Web scraping can be an intimidating topic for beginners, but it doesn't have to be! In this comprehensive guide, we'll walk through how to scrape article data from Hacker News using Objective-C and XML parsing.
Whether you're just getting started with web scraping or are new to Objective-C, I'll break things down step-by-step to help you better understand how everything works. By the end, you'll have the knowledge to start scraping Hacker News as well as the confidence to apply these learnings to your own web scraping projects.
This is the page we are talking about…
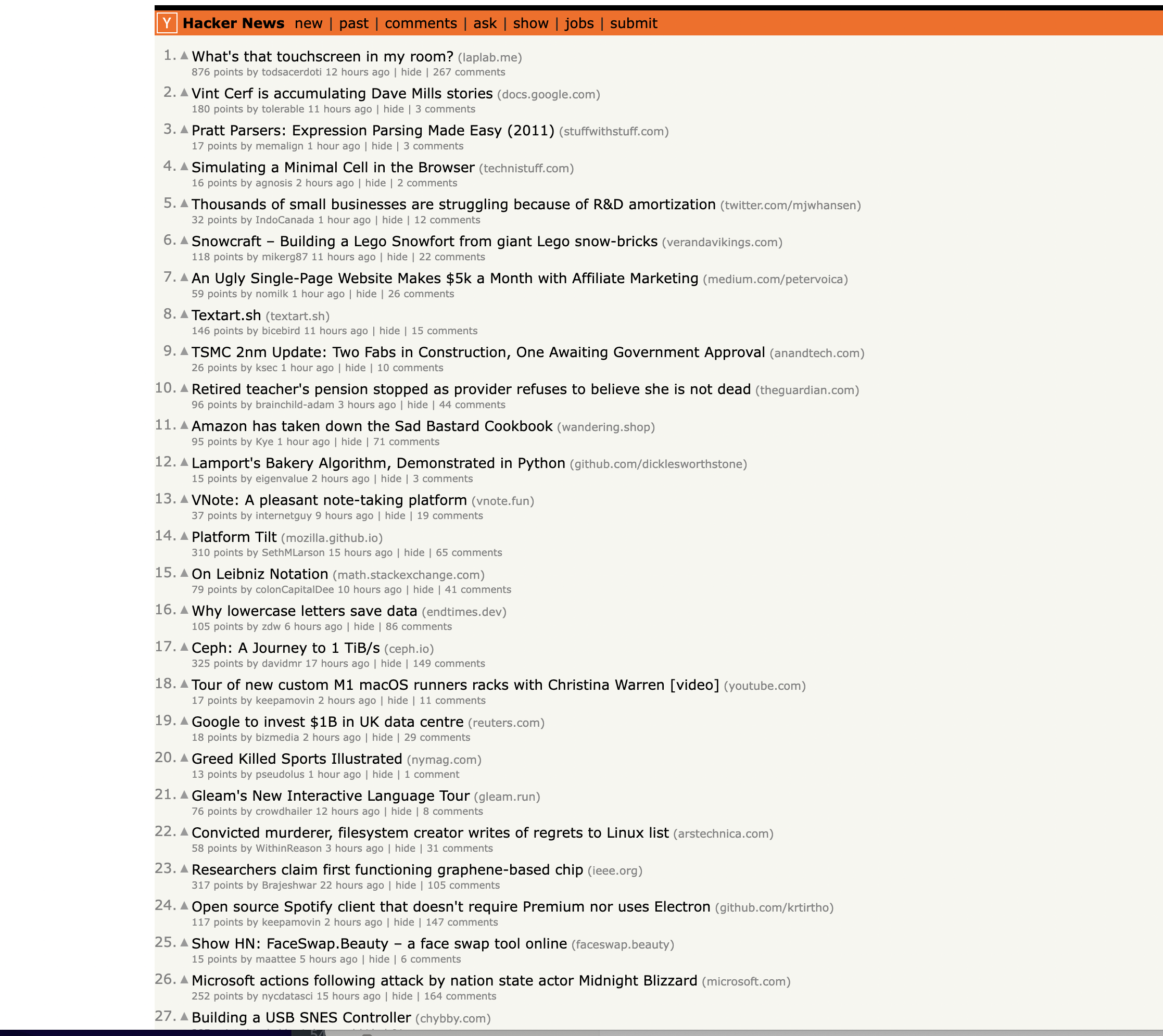
Let's get started!
