Web scraping allows you to programmatically extract data from websites. In this beginner C++ tutorial, we'll walk through code that scrapes real estate listing data from Realtor.com.
Background
This program sends a request to the Realtor.com URL, downloads the HTML content from the page, and uses XML parsing libraries to analyze the HTML and extract specific listing details like price, address, beds, baths etc.
It uses 3 external libraries to do this:
libcurl - Makes the initial request and retrieves the raw HTML
libxml2 - Parses the HTML so we can analyze it
XPath - A querying language for targeting specific parts of the parsed HTML
This is the listings page we are talking about…
Let's look at how it's done!
Include the Needed Libraries
We start by including headers for the external libraries we'll use:
#include <iostream>
#include <string>
#include <curl/curl.h>
#include <libxml/HTMLparser.h>
#include <libxml/xpath.h>
Make sure these libraries are installed to compile and run the program later.
Define the Target URL
We'll scrape listing data from Realtor.com focused on San Francisco:
const std::string url = "<https://www.realtor.com/realestateandhomes-search/San-Francisco_CA>";
This URL will be passed to libcurl to download the page content.
Initialize CURL and Make Request
Next we initialize a curl "handle", set options, and make the HTTP request:
CURL *curl = curl_easy_init();
// Set options like URL and headers
curl_easy_setopt(curl, CURLOPT_URL, url.c_str());
// Send GET request
CURLcode res = curl_easy_perform(curl);
This downloads the HTML content from the provided URL.
Parse the HTML
With libcurl fetching the raw HTML, libxml2 parses it so we can analyze the page content:
xmlDocPtr doc = htmlReadDoc(responseData, NULL, NULL, HTML_PARSE_RECOVER);
Analyze Parsed HTML with XPath
Now we can use XPath queries to target specific parts of the parsed HTML.
XPath expressions let you navigate through XML/HTML structures. Some examples:
Let's see this in action to extract real estate listings!
Set Up the XPath Context
We first create an XPath context - an object to hold the query state:
xmlXPathContextPtr xpathCtx = xmlXPathNewContext(doc);
Pass it the parsed HTML doc to query against.
Define XPath Expressions
Inspecting the element
When we inspect element in Chrome we can see that each of the listing blocks is wrapped in a div with a class value as shown below…
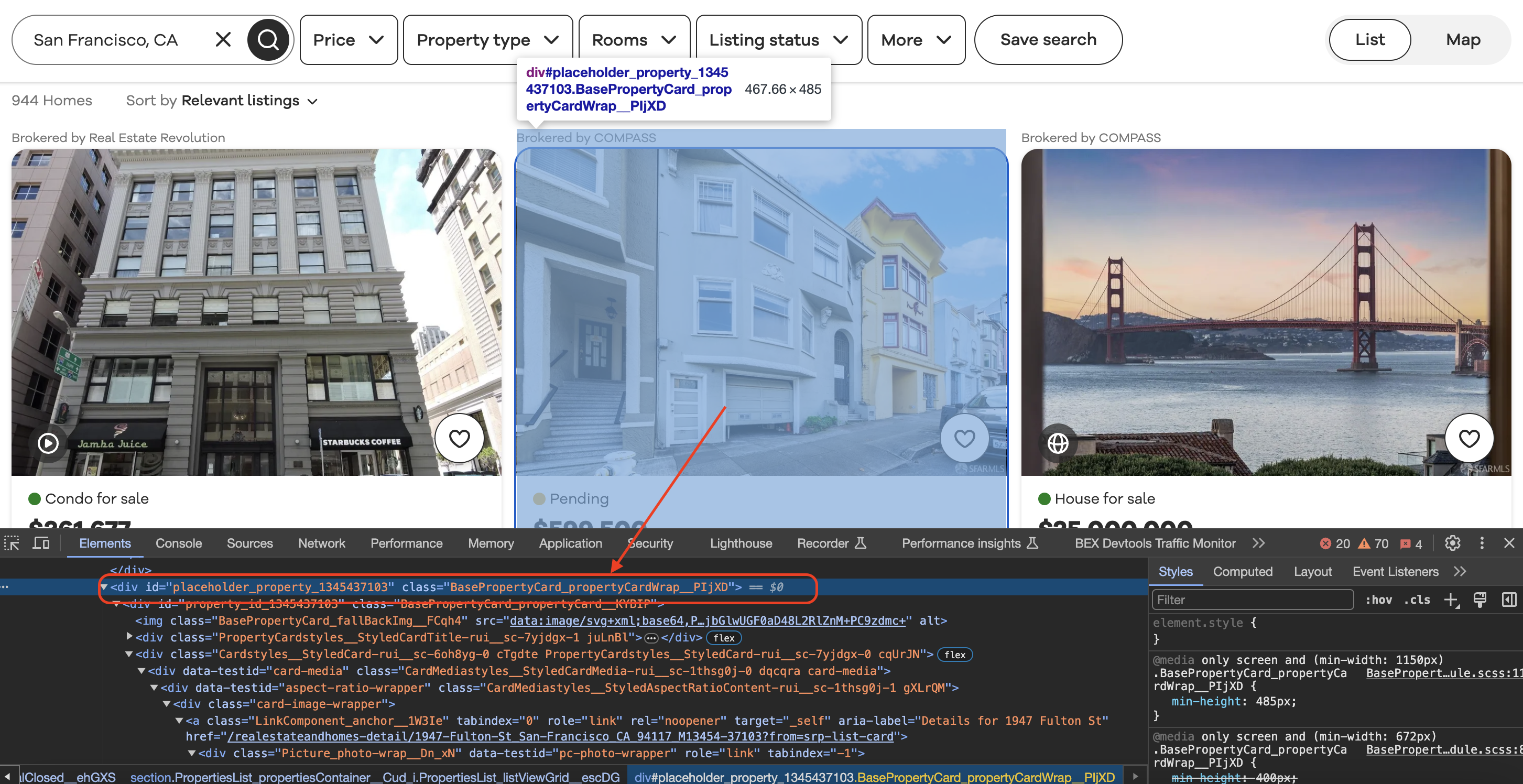
Now we can define XPath queries to pull listing data.
First, an expression to get all listing container blocks:
const xmlChar* xpathExpr = "//div[contains(@class, 'BasePropertyCard')]";
