In this article, we will learn how to scrape real estate listings from Realtor.com using PHP and cURL. The full code is provided at the end for reference as we go through each section in detail.
We will cover:
This is the listings page we are talking about…
Let's get started!
Installation
Before running the scraping script, some prerequisites need to be installed:
Installing/Enabling cURL
This script also requires the cURL extension for PHP which allows making HTTP requests in PHP.
cURL may already be enabled depending on your PHP installation. You can check if it is enabled by running:
php -m | grep curl
If you see "curl" in the output, then cURL is installed and you should be good to go.
If cURL is not enabled, follow these instructions to install and enable it for PHP.
In short, on Ubuntu/Debian:
sudo apt-get install php-curl
sudo service apache2 restart
And the cURL extension should now be enabled.
Okay, with the prerequisites out of the way, let's look at the code!
Defining the Target URL
First, we define the root URL of the Realtor.com page we want to scrape:
$url = "<https://www.realtor.com/realestateandhomes-search/San-Francisco\\_CA>";
This URL targets real estate listings in San Francisco.
When web scraping, always double check you have the right homepage/search URL to scrape from! This saves trouble later.
Setting Request Headers with User-Agent
Many websites block default browser user agents these days to prevent scraping. So it's important to spoof a browser:
$headers = [
"User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
];
We define a heades array containing a typical Chrome desktop user agent string. This mimics a real browser visit to avoid blocks.
There are services where you can generate browser user agents for free. Or grab them from your browsers dev tools Network tab on a site.
Initializing and Configuring cURL
With target prepared, we can initialize a cURL session which will handle connecting to the page and transferring data:
$ch = curl_init();
Next we set a number of cURL options to configure our request:
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
Let's understand them:
These are the main options needed. There are many more available to configure proxies, authentication, cookies, etc.
Sending the Request and Processing Output
With cURL initialized, headers set, and options configured - we send the GET request:
$response = curl_exec($ch);
This executes the cURL request defined by our handle
We can check if the request succeeded:
if ($response && curl_getinfo($ch, CURLINFO_HTTP_CODE) == 200) {
// Request succeeded!
} else {
// Request failed
}
Here we:
- Check if
$response contains a value - Use
curl_getinfo() to get the HTTP status code and compare to 200 OK
This protects against failed requests down the line.
Parsing Listings with DOMDocument
With HTML response stored, we can parse it to extract data. We'll use PHP's DOMDocument and DOMXPath to query elements:
$dom = new DOMDocument();
$dom->loadHTML($response);
$xpath = new DOMXPath($dom);
This:
- Creates a new
DOMDocument - Loads our HTML response to parse
- Gets an
XPath object to query DOM elements
XPath allows querying elements by CSS selector like syntax.
Extracting Listing Data
Now the fun part - using XPath to extract key real estate listing details!
