Hacker News is a popular tech news aggregator where users post links to interesting articles, blog posts, projects, and more. As an avid reader of Hacker News, you may have wondered if there was a way to programmatically scrape articles from the site. In this tutorial, we'll walk through Elixir code to scrape the top headlines from the Hacker News homepage.
This is the page we are talking about…
Overview
We'll use the Elixir programming language along with a few helper libraries to:
- Make an HTTP request to retrieve the Hacker News homepage HTML
- Parse the HTML content using a parser called Floki
- Extract specific elements from the parsed content to get article titles, points, authors etc.
- Print out the extracted information
The full code is provided at the end of this article so you can use it yourself.
Let's get started!
Install Elixir
If you don't already have Elixir installed, you can install it by following the instructions on the official Elixir site. Make sure you have a recent version installed (at least Elixir 1.11).
Create an Elixir Project
Start a new project using the
mix new hacker_news
This will generate a simple project structure for us to work in.
Install Dependencies
Our code imports a few helper libraries:
Let's grab these by adding them to
[
{:httpoison, "~> 1.8"},
{:floki, "~> 0.31.0"}
]
Now run
Making HTTP Requests
The first thing our scraper does is make an HTTP GET request to retrieve the homepage HTML content:
HTTPoison.get(@url)
The
{:ok, %HTTPoison.Response{...}}
This response contains the status code and body of the page if the request succeeded. We pattern match on the tuple to handle different cases:
case HTTPoison.get(@url) do
{:ok, %HTTPoison.Response{status_code: 200, body: body}} ->
# Request succeeded
{:ok, %HTTPoison.Response{status_code: code}} ->
# Request failed
{:error, reason} ->
# Error making request
end
For a status code of 200, the body contains the raw HTML we want to parse.
Parsing HTML with Floki
Floki provides a nice API for searching HTML documents using CSS selectors. We can parse the entire body using:
doc = Floki.parse_document(body)
This builds a tree structure representing elements like Inspecting the page You can notice that the items are housed inside a The Hacker News homepage displays articles in a table. We want to iterate through each First find all rows: Then we can loop through them: There are a few types of rows we care about: We check When we hit an article row, we save a reference to that element: On the next iteration when we reach the details row, we can now connect it to the article title and extract additional metadata like points, comments etc. The key thing to note here are the CSS selectors. For example: This finds the We continue this process, using very precise selectors targeted small elements to cleanly extract each data field we need. The full code ties together: With some helpful error handling added as well. Here is the complete scraper: Save this code into a file like You should see scraped headlines print out! This is great as a learning exercise but it is easy to see that even the proxy server itself is prone to get blocked as it uses a single IP. In this scenario where you may want a proxy that handles thousands of fetches every day using a professional rotating proxy service to rotate IPs is almost a must. Otherwise, you tend to get IP blocked a lot by automatic location, usage, and bot detection algorithms. Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly. Hundreds of our customers have successfully solved the headache of IP blocks with a simple API. The whole thing can be accessed by a simple API like below in any programming language. In fact, you don't even have to take the pain of loading Puppeteer as we render Javascript behind the scenes and you can just get the data and parse it any language like Node, Puppeteer or PHP or using any framework like Scrapy or Nutch. In all these cases you can just call the URL with render support like so: We have a running offer of 1000 API calls completely free. Register and get your free API Key.
