Have you ever wanted to automatically collect or analyze data from a website? Web scraping allows you to programmatically extract information from web pages - say, to grab article headlines from the New York Times homepage. It can be extremely useful for data science, journalistic research, market research, and more.
In this post, we'll walk through a full Rust program that scrapes titles and links from the NYTimes homepage. Along the way, we'll learn key concepts like:
Even if you're new to Rust, you'll see just how much you can accomplish. Let's get started!

Our Use Case
Why scrape the New York Times home page? We could imagine several scenarios:
The Times homepage actually changes quite frequently, with new stories cycling into the top headlines slot. Scraping allows us to capture snapshots programmatically.
There are certainly APIs and feeds that would enable some of this too - but rolling your own scraper opens up more possibilities!
Making a Request
We'll use the popular reqwest crate for making web requests.
use reqwest::{header::HeaderMap, StatusCode};
This gives us the main
Next we construct a "user agent" header to identify our scraper:
let headers = {
let mut custom_headers = HeaderMap::new();
custom_headers.insert("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36".parse()?);
custom_headers
};
This mimics a Chrome browser on Windows. Sites like the Times can block suspicious requests, so posing as a real browser helps ensure we get a proper response.
Now we can make the GET request:
let resp = reqwest::blocking::get("<https://www.nytimes.com/>")?.headers(headers).send()?;
We use the blocking API since this is a basic script. The
Checking the Response
It's good practice to verify the request was successful before trying to parse the response:
if resp.status() == StatusCode::OK {
// parsing logic here
} else {
println!("Failed with status: {}", resp.status());
}
This prints out any errors, avoiding confusion if our parser code runs but finds no data.
Parsing HTML
To extract information out of the HTML response, we'll use the very handy scraper crate.
We first get the response text and parse it into a structure
let body = resp.text()?;
let document = Html::parse_document(&body);
Inspecting the page
We now inspect element in chrome to see how the code is structured…
You can see that the articles are contained inside section tags and with the class story-wrapper
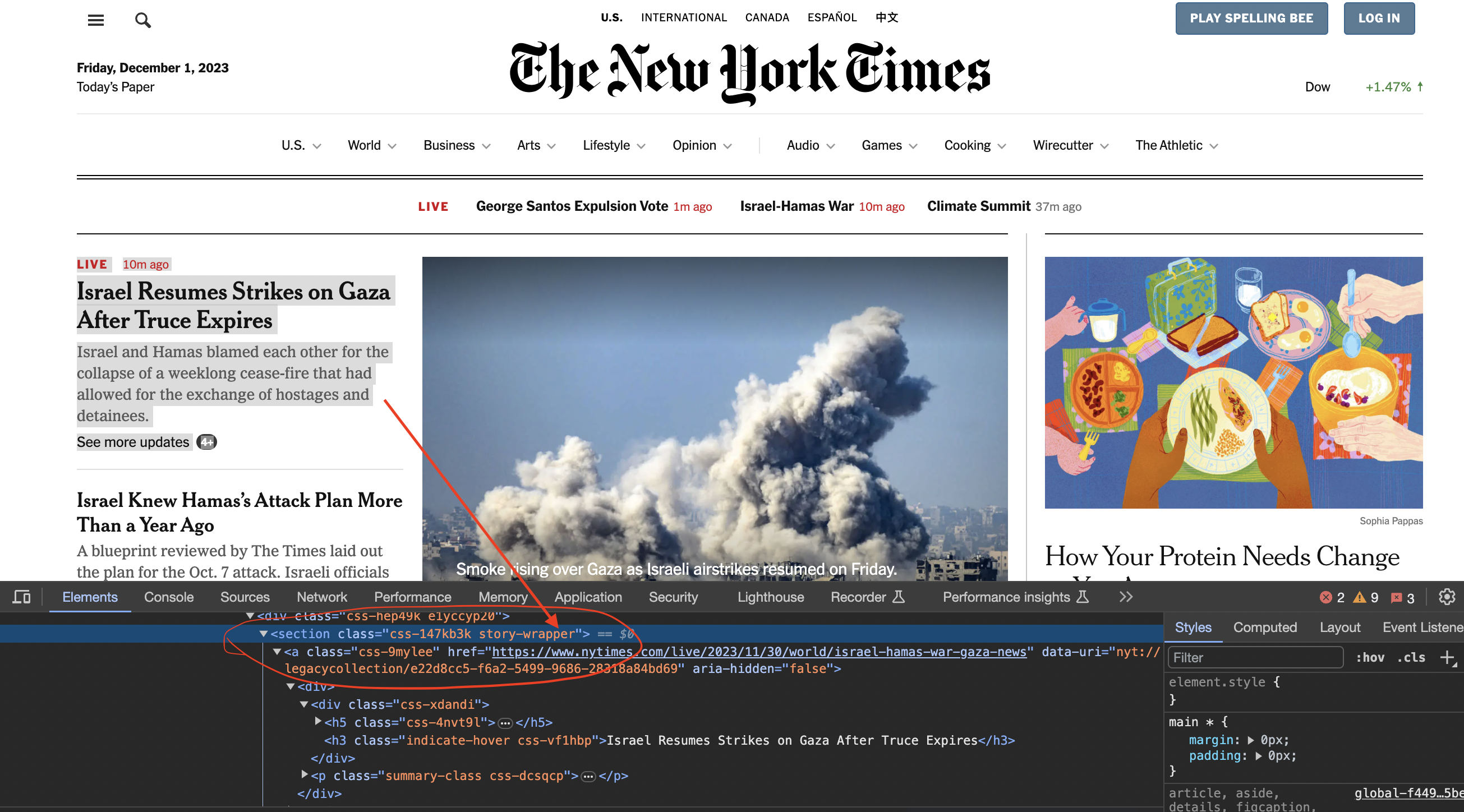
Now
let story_wrappers = Selector::parse(".story-wrapper").unwrap();
This targets the
for element in document.select(&story_wrappers) {
