eBay is one of the largest online marketplaces with millions of active listings at any given time. In this tutorial, we'll walk through how to scrape and extract key data from eBay listings using Python and the BeautifulSoup library.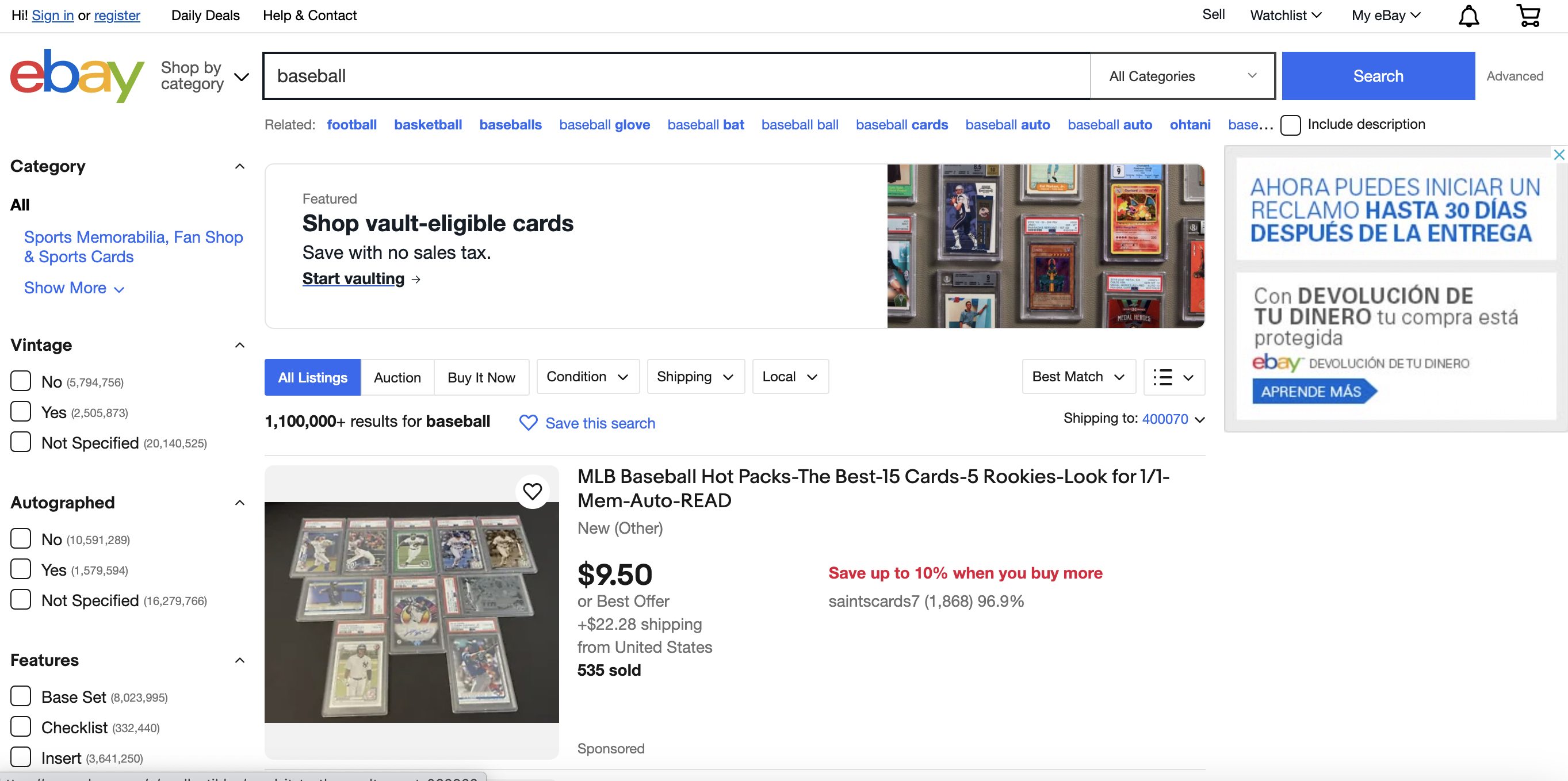
Setup
We'll need the following libraries installed:
You can install these using pip:
pip install requests beautifulsoup4
We'll also define the starting eBay URL to scrape and a dictionary of headers to spoof a browser visit:
import requests
from bs4 import BeautifulSoup
url = "<https://www.ebay.com/sch/i.html?_from=R40&_trksid=p2334524.m570.l1313&_nkw=baseball&_sacat=64482&LH_TitleDesc=0>"
headers = {"User-Agent": "Mozilla/5.0..."}
Replace the User-Agent with your own browser's user agent string.