Inspecting the element
When we inspect element in Chrome we can see that each of the listing blocks is wrapped in a div with a class value as shown below…
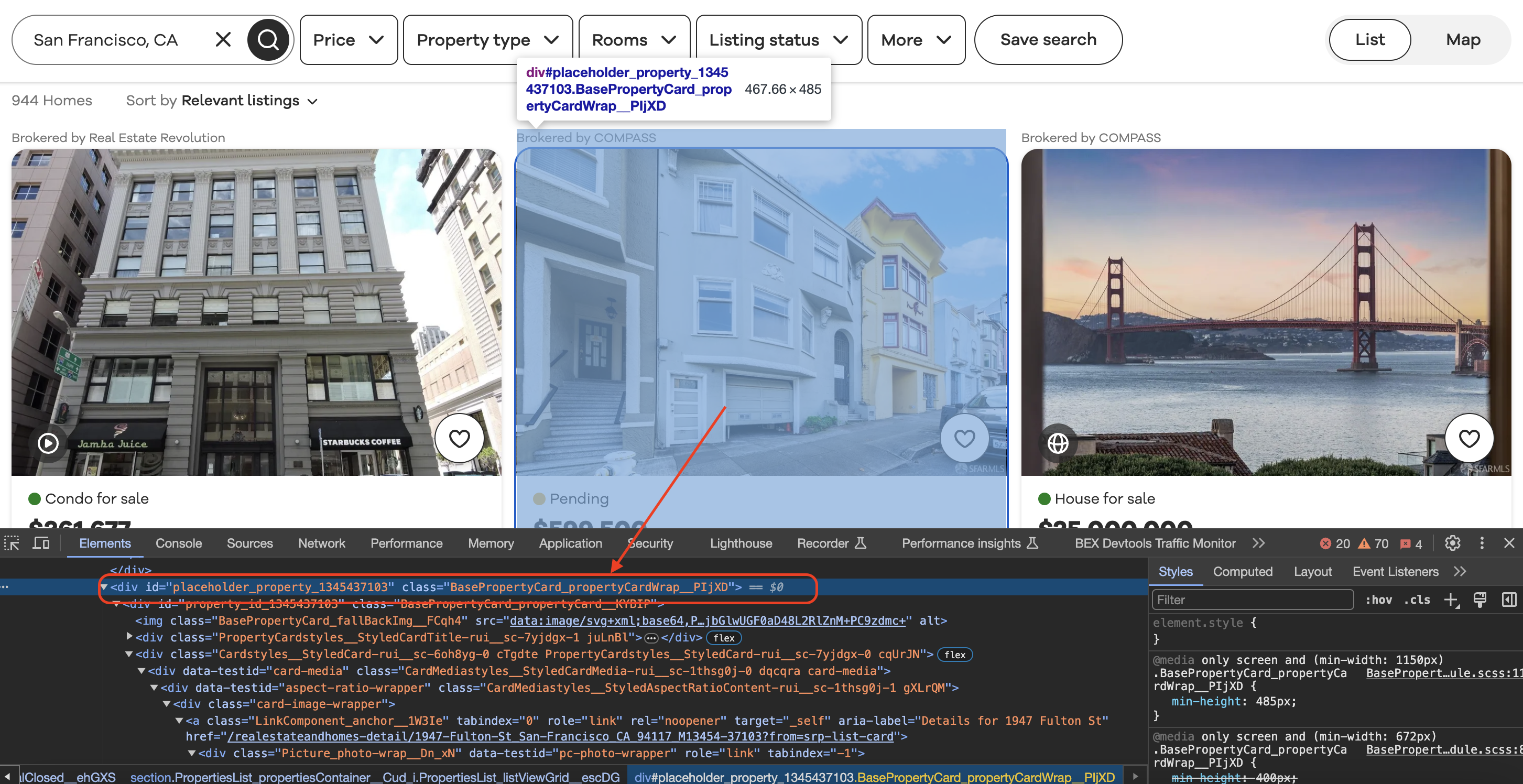
First we locate all listing container elements on the page:
$listing_blocks = $xpath->query('//div[contains(@class, "BasePropertyCard_propertyCardWrap__J0xUj")]');
This queries DIVs with the class
Note: We check for the class name containing that string since it can be minified or changed compared to inspecting the element in browser dev tools.
With listing containers selected, we loop through them:
foreach ($listing_blocks as $listing_block) {
// Extract data from $listing_block
}
And use XPath queries within each listing block to extract details, e.g.:
Get broker name:
$broker_info = $xpath->query('.//div[contains(@class, "BrokerTitle_brokerTitle__ZkbBW")]', $listing_block);
$broker_name = $broker_info->textContent;
Get number of beds:
$beds = $xpath->query('.//li[@data-testid="property-meta-beds"]', $listing_block)->textContent;
And similarly for other fields like status, price, baths, etc. targeted by class/attribute values.
Note again how we match partial class names and check attributes to create resilient selectors.
