This Java code scrapes article titles, URLs, points, authors, timestamps, and comment counts from the Hacker News homepage. By the end, you'll understand how to use Jsoup and CSS selectors to extract information from an HTML page.
This is the page we are talking about…
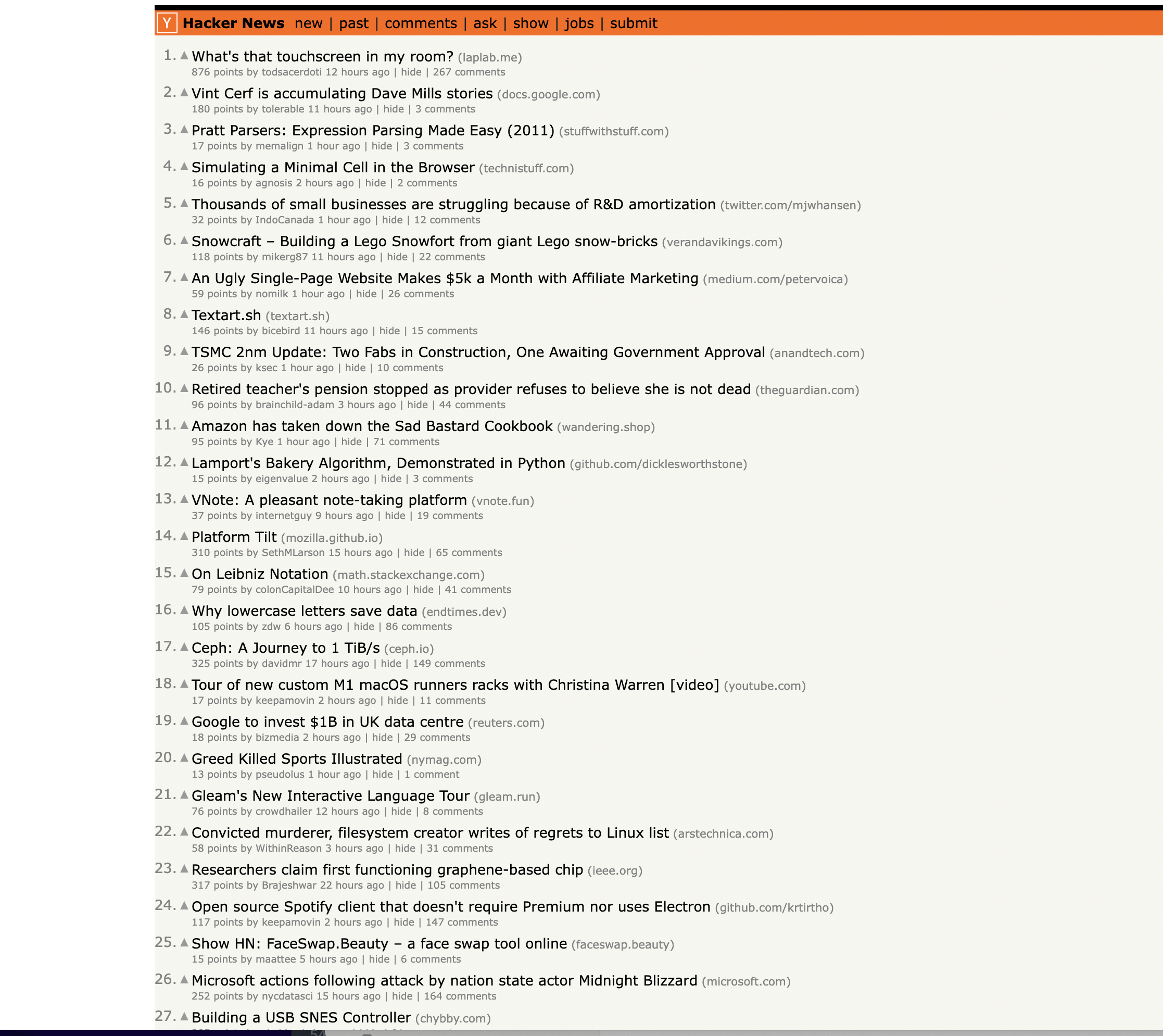
Let's get started!