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com" <!doctype html> Enter your email below to claim your free API key:,
, etc. that we can now query. Scraping Rows from the Table
tag with the class athing 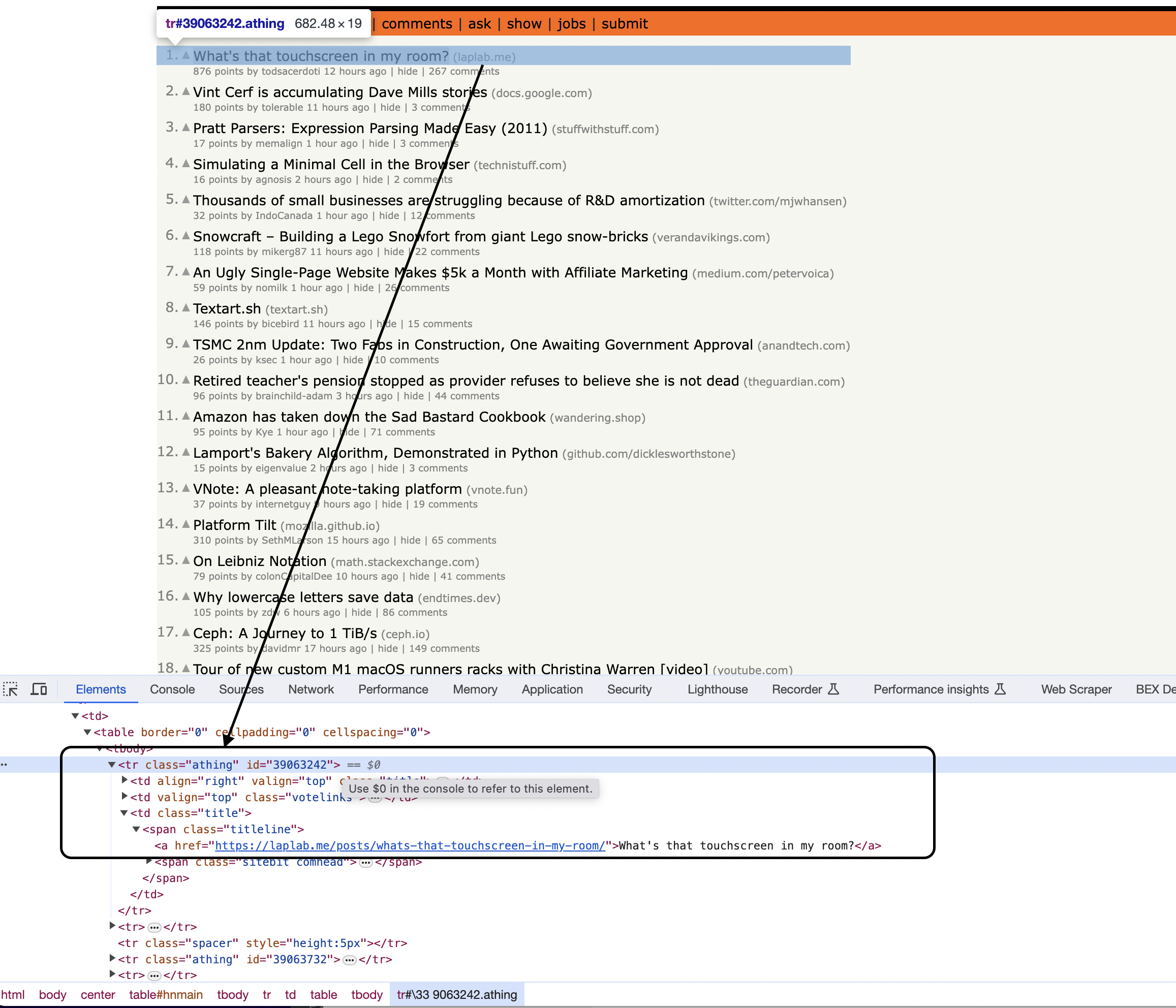
row and extract data. rows = Floki.find(doc, "tr")
Enum.each(rows, fn row ->
# extract data from each row
end)
Extracting Article Data
if Floki.attribute(row, "class") == ["athing"] do
current_article = row
end
elsif current_row_type == "article" do
if current_article do
# Extract article title
title_elem = Floki.find(current_article, "span.titleline a")
article_title = Floki.text(title_elem)
# Extract article URL
article_url = Floki.attribute(title_elem, "href")
# Get subtext details row
subtext = Floki.find(row, "td.subtext")
# Extract points
points = Floki.text(Floki.find(subtext, "span.score"))
# Extract author
author = Floki.text(Floki.find(subtext, "a.hnuser"))
# Extract timestamp
timestamp = Floki.attribute(Floki.find(subtext, "span.age"), "title")
# Extract comment count
comments_elem = Floki.find(subtext, "a:contains('comments')")
comments = if comments_elem, do: Floki.text(comments_elem), else: "0"
# Print out extracted data
IO.puts("Title: #{article_title}")
IO.puts("URL: #{@url <> article_url}")
IO.puts("Points: #{points}")
IO.puts("Author: #{author}")
IO.puts("Timestamp: #{timestamp}")
IO.puts("Comments: #{comments}")
end
end
span.titleline a
Putting It All Together
defmodule HackerNewsScraper do
@url "https://news.ycombinator.com/"
def scrape do
case HTTPoison.get(@url) do
{:ok, %HTTPoison.Response{status_code: 200, body: body}} ->
# Parse the HTML content of the page using Floki
doc = Floki.parse_document(body)
# Find all rows in the table
rows = Floki.find(doc, "tr")
# Initialize variables to keep track of the current article and row type
current_article = nil
current_row_type = nil
# Iterate through the rows to scrape articles
Enum.each(rows, fn row ->
if Floki.attribute(row, "class") == ["athing"] do
# This is an article row
current_article = row
current_row_type = "article"
elsif current_row_type == "article" do
# This is the details row
if current_article do
# Extract information from the current article and details row
title_elem = Floki.find(current_article, "span.titleline a")
article_title = Floki.text(title_elem)
article_url = Floki.attribute(title_elem, "href")
subtext = Floki.find(row, "td.subtext")
points = Floki.text(Floki.find(subtext, "span.score"))
author = Floki.text(Floki.find(subtext, "a.hnuser"))
timestamp = Floki.attribute(Floki.find(subtext, "span.age"), "title")
comments_elem = Floki.find(subtext, "a:contains('comments')")
comments = if comments_elem, do: Floki.text(comments_elem), else: "0"
# Print the extracted information
IO.puts("Title: #{article_title}")
IO.puts("URL: #{@url <> article_url}")
IO.puts("Points: #{points}")
IO.puts("Author: #{author}")
IO.puts("Timestamp: #{timestamp}")
IO.puts("Comments: #{comments}")
IO.puts(String.duplicate("-", 50))
end
# Reset the current article and row type
current_article = nil
current_row_type = nil
elsif Floki.attribute(row, "style") == "height:5px" do
# This is the spacer row, skip it
:ok
else
# Other types of rows, skip them
:ok
end
end)
{:ok, %HTTPoison.Response{status_code: code}} ->
IO.puts("Failed to retrieve the page. Status code: #{code}")
{:error, reason} ->
IO.puts("Failed to make the HTTP request. Reason: #{reason}")
end
end
end
# Run the scraper
HackerNewsScraper.scrape()$ elixir lib/scraper.ex
curl "<http://api.proxiesapi.com/?key=API_KEY&render=true&url=https://example.com>"
Browse by language:
The easiest way to do Web Scraping
Try ProxiesAPI for free
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...Don't leave just yet!