The key is properly crafting XPath queries to extract intended listing data from the DOM.
Output and Formatting
Finally, we output and format the scraped details:
echo "Broker: " . $broker_name . "\\n";
echo "Beds: " . $beds . "\\n";
// And so on...
echo str_repeat("-", 50) . "\\n"; // Separator
Here we:
The output can then be processed further based on the use case - maybe store to CSV or JSON, insert to a database, etc.
And that covers a typical web scraping workflow!
Full Code
For reference, here is the full code:
<?php
// Define the URL of the Realtor.com search page
$url = "https://www.realtor.com/realestateandhomes-search/San-Francisco_CA";
// Define a User-Agent header
$headers = [
"User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36" // Replace with your User-Agent string
];
// Initialize cURL session
$ch = curl_init();
// Set cURL options
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// Send a GET request to the URL with the User-Agent header
$response = curl_exec($ch);
// Check if the request was successful (HTTP status code 200)
if ($response && curl_getinfo($ch, CURLINFO_HTTP_CODE) == 200) {
// Parse the HTML content of the page using DOMDocument and DOMXPath
$dom = new DOMDocument();
libxml_use_internal_errors(true); // Suppress parsing errors
$dom->loadHTML($response);
libxml_clear_errors();
// Create an XPath object
$xpath = new DOMXPath($dom);
// Find all the listing blocks using the provided class name
$listing_blocks = $xpath->query('//div[contains(@class, "BasePropertyCard_propertyCardWrap__J0xUj")]');
// Loop through each listing block and extract information
foreach ($listing_blocks as $listing_block) {
// Extract the broker information
$broker_info = $xpath->query('.//div[contains(@class, "BrokerTitle_brokerTitle__ZkbBW")]', $listing_block)->item(0);
$broker_name = $xpath->query('.//span[contains(@class, "BrokerTitle_titleText__20u1P")]', $broker_info)->item(0)->textContent;
// Extract the status (e.g., For Sale)
$status = $xpath->query('.//div[contains(@class, "message")]', $listing_block)->item(0)->textContent;
// Extract the price
$price = $xpath->query('.//div[contains(@class, "card-price")]', $listing_block)->item(0)->textContent;
// Extract other details like beds, baths, sqft, and lot size
$beds_element = $xpath->query('.//li[@data-testid="property-meta-beds"]', $listing_block)->item(0);
$baths_element = $xpath->query('.//li[@data-testid="property-meta-baths"]', $listing_block)->item(0);
$sqft_element = $xpath->query('.//li[@data-testid="property-meta-sqft"]', $listing_block)->item(0);
$lot_size_element = $xpath->query('.//li[@data-testid="property-meta-lot-size"]', $listing_block)->item(0);
// Check if the elements exist before extracting their text
$beds = $beds_element ? $beds_element->textContent : "N/A";
$baths = $baths_element ? $baths_element->textContent : "N/A";
$sqft = $sqft_element ? $sqft_element->textContent : "N/A";
$lot_size = $lot_size_element ? $lot_size_element->textContent : "N/A";
// Extract the address
$address = $xpath->query('.//div[contains(@class, "card-address")]', $listing_block)->item(0)->textContent;
// Print the extracted information
echo "Broker: " . trim($broker_name) . "\n";
echo "Status: " . trim($status) . "\n";
echo "Price: " . trim($price) . "\n";
echo "Beds: " . trim($beds) . "\n";
echo "Baths: " . trim($baths) . "\n";
echo "Sqft: " . trim($sqft) . "\n";
echo "Lot Size: " . trim($lot_size) . "\n";
echo "Address: " . trim($address) . "\n";
echo str_repeat("-", 50) . "\n"; // Separating listings
}
} else {
echo "Failed to retrieve the page. Status code: " . curl_getinfo($ch, CURLINFO_HTTP_CODE) . "\n";
}
// Close the cURL session
curl_close($ch);
?>