This targets Later queries will be limited to these listing blocks. To run the queries, we use This loops through each matching Inside here we extract details from each listing, using additional XPath queries scoped to that listing's XML node. For example, price data: The same process extracts address, beds, baths etc! That's the key logic to scrape these listings from Realtor.com in C++! We walked through: The full runnable code is below to see it all put together. Hope this gives you a great starting point for your own web scraping projects! Let me know if you have any other questions.
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com" <!doctype html> Enter your email below to claim your free API key:Evaluate Expressions & Extract Data
xmlXPathObjectPtr results = xmlXPathEvalExpression(xpathExpr, xpathCtx);
for(int i = 0; i < results->nodesetval->nodeNr; i++) {
xmlNodePtr listing = results->nodesetval->nodeTab[i];
// Extract data from this listing node
}
std::string price = xmlXPathEvalExpression(
".//div[contains(@class, 'price')]",
listing
)->nodesetval->nodeTab[0]->children->content;
Wrap Up
#include <iostream>
#include <string>
#include <curl/curl.h>
#include <libxml/HTMLparser.h>
#include <libxml/xpath.h>
int main() {
// Define the URL of the Realtor.com search page
const std::string url = "https://www.realtor.com/realestateandhomes-search/San-Francisco_CA";
// Initialize libcurl
CURL *curl = curl_easy_init();
if (curl) {
// Define a User-Agent header
struct curl_slist *headers = NULL;
headers = curl_slist_append(headers, "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36");
// Set libcurl options
curl_easy_setopt(curl, CURLOPT_URL, url.c_str());
curl_easy_setopt(curl, CURLOPT_HTTPHEADER, headers);
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, NULL);
// Send a GET request to the URL with the User-Agent header
CURLcode res = curl_easy_perform(curl);
if (res == CURLE_OK) {
// Parse the HTML content of the page using libxml2
xmlDocPtr doc = htmlReadDoc(reinterpret_cast<const xmlChar*>(curl_easy_strerror(res)), NULL, NULL, HTML_PARSE_RECOVER);
if (doc) {
// Create an XPath context
xmlXPathContextPtr xpathCtx = xmlXPathNewContext(doc);
if (xpathCtx) {
// Define the XPath expression to find all the listing blocks
const xmlChar* xpathExpr = (const xmlChar*)"//div[contains(@class, 'BasePropertyCard_propertyCardWrap__J0xUj')]";
// Evaluate the XPath expression
xmlXPathObjectPtr xpathObj = xmlXPathEvalExpression(xpathExpr, xpathCtx);
if (xpathObj) {
// Loop through each listing block and extract information
for (int i = 0; i < xpathObj->nodesetval->nodeNr; i++) {
xmlNodePtr listing_block = xpathObj->nodesetval->nodeTab[i];
// Extract the broker information
xmlNodePtr broker_info = xmlXPathEvalExpression((const xmlChar*)".//div[contains(@class, 'BrokerTitle_brokerTitle__ZkbBW')]", listing_block)->nodesetval->nodeTab[0];
std::string broker_name = xmlXPathEvalExpression((const xmlChar*)".//span[contains(@class, 'BrokerTitle_titleText__20u1P')]", broker_info)->nodesetval->nodeTab[0]->children->content;
