The New York Times publishes dozens of fresh news articles every day. As developers and data enthusiasts, we can leverage web scraping to automatically extract headlines and links from the NYT homepage.
In this beginner Perl tutorial, we'll walk through a script to scrape the NYT site from start to finish - no fancy modules or prior experience required. You'll learn:
Plus, you'll end up with a reusable Perl web scraper script for your own projects!
Our Scraping Game Plan
Here's the playbook for extracting NYT headlines programmatically:
- Send a Request: Use LWP::UserAgent to fetch the https://www.nytimes.com/ homepage HTML
- Parse the HTML: Leverage Mojo::DOM to navigate the HTML content
- Identify Data: Target article headers based on CSS selectors
- Extract Data: Grab the headline text and link URL
- Output Data: Print or process the scraped headlines
Next, let's walk through how to implement this plan in Perl.
Setting up LWP::UserAgent
We'll use the LWP::UserAgent module to mimic a browser request for the NYT homepage HTML content.
First let's fire up
use strict;
use warnings;
use LWP::UserAgent;
With the module loaded, we can instantiate a UserAgent object. This models an HTTP client:
my $user_agent = LWP::UserAgent->new();
We also want to spoof a real desktop browser user agent string. This increases the chance our request gets through any blocks on scraping:
my $user_agent = LWP::UserAgent->new(
agent => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
);
This passes a Google Chrome User Agent string to mimic.
Fetching the NYT Homepage Content
With our simulated browser prepped, fetching the NYTimes homepage HTML is a one-liner:
