Getting Started
To follow along with this code, you'll need to have R installed along with the rvest and stringr packages. Here is the install code:
install.packages("rvest")
install.packages("stringr")
Now let's jump right into the code...
Overview
This script does the following high-level steps:
- Defines the URL to scrape (Realtor.com for San Francisco)
- Sends a request to that URL
- Checks if the request succeeded
- Finds all real estate listing blocks on the page
- Loops through each listing block to extract key details
Next we'll break down that last step of extracting data from each listing...
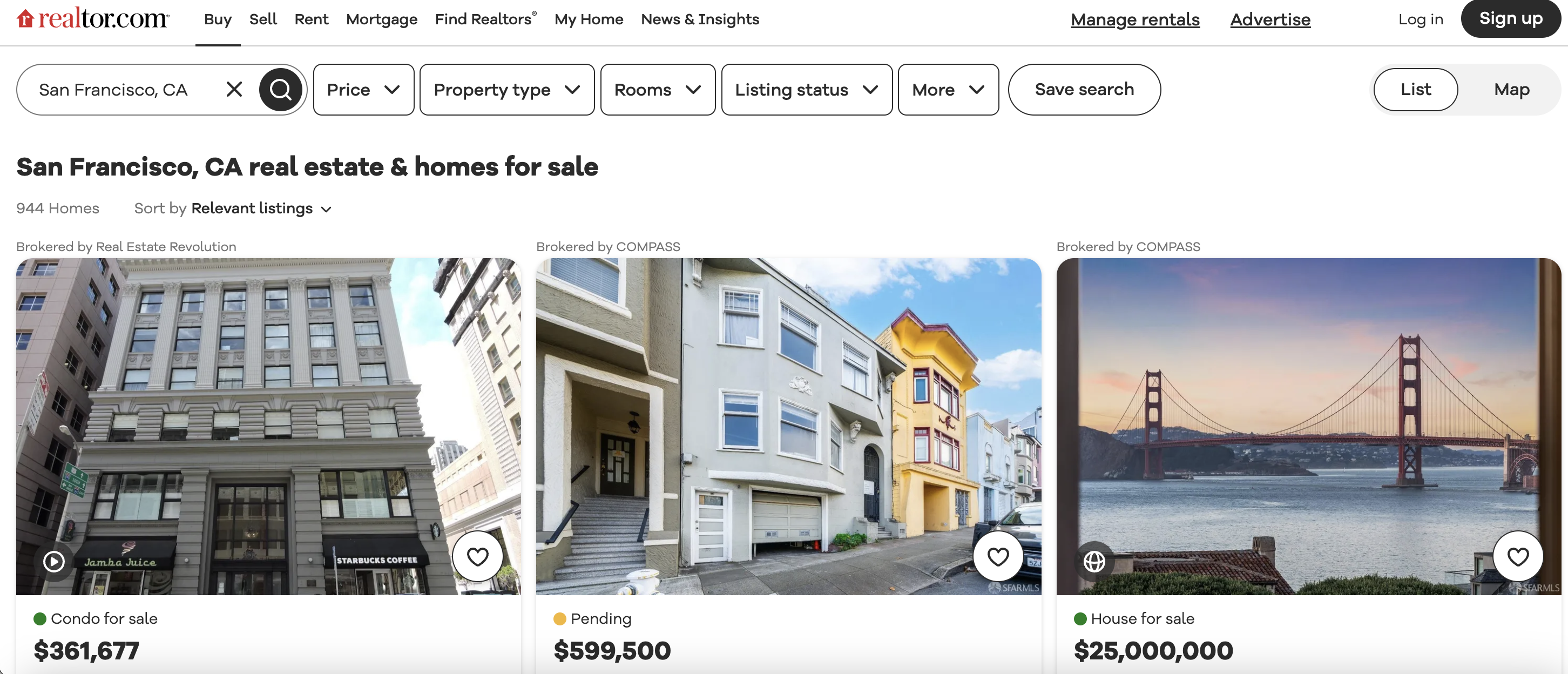
This is the listings page we are talking about…
Extracting Listing Data
The most complex part of this web scraping script is finding and extracting the specific data points about each real estate listing from the HTML.