Prerequisites
To run this web scraper, you need:
Walkthrough of Code
We first import Jsoup and some helpful classes:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
In the main method, we define the Hacker News homepage URL:
String url = "<https://news.ycombinator.com/>";
We send a GET request with Jsoup to retrieve and parse the page HTML:
Document doc = Jsoup.connect(url).get();
The
Inspecting the page
You can notice that the items are housed inside a Next, we select all We use two variables to track state as we iterate through rows: We loop through the rows: Inside the loop, we first check if row has "athing" class - indicating it's an article row: If so, we save the row to Next, we check if previous row type was "article", meaning current row holds article details: Inside this conditional, we extract article data if Let's break this down: Finally, we reset the state variables and check if row is a spacer row to skip. Full code: This is great as a learning exercise but it is easy to see that even the proxy server itself is prone to get blocked as it uses a single IP. In this scenario where you may want a proxy that handles thousands of fetches every day using a professional rotating proxy service to rotate IPs is almost a must. Otherwise, you tend to get IP blocked a lot by automatic location, usage, and bot detection algorithms. Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly. Hundreds of our customers have successfully solved the headache of IP blocks with a simple API. The whole thing can be accessed by a simple API like below in any programming language. In fact, you don't even have to take the pain of loading Puppeteer as we render Javascript behind the scenes and you can just get the data and parse it any language like Node, Puppeteer or PHP or using any framework like Scrapy or Nutch. In all these cases you can just call the URL with render support like so: We have a running offer of 1000 API calls completely free. Register and get your free API Key.
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com" <!doctype html> Enter your email below to claim your free API key: tag with the class athing 
table rows on the page: Elements rows = doc.select("tr");
Element currentArticle = null;
String currentRowType = null;
for (Element row : rows) {
// row processing code
}
if (row.hasClass("athing")) {
currentArticle = row;
currentRowType = "article";
}
} else if ("article".equals(currentRowType)) {
// Extract article data from currentArticle
}
if (currentArticle != null) {
// Extract title
Element titleElem = currentArticle.selectFirst("span.titleline");
String articleTitle = titleElem.selectFirst("a").text();
// Extract URL
String articleUrl = titleElem.selectFirst("a").attr("href");
// Extract points, author, timestamp, comments
Element subtext = row.selectFirst("td.subtext");
String points = subtext.selectFirst("span.score").text();
String author = subtext.selectFirst("a.hnuser").text();
String timestamp = subtext.selectFirst("span.age").attr("title");
Element commentsElem = subtext.selectFirst("a:contains(comments)");
String comments = commentsElem != null ? commentsElem.text() : "0";
// Print extracted data
System.out.println("Title: " + articleTitle);
// ...
}
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class HackerNewsScraper {
public static void main(String[] args) {
// Define the URL of the Hacker News homepage
String url = "https://news.ycombinator.com/";
try {
// Send a GET request to the URL and parse the HTML content
Document doc = Jsoup.connect(url).get();
// Find all rows in the table
Elements rows = doc.select("tr");
// Initialize variables to keep track of the current article and row type
Element currentArticle = null;
String currentRowType = null;
// Iterate through the rows to scrape articles
for (Element row : rows) {
if (row.hasClass("athing")) {
// This is an article row
currentArticle = row;
currentRowType = "article";
} else if ("article".equals(currentRowType)) {
// This is the details row
if (currentArticle != null) {
// Extract information from the current article and details row
Element titleElem = currentArticle.selectFirst("span.titleline");
if (titleElem != null) {
String articleTitle = titleElem.selectFirst("a").text(); // Get the text of the anchor element
String articleUrl = titleElem.selectFirst("a").attr("href"); // Get the href attribute of the anchor element
Element subtext = row.selectFirst("td.subtext");
String points = subtext.selectFirst("span.score").text();
String author = subtext.selectFirst("a.hnuser").text();
String timestamp = subtext.selectFirst("span.age").attr("title");
Element commentsElem = subtext.selectFirst("a:contains(comments)");
String comments = commentsElem != null ? commentsElem.text() : "0";
// Print the extracted information
System.out.println("Title: " + articleTitle);
System.out.println("URL: " + articleUrl);
System.out.println("Points: " + points);
System.out.println("Author: " + author);
System.out.println("Timestamp: " + timestamp);
System.out.println("Comments: " + comments);
System.out.println("-".repeat(50)); // Separating articles
}
}
// Reset the current article and row type
currentArticle = null;
currentRowType = null;
} else if ("height:5px".equals(row.attr("style"))) {
// This is the spacer row, skip it
continue;
}
}
} catch (IOException e) {
System.err.println("Failed to retrieve the page. Error: " + e.getMessage());
}
}
}curl "<http://api.proxiesapi.com/?key=API_KEY&render=true&url=https://example.com>"
Browse by language:
The easiest way to do Web Scraping
Try ProxiesAPI for free
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...Don't leave just yet!