my $response = $user_agent->get('<https://www.nytimes.com/>');
This issues an HTTP GET request for the URL and returns a HTTP::Response object on success.
Let's add some error checking too:
if ($response->is_success) {
# Parsing logic here...
} else {
print "Failed to retrieve the web page";
}
Parsing the HTML Content
With the HTML content in hand, we can use Mojo::DOM to parse and traverse it.
First we'll load the DOM module:
use Mojo::DOM;
Then convert the HTML content into a Mojo::DOM object, which allows DOM query methods:
my $dom = Mojo::DOM->new($response->content);
Identifying Target Elements
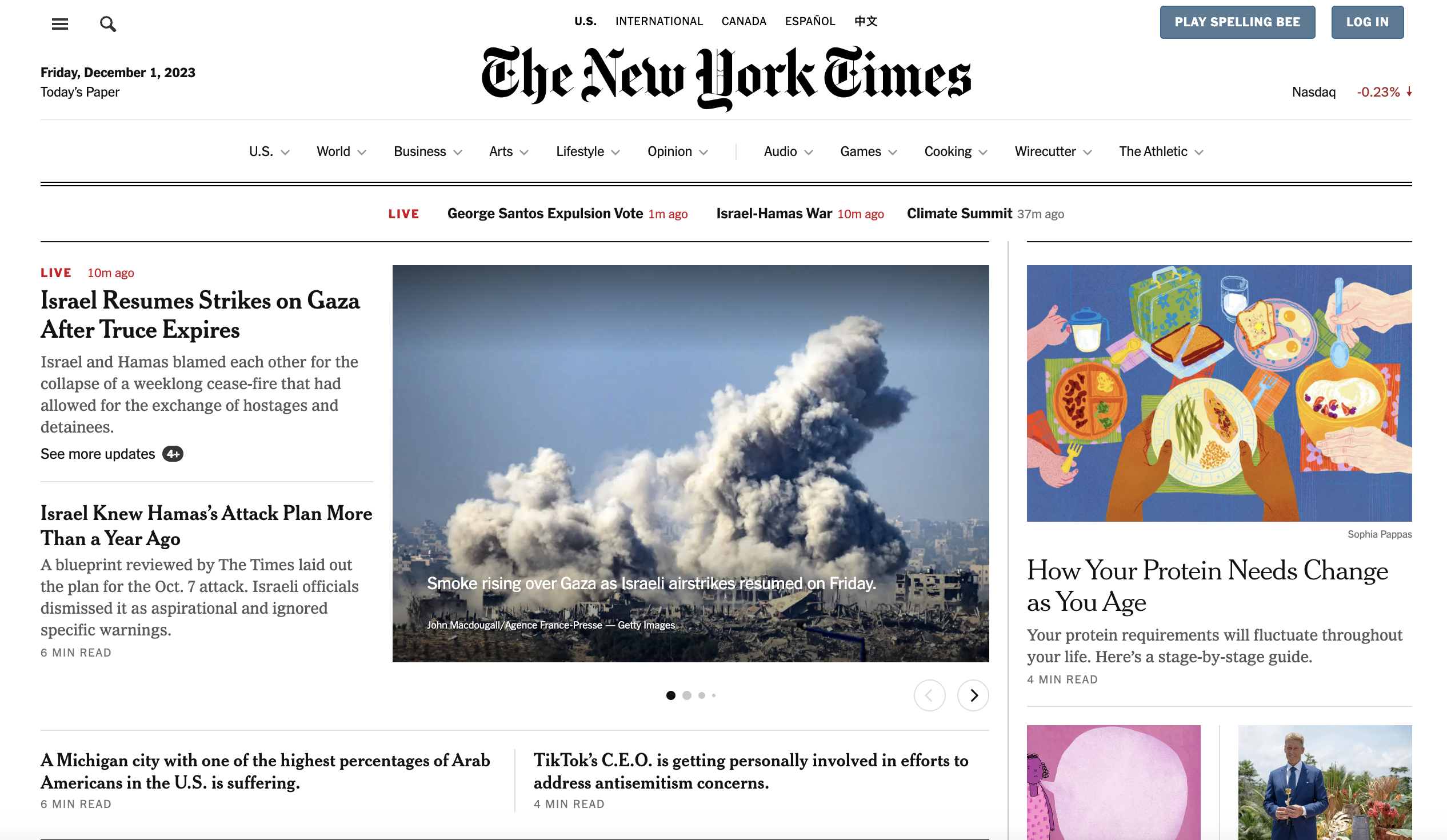
Looking at nytimes.com, we can see the headlines live within
Inspecting the page
We now inspect element in chrome to see how the code is structured…
You can see that the articles are contained inside section tags and with the class story-wrapper
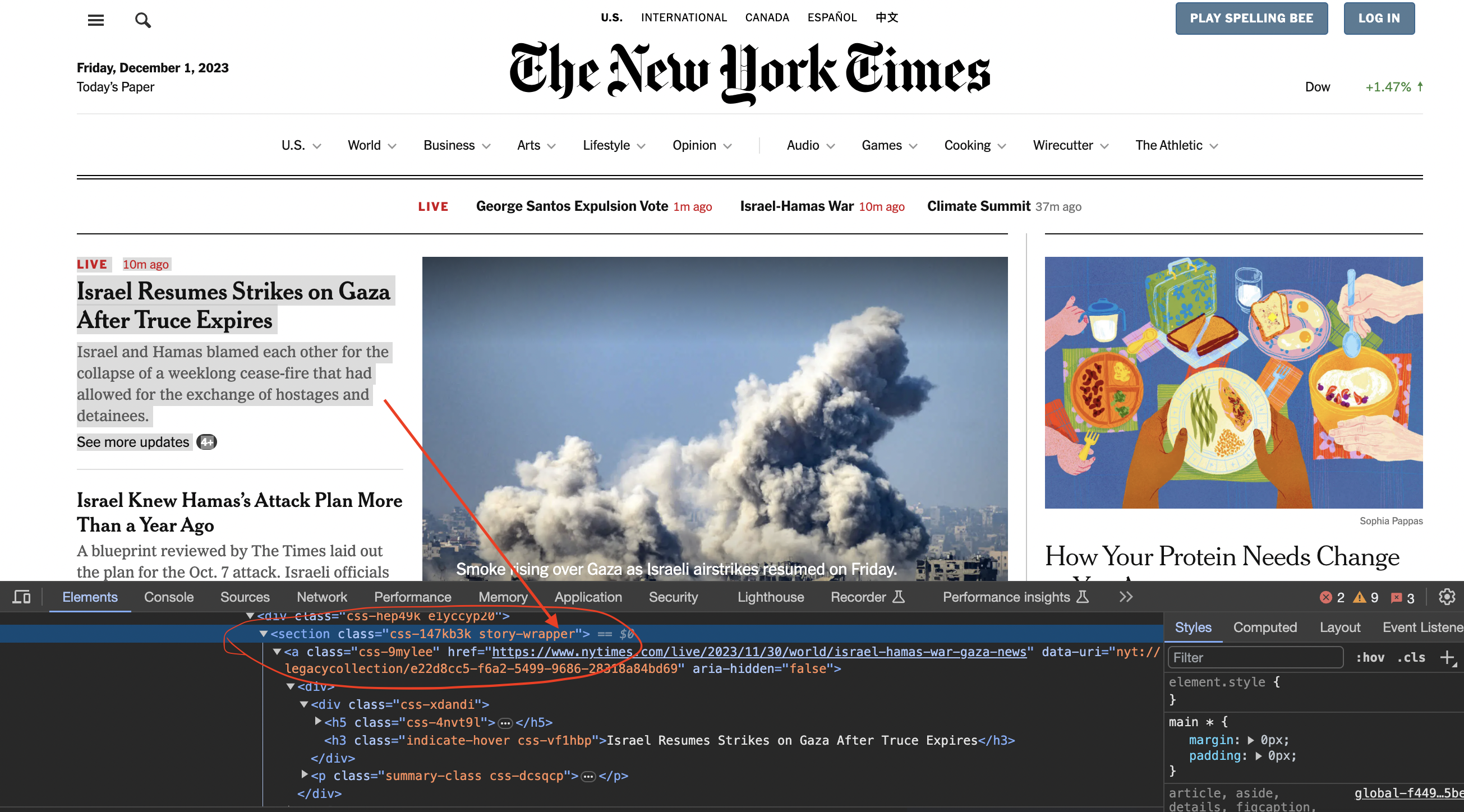
We can use this selector to grab each story section:
my @article_sections = $dom->find('section.story-wrapper')->each;
This finds all story sections, with
Extracting Headlines & Links
Now we can loop through the story sections and extract the headline text and link URL inside:
foreach my $article_section (@article_sections) {
my $title_element = $article_section->at('h3.indicate-hover');
my $link_element = $article_section->at('a.css-9mylee');
if ($title_element && $link_element) {
my $article_title = $title_element->text;
my $article_link = $link_element->attr('href');
print "Title: $article_title \\n";
print "Link: $article_link \\n\\n";
}
}
Here we:
And we've extracted the headline data!
Putting It All Together
The full script:
use strict;
use warnings;