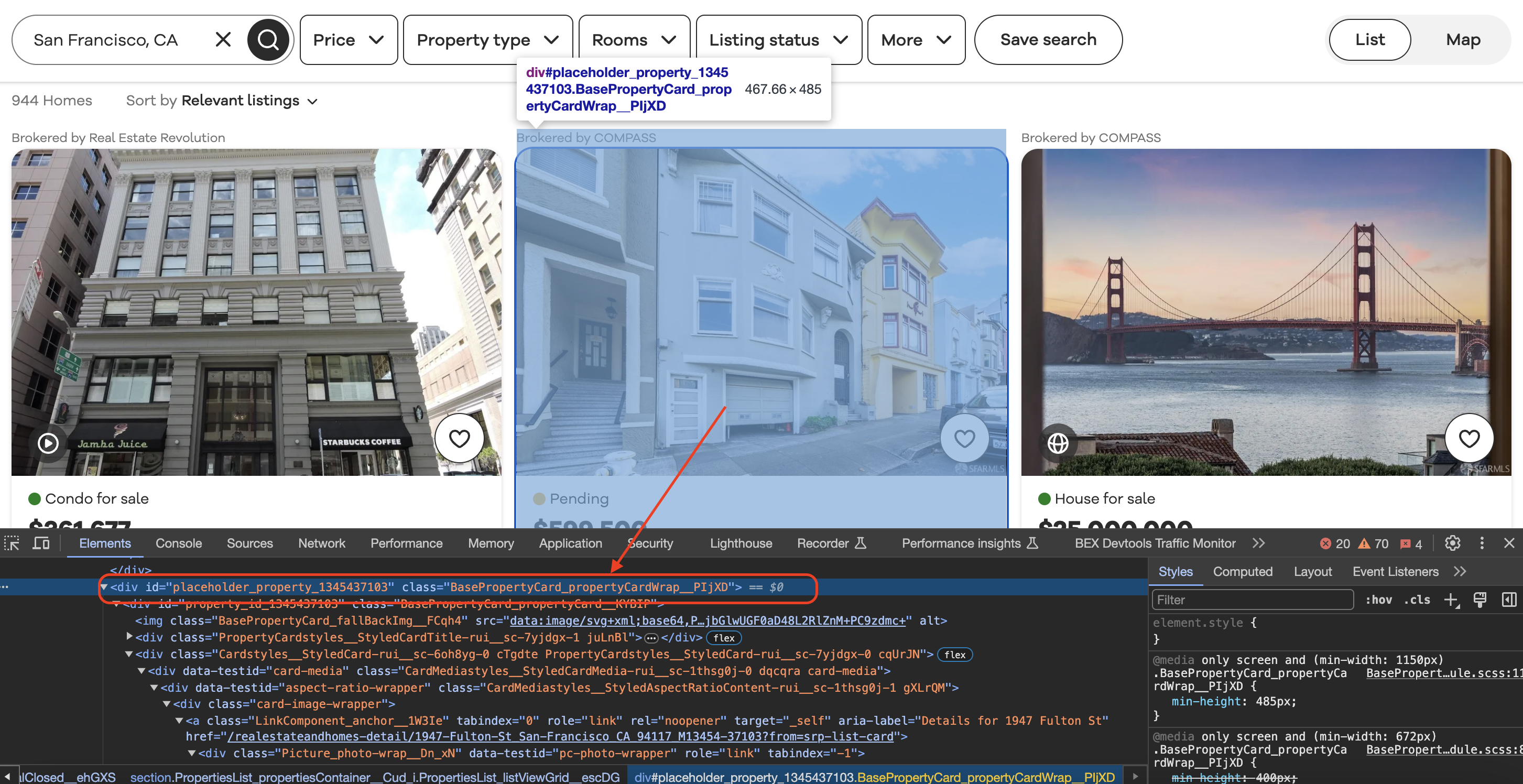
Inspecting the element
When we inspect element in Chrome we can see that each of the listing blocks is wrapped in a div with a class value as shown below…
Within the loop through each listing block, different HTML selectors are used to locate specific elements and extract their text. Let's break this down selector-by-selector:
Broker Name
The broker name is extracted with this selector:
div.BrokerTitle_brokerTitle___ZkbBW
This finds the outer The R code uses this selector and extracts the name text like: It first finds that broker The status (e.g. "For Sale") is extracted using: This selector finds the The R code extracts it simply: Finding that status The price selector is: Which locates the Extracted via: The key details like beds and baths use slightly more advanced selectors like: This finds The code checks if these elements exist before extracting their text: First finding that beds This pattern is followed for baths, square footage, lot size, and any other metadata elements. Finally, the address selector is simple: Finding the address And that covers all the key fields extracted for each listing! As you can see it relies heavily on using selectors to pinpoint very specific DOM elements and extract just the needed text. For reference, here is the full runnable scraper code:
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com" <!doctype html> Enter your email below to claim your free API key:broker_info <- html_node(listing_block, "div.BrokerTitle_brokerTitle___ZkbBW")
broker_name <- str_trim(html_text(html_node(broker_info, "span.BrokerTitle_titleText___20u1P")))
Status
div.message
status <- str_trim(html_text(html_node(listing_block, "div.message")))
Price
div.card-price
price <- str_trim(html_text(html_node(listing_block, "div.card-price")))
Beds, Baths etc.
