Web scraping is a valuable skill for extracting data from websites, and it's essential for various applications, from data analysis to building web applications. In this beginner-friendly guide, we'll walk you through the process of web scraping using Objective-C. We'll use a practical example: scraping The New York Times website to extract article titles and links.
Prerequisites
Before we dive into the world of web scraping, you'll need the following:
Setting Up the Project
Let's start by setting up a new Xcode project. We'll create a new Objective-C file for our main code. Name it
Importing Libraries
In our Objective-C project, we need to import the necessary libraries to make web requests and parse HTML. We'll be using the
#import <Foundation/Foundation.h>
#import "HTMLReader.h"
Simulating a Browser Request
When scraping a website, it's crucial to simulate a browser request to avoid being blocked. We do this by setting a User-Agent header to make our request look like it's coming from a web browser. Here's how you define the User-Agent:
// Define a user-agent header to simulate a browser request
NSDictionary *headers = @{
@"User-Agent": @"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
};
Creating an NSURLSession
Next, we create an NSURLSession with custom headers to make our web request. This session will handle the HTTP request for us.
// Create an NSURLSession configuration with custom headers
NSURLSessionConfiguration *configuration = [NSURLSessionConfiguration defaultSessionConfiguration];
[configuration setHTTPAdditionalHeaders:headers];
// Create an NSURLSession with the custom configuration
NSURLSession *session = [NSURLSession sessionWithConfiguration:configuration];
Sending an HTTP GET Request
We send an HTTP GET request to the URL of the website we want to scrape. In our case, it's The New York Times website.
// Send an HTTP GET request to the URL
NSURLSessionDataTask *task = [session dataTaskWithURL:url completionHandler:^(NSData * _Nullable data, NSURLResponse * _Nullable response, NSError * _Nullable error) {
// Error handling and data parsing will be done here.
}];
This is the point where we send our request to the website. But what happens if something goes wrong? Let's address that next.
Error Handling
Error handling is crucial in web scraping. If something goes wrong, we need to know why and how to handle it. In our code, we check for errors like network issues or unsuccessful requests.
if (error) {
NSLog(@"Failed to retrieve the web page. Error: %@", error);
return;
}
if ([response isKindOfClass:[NSHTTPURLResponse class]]) {
NSHTTPURLResponse *httpResponse = (NSHTTPURLResponse *)response;
if (httpResponse.statusCode != 200) {
NSLog(@"Failed to retrieve the web page. Status code: %ld", (long)httpResponse.statusCode);
return;
}
}
We're now ready to parse the HTML content of the web page.
Parsing HTML Content
Parsing HTML is the heart of web scraping. We use the
// Parse the HTML content of the page
HTMLDocument *document = [HTMLDocument documentWithData:data contentTypeHeader:@"text/html; charset=utf-8"];
With the HTML content parsed, we can now extract the data we need.
Finding Article Sections
We want to extract article titles and links. To do this, we need to locate the HTML elements that contain this information on the web page.