Fetch the Listings Page
We'll use the requests library to fetch the HTML content from the eBay URL:
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "lxml")
The headers dictionary is passed to spoof a browser visit. We use the BeautifulSoup parser with the lxml parser to parse the HTML.
Extract Listing Data
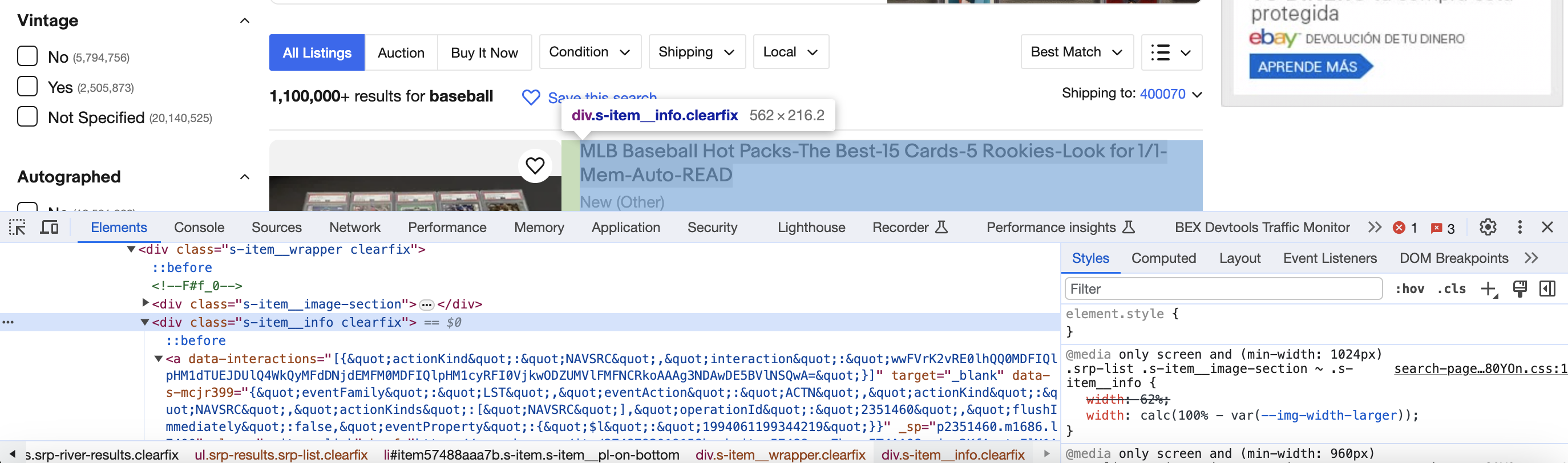
Now we can extract the key data points from each listing. eBay encloses each listing in a Then we can loop through each listing We use Finally, we can print out all the extracted info for each listing: This will output each listing's title, url, price and other data in a readable format. Here is the full code to scrape and extract eBay listing data: This gives you an overview of how to use Python and BeautifulSoup to extract data from eBay listings. The key steps are sending a request, parsing the HTML, finding the listing divs, and extracting the text from tags based on their class names.
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com" <!doctype html> Enter your email below to claim your free API key:listing_items = soup.find_all("div", class_="s-item__info clearfix")
for item in listing_items:
title = item.find("div", class_="s-item__title").text.strip()
url = item.find("a", class_="s-item__link")["href"]
price = item.find("span", class_="s-item__price").text.strip()
# And so on for other fields like seller, shipping, location etc.
Print Results
print("Title:", title)
print("URL:", url)
print("Price:", price)
print("="*50) # Separator between listings
Full Code
import requests
from bs4 import BeautifulSoup
url = "https://www.ebay.com/sch/i.html?_nkw=baseball"
headers = {"User-Agent": "Mozilla/5.0..."}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "lxml")
listing_items = soup.find_all("div", class_="s-item__info clearfix")
for item in listing_items:
title = item.find("div", class_="s-item__title").text.strip()
url = item.find("a", class_="s-item__link")["href"]
price = item.find("span", class_="s-item__price").text.strip()
details = item.find("div", class_="s-item__subtitle").text.strip()
seller_info = item.find("span", class_="s-item__seller-info-text").text.strip()
shipping_cost = item.find("span", class_="s-item__shipping").text.strip()
location = item.find("span", class_="s-item__location").text.strip()
sold = item.find("span", class_="s-item__quantity-sold").text.strip()
print("Title:", title)
print("URL:", url)
print("Price:", price)
print("Details:", details)
print("Seller:", seller_info)
print("Shipping:", shipping_cost)
print("Location:", location)
print("Sold:", sold)
print("="*50)Browse by tags:
Browse by language:
The easiest way to do Web Scraping
Try ProxiesAPI for free
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...Don't leave just yet!