Web scraping real estate listings can be a useful way to collect and analyze housing data. This article will teach you how to scrape real estate listing data from Realtor.com using Go and the goquery library.
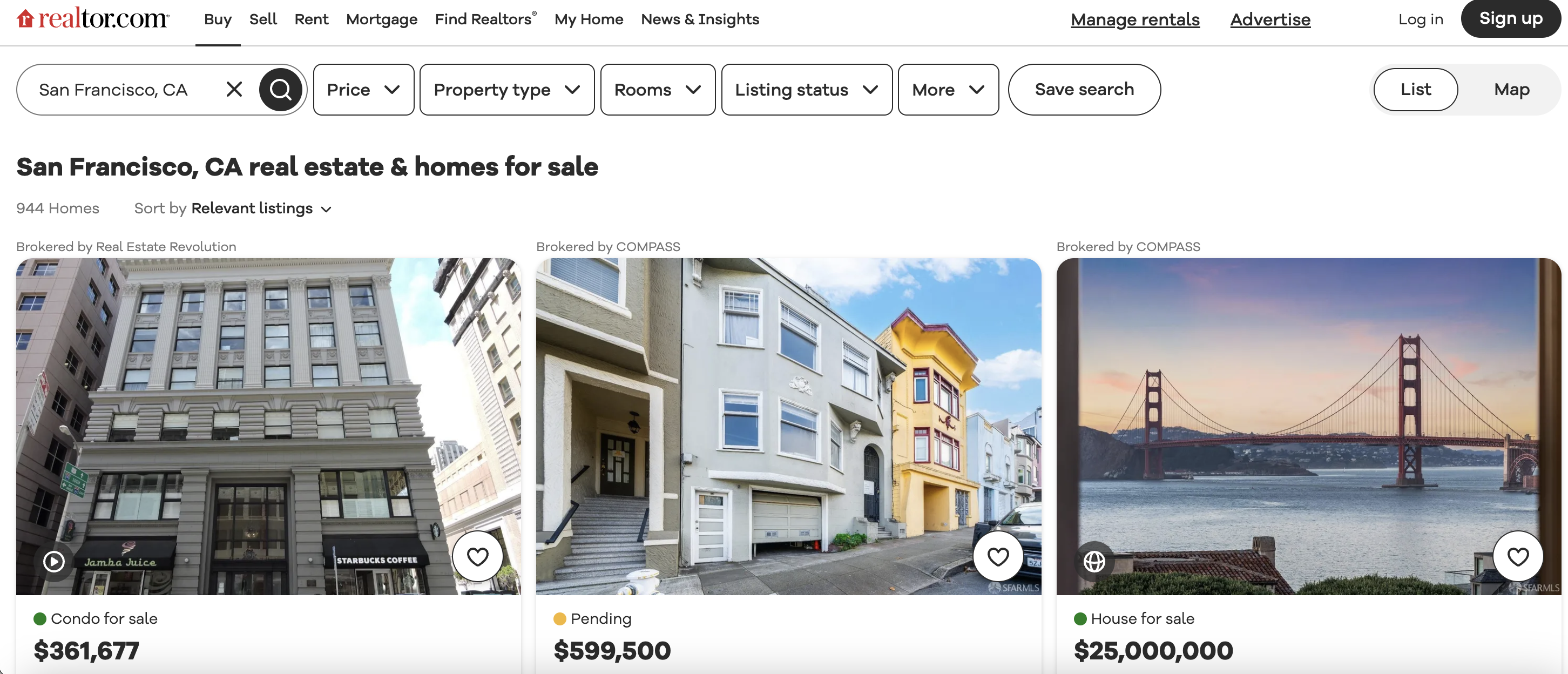
This is the listings page we are talking about…
Prerequisites
To follow along, you'll need:
import (
"fmt"
"log"
"net/http"
"strings"
"github.com/PuerkitoBio/goquery"
)
To install goquery, run:
go get github.com/PuerkitoBio/goquery
Making the Initial Request
First we'll define the URL of the Realtor.com search page we want to scrape:
url := "<https://www.realtor.com/realestateandhomes-search/San-Francisco_CA>"
And set a User-Agent header to mimic a real browser request:
userAgent := "Mozilla/5..."
req.Header.Set("User-Agent", userAgent)
We make a GET request to this URL using Go's http client. And check that the status code in the response is 200 OK:
resp, err := client.Do(req)
if resp.StatusCode == 200 {
// Parsing logic here
}
So far so good! We've made a request to Realtor.com and verified we can access the page. Next we'll extract the data...