Inspecting the page
We now inspect element in chrome to see how the code is structured…
You can see that the articles are contained inside section tags and with the class story-wrapper
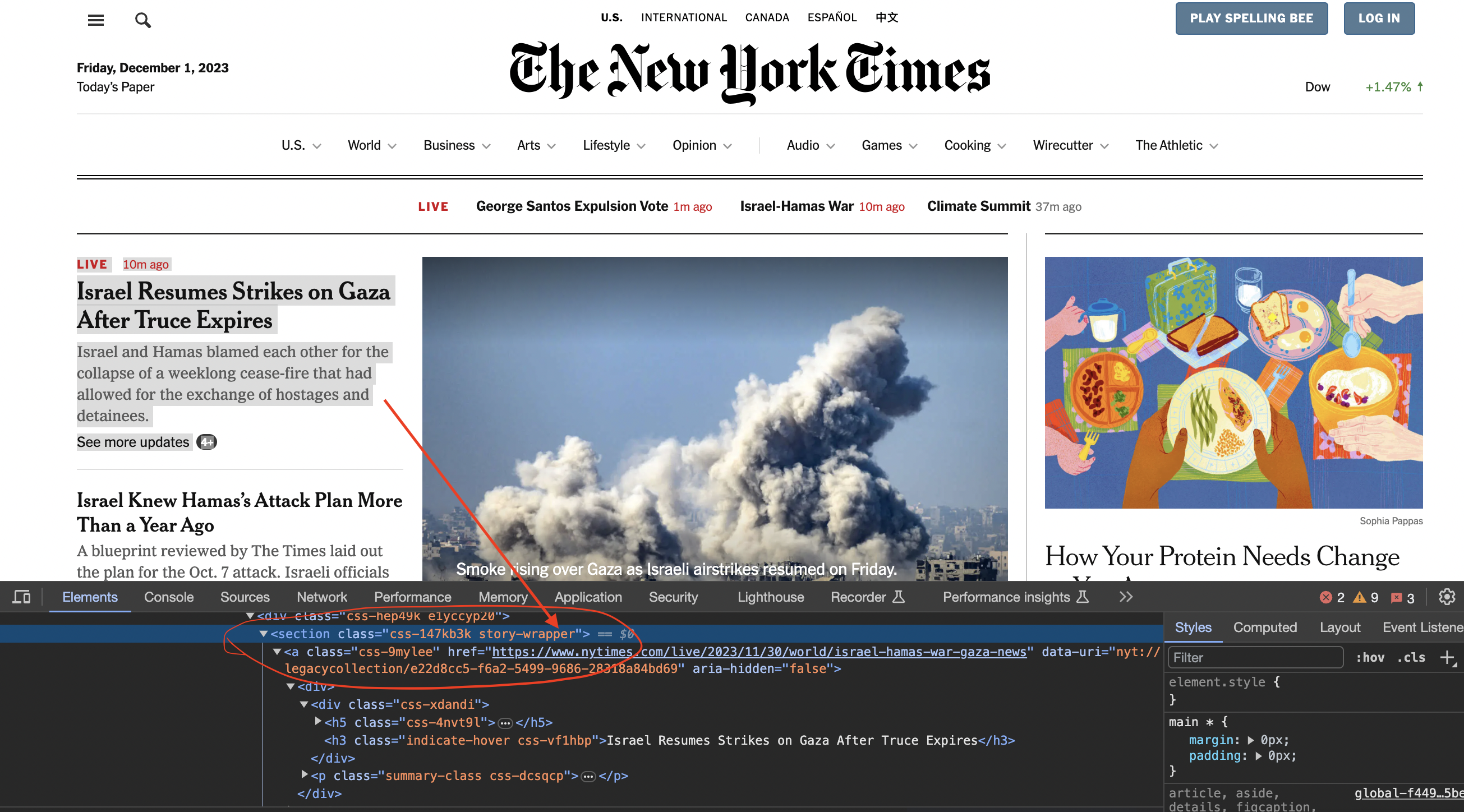
We'll use CSS selectors to find specific elements.
// Find all article sections with class 'story-wrapper'
NSArray *articleSections = [document nodesMatchingSelector:@".story-wrapper"];
Extracting Data
Now that we've identified the article sections, let's extract the article titles and links.
objectiveCopy code
// Initialize arrays to store the article titles and links
NSMutableArray *articleTitles = [NSMutableArray array];
NSMutableArray *articleLinks = [NSMutableArray array];
// Iterate through the article sections
for (HTMLElement *articleSection in articleSections) {
// Check if the article title element exists
HTMLElement *titleElement = [articleSection firstNodeMatchingSelector:@".indicate-hover"];
// Check if the article link element exists
HTMLElement *linkElement = [articleSection firstNodeMatchingSelector:@".css-9mylee"];
// If both title and link are found, extract and append
if (titleElement && linkElement) {
NSString *articleTitle = [titleElement textContent];
NSString *articleLink = [linkElement objectForKeyedSubscript:@"href"];
[articleTitles addObject:articleTitle];
[articleLinks addObject:articleLink];
}
}
Printing or Processing Data
At this point, you can choose to print the extracted data to the console or further process it based on your needs.
objectiveCopy code
// Print or process the extracted article titles and links
for (NSUInteger i = 0; i < articleTitles.count; i++) {
NSLog(@"Title: %@", articleTitles[i]);
NSLog(@"Link: %@", articleLinks[i]);
NSLog(@"\n");
}
Running the Code
Before you run the code, you'll need to start the NSURLSession task and run the NSRunLoop to keep the program alive while the request completes.
objectiveCopy code
// Start the NSURLSession task
[task resume];
// Run the NSRunLoop to keep the program alive while the request completes
[[NSRunLoop currentRunLoop] run];
Congratulations! You've successfully scraped The New York Times website for article titles and links using Objective-C.