li[data-testid='property-meta-beds']
beds_element <- html_node(listing_block, "li[data-testid='property-meta-beds']")
beds <- ifelse(!is.null(beds_element), str_trim(html_text(beds_element)), "N/A")
Address
div.card-address
address <- str_trim(html_text(html_node(listing_block, "div.card-address")))
Full Code
# Load necessary libraries
library(rvest)
library(stringr)
# Define the URL of the Realtor.com search page
url <- "https://www.realtor.com/realestateandhomes-search/San-Francisco_CA"
# Define a User-Agent header
user_agent <- "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
# Send a GET request to the URL with the User-Agent header
page <- read_html(url, user_agent(user_agent))
# Check if the request was successful (status code 200)
if (http_status(page)$status_code == 200) {
# Find all the listing blocks using the provided class name
listing_blocks <- html_nodes(page, "div.BasePropertyCard_propertyCardWrap__J0xUj")
# Loop through each listing block and extract information
for (listing_block in listing_blocks) {
# Extract the broker information
broker_info <- html_node(listing_block, "div.BrokerTitle_brokerTitle__ZkbBW")
broker_name <- str_trim(html_text(html_node(broker_info, "span.BrokerTitle_titleText__20u1P")))
# Extract the status (e.g., For Sale)
status <- str_trim(html_text(html_node(listing_block, "div.message")))
# Extract the price
price <- str_trim(html_text(html_node(listing_block, "div.card-price")))
# Extract other details like beds, baths, sqft, and lot size
beds_element <- html_node(listing_block, "li[data-testid='property-meta-beds']")
baths_element <- html_node(listing_block, "li[data-testid='property-meta-baths']")
sqft_element <- html_node(listing_block, "li[data-testid='property-meta-sqft']")
lot_size_element <- html_node(listing_block, "li[data-testid='property-meta-lot-size']")
# Check if the elements exist before extracting their text
beds <- ifelse(!is.null(beds_element), str_trim(html_text(beds_element)), "N/A")
baths <- ifelse(!is.null(baths_element), str_trim(html_text(baths_element)), "N/A")
sqft <- ifelse(!is.null(sqft_element), str_trim(html_text(sqft_element)), "N/A")
lot_size <- ifelse(!is.null(lot_size_element), str_trim(html_text(lot_size_element)), "N/A")
# Extract the address
address <- str_trim(html_text(html_node(listing_block, "div.card-address")))
# Print the extracted information
cat("Broker:", broker_name, "\n")
cat("Status:", status, "\n")
cat("Price:", price, "\n")
cat("Beds:", beds, "\n")
cat("Baths:", baths, "\n")
cat("Sqft:", sqft, "\n")
cat("Lot Size:", lot_size, "\n")
cat("Address:", address, "\n")
cat("-" * 50, "\n") # Separating listings
}
} else {
cat("Failed to retrieve the page. Status code:", http_status(page)$status_code, "\n")
}Browse by tags:
Browse by language:
The easiest way to do Web Scraping
Try ProxiesAPI for free
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...Don't leave just yet!