// Extract the status (e.g., For Sale)
std::string status = xmlXPathEvalExpression((const xmlChar*)".//div[contains(@class, 'message')]", listing_block)->nodesetval->nodeTab[0]->children->content;
// Extract the price
std::string price = xmlXPathEvalExpression((const xmlChar*)".//div[contains(@class, 'card-price')]", listing_block)->nodesetval->nodeTab[0]->children->content;
// Extract other details like beds, baths, sqft, and lot size
xmlNodePtr beds_element = xmlXPathEvalExpression((const xmlChar*)".//li[@data-testid='property-meta-beds']", listing_block)->nodesetval->nodeTab[0];
xmlNodePtr baths_element = xmlXPathEvalExpression((const xmlChar*)".//li[@data-testid='property-meta-baths']", listing_block)->nodesetval->nodeTab[0];
xmlNodePtr sqft_element = xmlXPathEvalExpression((const xmlChar*)".//li[@data-testid='property-meta-sqft']", listing_block)->nodesetval->nodeTab[0];
xmlNodePtr lot_size_element = xmlXPathEvalExpression((const xmlChar*)".//li[@data-testid='property-meta-lot-size']", listing_block)->nodesetval->nodeTab[0];
// Check if the elements exist before extracting their text
std::string beds = beds_element ? reinterpret_cast<const char*>(beds_element->children->content) : "N/A";
std::string baths = baths_element ? reinterpret_cast<const char*>(baths_element->children->content) : "N/A";
std::string sqft = sqft_element ? reinterpret_cast<const char*>(sqft_element->children->content) : "N/A";
std::string lot_size = lot_size_element ? reinterpret_cast<const char*>(lot_size_element->children->content) : "N/A";
// Extract the address
std::string address = xmlXPathEvalExpression((const xmlChar*)".//div[contains(@class, 'card-address')]", listing_block)->nodesetval->nodeTab[0]->children->content;
// Print the extracted information
std::cout << "Broker: " << broker_name << std::endl;
std::cout << "Status: " << status << std::endl;
std::cout << "Price: " << price << std::endl;
std::cout << "Beds: " << beds << std::endl;
std::cout << "Baths: " << baths << std::endl;
std::cout << "Sqft: " << sqft << std::endl;
std::cout << "Lot Size: " << lot_size << std::endl;
std::cout << "Address: " << address << std::endl;
std::cout << std::string(50, '-') << std::endl; // Separating listings
}
// Free the XPath object
xmlXPathFreeObject(xpathObj);
}
// Free the XPath context
xmlXPathFreeContext(xpathCtx);
}
// Free the parsed HTML document
xmlFreeDoc(doc);
}
} else {
std::cerr << "Failed to retrieve the page. Error code: " << res << std::endl;
}
// Cleanup libcurl
curl_easy_cleanup(curl);
// Cleanup libcurl headers
curl_slist_free_all(headers);
} else {
std::cerr << "Failed to initialize libcurl" << std::endl;
}
return 0;
}Browse by tags:
Browse by language:
The easiest way to do Web Scraping
Try ProxiesAPI for free
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...Don't leave just yet!