use LWP::UserAgent;
use Mojo::DOM;
my $user_agent = LWP::UserAgent->new(
agent => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
);
my $response = $user_agent->get('<https://www.nytimes.com/>');
if ($response->is_success) {
my $dom = Mojo::DOM->new($response->content);
my @article_sections = $dom->find('section.story-wrapper')->each;
foreach my $article_section (@article_sections) {
my $title_element = $article_section->at('h3.indicate-hover');
my $link_element = $article_section->at('a.css-9mylee');
if ($title_element && $link_element) {
my $article_title = $title_element->text;
my $article_link = $link_element->attr('href');
print "Title: $article_title \\n";
print "Link: $article_link \\n\\n";
}
}
} else {
print "Failed to retrieve the web page";
}
And we've built a working NYT headline scraper from scratch!
The full code is available on GitHub as well.
Possible Next Steps
With the scraper logic down, here are ideas for extending it:
The core ideas of making requests, parsing HTML, and extracting data remain the same across most scraping projects.
Key Takeaways
Through building this NYT scraper, we learned:
In more advanced implementations you will need to even rotate the User-Agent string so the website cant tell its the same browser!
If we get a little bit more advanced, you will realize that the server can simply block your IP ignoring all your other tricks. This is a bummer and this is where most web crawling projects fail.
Overcoming IP Blocks
Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project which gets the job done consistently and one that never really works.
Plus with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.