Installation & Setup
Before we dive into the code, let's quickly get set up with the Apple frameworks we'll need for this scraping script:
Foundation Framework
The Foundation framework provides core data types we'll rely on like
XML Parsing
We'll use XML parsing libraries to process the HTML content returned by the Hacker News website. Xcode comes with a built-in XML parser we can initialize like so:
NSXMLDocument *document = [[NSXMLDocument alloc] initWithData:responseData options:NSXMLDocumentHTMLKind error:&error];
And that's it for setup! Just import Foundation and we're ready to start scraping.
Scraping Code Walkthrough
With the basics covered, let's dive into the code...
Define URL and Create Request
First we construct the URL pointing to the Hacker News homepage we want to scrape:
NSURL *url = [NSURL URLWithString:@"<https://news.ycombinator.com/>"];
Next we create the actual
NSURLRequest *request = [NSURLRequest requestWithURL:url];
This defines the destination URL. The request will return an HTML document.
Send Request and Receive Response
To send the request and download the Hacker News HTML content, we use:
NSData *responseData = [NSURLConnection sendSynchronousRequest:request returningResponse:nil error:nil];
This kicks off the request and saves the returned data into the
We also do some quick validation to make sure the request succeeded and data was returned:
if ([responseData length] > 0) {
// Data retrieved successfully!
} else {
// Request failed
}
So far, so good! We've requested and downloaded the raw HTML data from the Hacker News site. Now the real work begins...
Parsing the HTML Content
With the HTML stored in
Hacker News uses table rows to display articles, so we'll relied on XML parsing to loop through the rows and identify article data.
Initialize XML Parser
Let's initialize a parser which we can use to traverse and evaluate the HTML content:
NSXMLDocument *document = [[NSXMLDocument alloc] initWithData:responseData options:NSXMLDocumentHTMLKind error:&error];
Specifying
Find Table Rows with XPath
Inspecting the page
You can notice that the items are housed inside a With a configured parser, we can now start extracting data! Hacker News displays articles in table rows, so we grab those elements by using an XPath query: This gives us all XPath is a powerful querying language that allows us to extract elements by attributes, position, nesting and more. I'll cover some common techniques below. With all table rows selected, we loop through them to identify the ones containing article content: Leveraging the From there, we can pair the article row with the next row (containing metadata like votes, date, etc) to extract a complete article record. Now that we can identify article rows, let's look at how data is actually extracted. Say we have an article row stored in Title The title is nested in an URL The article URL is stored in the Points Here we: And so on for other fields like author, comments, etc! As you can see, XPath queries paired with I won't walk through every single field, but hopefully this gives you a framework for how scraping can be approached! Let's take one more high-level view of how everything connects before we conclude: And at the end you have programmatic access to scrape and manipulate web content! While it may seem daunting at first, by breaking things into smaller steps, web scraping become much more approachable. For easy reference, here is the full scraping script covered in this guide: This is great as a learning exercise but it is easy to see that even the proxy server itself is prone to get blocked as it uses a single IP. In this scenario where you may want a proxy that handles thousands of fetches every day using a professional rotating proxy service to rotate IPs is almost a must. Otherwise, you tend to get IP blocked a lot by automatic location, usage, and bot detection algorithms. Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly. Hundreds of our customers have successfully solved the headache of IP blocks with a simple API. The whole thing can be accessed by a simple API like below in any programming language. In fact, you don't even have to take the pain of loading Puppeteer as we render Javascript behind the scenes and you can just get the data and parse it any language like Node, Puppeteer or PHP or using any framework like Scrapy or Nutch. In all these cases you can just call the URL with render support like so: We have a running offer of 1000 API calls completely free. Register and get your free API Key.