Parsing the Page with goquery
We'll use the goquery library to parse the HTML content of the page into a document:
doc, err := goquery.NewDocumentFromReader(resp.Body)
goquery allows querying elements similar to how you would using jQuery.
Extracting Listing Data
Now the real work begins - extracting actual listing data from the HTML document.
Inspecting the element
When we inspect element in Chrome we can see that each of the listing blocks is wrapped in a div with a class value as shown below…
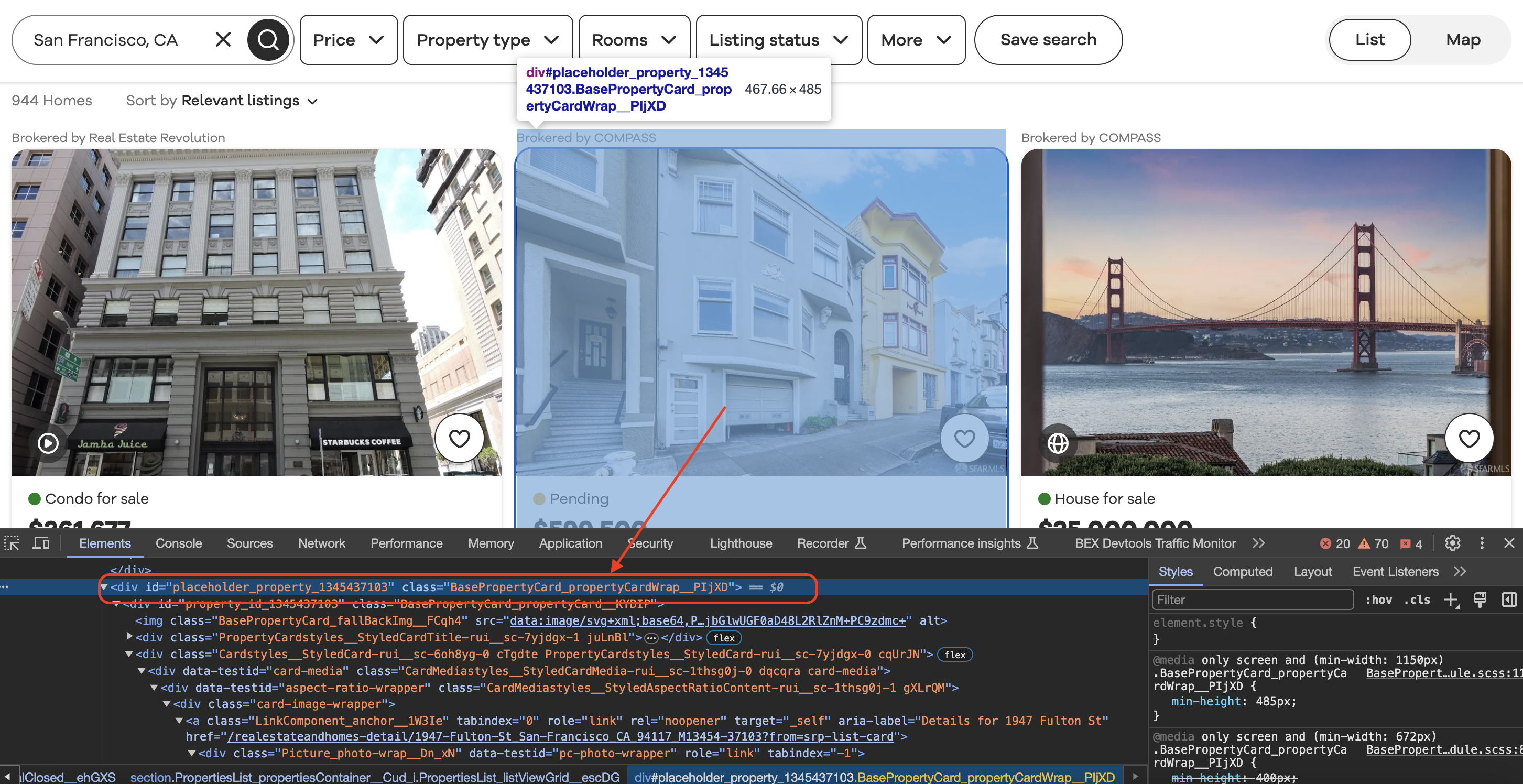
Realtor.com conveniently puts each listing card in a
We can select all of these using goquery's
doc.Find(".BasePropertyCard_propertyCardWrap__J0xUj").Each(func(i int, listingBlock *goquery.Selection) {
// Extract data from listingBlock here
})
This loops through each individual listing block for us to extract data from. Let's go through each data field one-by-one:
Broker Name
The broker name is nested under some additional
<div class="BrokerTitle_brokerTitle__ZkbBW">
<span class="BrokerTitle_titleText__20u1P">Compass</span>
</div>
We can use a nested selector to get to the broker name text:
brokerInfo := listingBlock.Find(".BrokerTitle_brokerTitle__ZkbBW")
brokerName := brokerInfo.Find("span.BrokerTitle_titleText__20u1P").Text()
Status
The status (e.g. 'For Sale') is under a
status := listingBlock.Find(".message").Text()
Price
The price is conveniently in a
price := listingBlock.Find(".card-price").Text()
And so on for other fields like beds, baths etc which we can see have explicit
beds := listingBlock.Find("li[data-testid=property-meta-beds]").Text()
baths := listingBlock.Find("li[data-testid=property-meta-baths]").Text()
Finally we print out all the extracted info!
fmt.Println("Broker:", strings.TrimSpace(brokerName))
fmt.Println("Status:", strings.TrimSpace(status))
fmt.Println("Price:", strings.TrimSpace(price))
fmt.Println("Address:", strings.TrimSpace(address))
And that's it! Here the key things to understand are:
With just a few lines of goquery selectors, we were able to extract useful fields from complicated HTML.
The full code can be seen below for reference:
package main
import (
"fmt"
"log"
"net/http"
"strings"
"github.com/PuerkitoBio/goquery"
)
func main() {
// Define the URL of the Realtor.com search page
