postTitle = block.QuerySelector("div[slot='title']").TextContent.Trim();
string author = block.GetAttribute("author");
string score = block.GetAttribute("score");
// Print the extracted information for each block
Console.WriteLine($"Permalink: {permalink}");
Console.WriteLine($"Content Href: {contentHref}");
Console.WriteLine($"Comment Count: {commentCount}");
Console.WriteLine($"Post Title: {postTitle}");
Console.WriteLine($"Author: {author}");
Console.WriteLine($"Score: {score}");
Console.WriteLine();
}
}
else
{
Console.WriteLine($"Failed to download Reddit page (status code {response.StatusCode})");
}
}
}Browse by tags:
Browse by language:
The easiest way to do Web Scraping
Try ProxiesAPI for free
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...