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com" <!doctype html> Enter your email below to claim your free API key: tag with the class athing 
NSArray *rows = [document nodesForXPath:@"//tr" error:nil];
nodes to iterate through. Loop Through Rows to Identify Articles
for (NSXMLElement *row in rows) {
// Check if row marks an article
if ([[row attributeForName:@"class"] isEqualToString:@"athing"]) {
// This row represents an article
}
}
Extract Article Data
NSXMLElement *titleElem = [[currentArticle nodesForXPath:@"//span[@class='titleline']/a" error:nil] firstObject];
NSString *articleTitle = [titleElem stringValue];
NSString *articleURL = [[titleElem attributeForName:@"href"] stringValue];
NSXMLElement *subtext = [[row nodesForXPath:@"//td[@class='subtext']" error:nil] firstObject];
NSString *points = [[[subtext nodesForXPath:@"//span[@class='score']" error:nil] firstObject] stringValue];
in the row Putting It All Together
Full Code Sample
#import <Foundation/Foundation.h>
int main(int argc, const char * argv[]) {
@autoreleasepool {
// Define the URL of the Hacker News homepage
NSURL *url = [NSURL URLWithString:@"https://news.ycombinator.com/"];
// Create a URL request
NSURLRequest *request = [NSURLRequest requestWithURL:url];
// Send the request and receive the response
NSData *responseData = [NSURLConnection sendSynchronousRequest:request returningResponse:nil error:nil];
// Check if the request was successful (status code 200)
if ([responseData length] > 0) {
// Parse the HTML content using NSXMLDocument
NSError *error = nil;
NSXMLDocument *document = [[NSXMLDocument alloc] initWithData:responseData options:NSXMLDocumentHTMLKind error:&error];
if (document) {
// Find all rows in the table
NSArray *rows = [document nodesForXPath:@"//tr" error:nil];
// Initialize variables to keep track of the current article and row type
NSXMLElement *currentArticle = nil;
NSString *currentRowType = nil;
// Iterate through the rows to scrape articles
for (NSXMLElement *row in rows) {
// Check if this is an article row
if ([[row attributeForName:@"class"] stringValue] && [[[row attributeForName:@"class"] stringValue] isEqualToString:@"athing"]) {
currentArticle = row;
currentRowType = @"article";
} else if ([currentRowType isEqualToString:@"article"]) {
// This is the details row
if (currentArticle) {
// Extract information from the current article and details row
NSXMLElement *titleElem = [[currentArticle nodesForXPath:@"//span[@class='titleline']/a" error:nil] firstObject];
NSString *articleTitle = [titleElem stringValue];
NSString *articleURL = [[titleElem attributeForName:@"href"] stringValue];
NSXMLElement *subtext = [[row nodesForXPath:@"//td[@class='subtext']" error:nil] firstObject];
NSString *points = [[[subtext nodesForXPath:@"//span[@class='score']" error:nil] firstObject] stringValue];
NSString *author = [[[subtext nodesForXPath:@"//a[@class='hnuser']" error:nil] firstObject] stringValue];
NSString *timestamp = [[[subtext nodesForXPath:@"//span[@class='age']/@title" error:nil] firstObject] stringValue];
NSXMLElement *commentsElem = [[subtext nodesForXPath:@"//a[contains(text(),'comments')]" error:nil] firstObject];
NSString *comments = [commentsElem stringValue] ?: @"0";
// Print the extracted information
NSLog(@"Title: %@", articleTitle);
NSLog(@"URL: %@", articleURL);
NSLog(@"Points: %@", points);
NSLog(@"Author: %@", author);
NSLog(@"Timestamp: %@", timestamp);
NSLog(@"Comments: %@", comments);
NSLog(@"--------------------------------------------------");
}
// Reset the current article and row type
currentArticle = nil;
currentRowType = nil;
}
}
} else {
NSLog(@"Failed to parse HTML document. Error: %@", [error localizedDescription]);
}
} else {
NSLog(@"Failed to retrieve the page.");
}
}
return 0;
}curl "<http://api.proxiesapi.com/?key=API_KEY&render=true&url=https://example.com>"
Browse by language:
The easiest way to do Web Scraping
Try ProxiesAPI for free
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...Don't leave just yet!