if let Some(title_element) = element.select(".indicate-hover").next() {
let article_title = title_element.text().collect::<String>();
article_titles.push(article_title);
}
if let Some(link_element) = element.select(".css-9mylee").next() {
let article_link = link_element.value().attr("href").unwrap().to_string();
article_links.push(article_link);
}
}
There's a bit going on here:
Finally, we can print the results!
Putting It All Together
Here is the full code:
use reqwest::{header::HeaderMap, StatusCode};
use scraper::{Html, Selector};
fn main() -> Result<(), reqwest::Error> {
// Building custom header
let headers = {
let mut custom_headers = HeaderMap::new();
custom_headers.insert("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36".parse()?);
custom_headers
};
// Making request
let resp = reqwest::blocking::get("<https://www.nytimes.com/>")?.headers(headers).send()?;
// Verifying response
if resp.status() == StatusCode::OK {
// Parsing logic here
let body = resp.text()?;
let document = Html::parse_document(&body);
let story_wrappers = Selector::parse(".story-wrapper").unwrap();
let mut article_titles = Vec::new();
let mut article_links = Vec::new();
for element in document.select(&story_wrappers) {
if let Some(title_element) = element.select(".indicate-hover").next() {
let article_title = title_element.text().collect::<String>();
article_titles.push(article_title);
}
if let Some(link_element) = element.select(".css-9mylee").next() {
let article_link = link_element.value().attr("href").unwrap().to_string();
article_links.push(article_link);
}
}
// Printing results
for i in 0..article_titles.len() {
println!("Title: {}", article_titles[i]);
println!("Link: {}", article_links[i]);
println!();
}
} else {
println!("Request failed with status: {}", resp.status());
}
Ok(())
}
And we're done! Running this prints out nice title and link pairs for the top stories.
There are lots more directions we could take this project - hopefully this gives you a solid starting point for your own Rust web scrapers!
Key Takeaways
In more advanced implementations you will need to even rotate the User-Agent string so the website cant tell its the same browser!
If we get a little bit more advanced, you will realize that the server can simply block your IP ignoring all your other tricks. This is a bummer and this is where most web crawling projects fail.
Overcoming IP Blocks
Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project which gets the job done consistently and one that never really works.
Plus with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.