Challenges and Considerations
Web scraping can be challenging due to website structure variations and anti-scraping mechanisms. Make sure to adapt your code as needed and handle unexpected situations gracefully.
Next Steps
Now that you've learned the basics of web scraping with Objective-C, you can:
Conclusion
Web scraping is a powerful tool for extracting data from websites, and Objective-C provides the tools needed to get the job done. Remember to always use web scraping responsibly and respect website policies and terms of use. Happy scraping!
Here's the full code for your reference:
objectiveCopy code
// Full code for web scraping The New York Times website
#import <Foundation/Foundation.h>
#import "HTMLReader.h"
int main(int argc, const char * argv[]) {
@autoreleasepool {
// URL of The New York Times website
NSString *urlString = @"https://www.nytimes.com/";
NSURL *url = [NSURL URLWithString:urlString];
// Define a user-agent header to simulate a browser request
NSDictionary *headers = @{
@"User-Agent": @"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
};
// Create an NSURLSession configuration with custom headers
NSURLSessionConfiguration *configuration = [NSURLSessionConfiguration defaultSessionConfiguration];
[configuration setHTTPAdditionalHeaders:headers];
// Create an NSURLSession with the custom configuration
NSURLSession *session = [NSURLSession sessionWithConfiguration:configuration];
// Send an HTTP GET request to the URL
NSURLSessionDataTask *task = [session dataTaskWithURL:url completionHandler:^(NSData * _Nullable data, NSURLResponse * _Nullable response, NSError * _Nullable error) {
if (error) {
NSLog(@"Failed to retrieve the web page. Error: %@", error);
return;
}
if ([response isKindOfClass:[NSHTTPURLResponse class]]) {
NSHTTPURLResponse *httpResponse = (NSHTTPURLResponse *)response;
if (httpResponse.statusCode != 200) {
NSLog(@"Failed to retrieve the web page. Status code: %ld", (long)httpResponse.statusCode);
return;
}
}
// Parse the HTML content of the page
HTMLDocument *document = [HTMLDocument documentWithData:data contentTypeHeader:@"text/html; charset=utf-8"];
// Find all article sections with class 'story-wrapper'
NSArray *articleSections = [document nodesMatchingSelector:@".story-wrapper"];
// Initialize arrays to store the article titles and links
NSMutableArray *articleTitles = [NSMutableArray array];
NSMutableArray *articleLinks = [NSMutableArray array];
// Iterate through the article sections
for (HTMLElement *articleSection in articleSections) {
// Check if the article title element exists
HTMLElement *titleElement = [articleSection firstNodeMatchingSelector:@".indicate-hover"];
// Check if the article link element exists
HTMLElement *linkElement = [articleSection firstNodeMatchingSelector:@".css-9mylee"];
// If both title and link are found, extract and append
if (titleElement && linkElement) {
NSString *articleTitle = [titleElement textContent];
NSString *articleLink = [linkElement objectForKeyedSubscript:@"href"];
[articleTitles addObject:articleTitle];
[articleLinks addObject:articleLink];
}
}
// Print or process the extracted article titles and links
for (NSUInteger i = 0; i < articleTitles.count; i++) {
NSLog(@"Title: %@", articleTitles[i]);
NSLog(@"Link: %@", articleLinks[i]);
NSLog(@"\n");
}
}];
// Start the NSURLSession task
[task resume];
// Run the NSRunLoop to keep the program alive while the request completes
[[NSRunLoop currentRunLoop] run];
}
return 0;
}
In more advanced implementations you will need to even rotate the User-Agent string so the website cant tell its the same browser!
If we get a little bit more advanced, you will realize that the server can simply block your IP ignoring all your other tricks. This is a bummer and this is where most web crawling projects fail.
Overcoming IP Blocks
Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project which gets the job done consistently and one that never really works.
Plus with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.