url := "https://www.realtor.com/realestateandhomes-search/San-Francisco_CA"
// Define a User-Agent header
userAgent := "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
// Send a GET request to the URL with the User-Agent header
client := &http.Client{}
req, err := http.NewRequest("GET", url, nil)
if err != nil {
log.Fatal("Failed to create a GET request:", err)
}
req.Header.Set("User-Agent", userAgent)
resp, err := client.Do(req)
if err != nil {
log.Fatal("Failed to send GET request:", err)
}
defer resp.Body.Close()
// Check if the request was successful (status code 200)
if resp.StatusCode == 200 {
// Parse the HTML content of the page using goquery
doc, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
log.Fatal("Failed to parse HTML:", err)
}
// Find all the listing blocks using the provided class name
doc.Find(".BasePropertyCard_propertyCardWrap__J0xUj").Each(func(i int, listingBlock *goquery.Selection) {
// Extract the broker information
brokerInfo := listingBlock.Find(".BrokerTitle_brokerTitle__ZkbBW")
brokerName := brokerInfo.Find("span.BrokerTitle_titleText__20u1P").Text()
// Extract the status (e.g., For Sale)
status := listingBlock.Find(".message").Text()
// Extract the price
price := listingBlock.Find(".card-price").Text()
// Extract other details like beds, baths, sqft, and lot size
beds := listingBlock.Find("li[data-testid=property-meta-beds]").Text()
baths := listingBlock.Find("li[data-testid=property-meta-baths]").Text()
sqft := listingBlock.Find("li[data-testid=property-meta-sqft]").Text()
lotSize := listingBlock.Find("li[data-testid=property-meta-lot-size]").Text()
// Extract the address
address := listingBlock.Find(".card-address").Text()
// Print the extracted information
fmt.Println("Broker:", strings.TrimSpace(brokerName))
fmt.Println("Status:", strings.TrimSpace(status))
fmt.Println("Price:", strings.TrimSpace(price))
fmt.Println("Beds:", strings.TrimSpace(beds))
fmt.Println("Baths:", strings.TrimSpace(baths))
fmt.Println("Sqft:", strings.TrimSpace(sqft))
fmt.Println("Lot Size:", strings.TrimSpace(lotSize))
fmt.Println("Address:", strings.TrimSpace(address))
fmt.Println(strings.Repeat("-", 50)) // Separating listings
})
} else {
log.Println("Failed to retrieve the page. Status code:", resp.StatusCode)
}
}