This article will explain how to scrape Craigslist apartment listings using Rust and the reqwest and selectors crates. We will go through each line to understand what it is doing.
First add reqwest and selectors to Cargo.toml:
[dependencies]
reqwest = "0.11"
selectors = "0.22"
Include them in main.rs:
use reqwest;
use selectors;
Reqwest handles HTTP requests. Selectors parses HTML/XML.
Next we set the URL to scrape - Craigslist SF apartments:
let url = "<https://sfbay.craigslist.org/search/apa>";
Make the HTTP request and get the response text:
let resp = reqwest::get(url)?.text()?;
Parse the HTML with Selectors:
let doc = selectors::Document::from(resp.as_str());
If you check the source code of Craigslist listings you can see that the listings area code looks something like this…
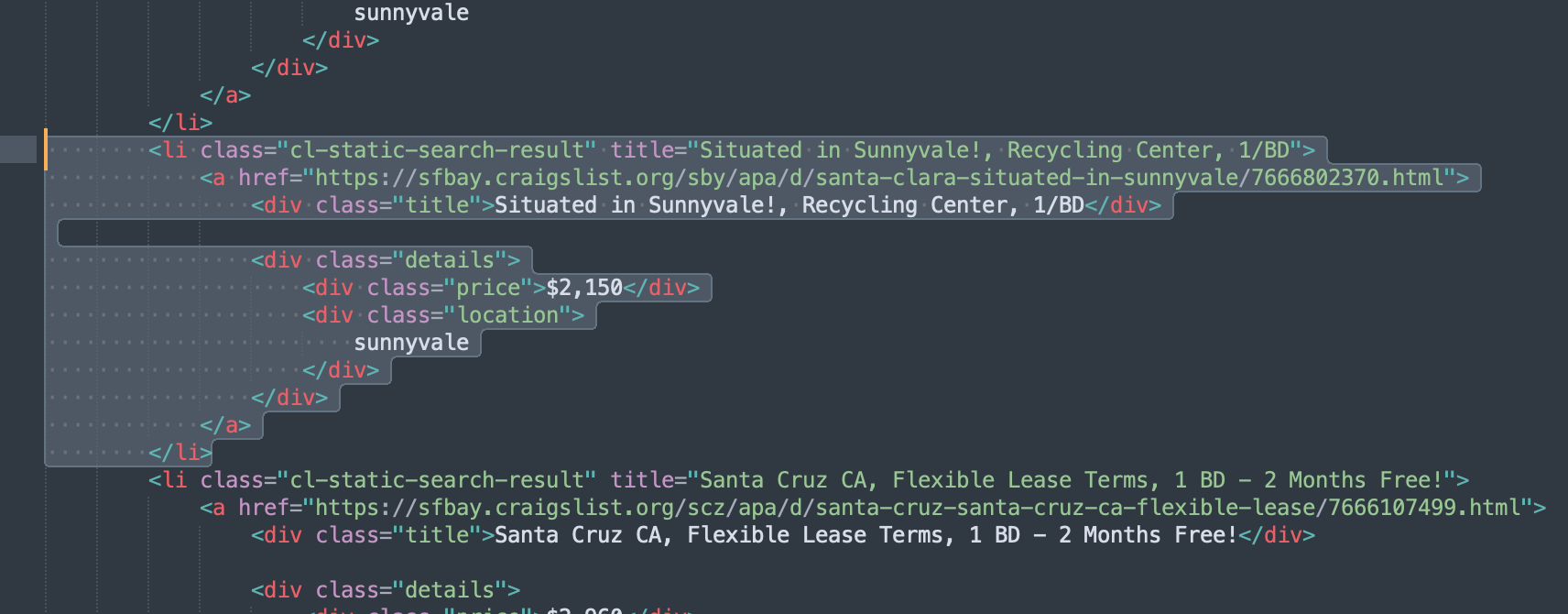
You can see the code block that generates the listing…
<li class="cl-static-search-result" title="Situated in Sunnyvale!, Recycling Center, 1/BD">
<a href="https://sfbay.craigslist.org/sby/apa/d/santa-clara-situated-in-sunnyvale/7666802370.html">
<div class="title">Situated in Sunnyvale!, Recycling Center, 1/BD</div>
<div class="details">
<div class="price">$2,150</div>
<div class="location">
sunnyvale
</div>
</div>
</a>
</li>its encapsulated in the cl-static-search-result class. We also need to get the title class div and the price and location class divs to get all the data
Get all listings:
let listings = doc.find(selectors::Selector::parse("li.cl-static-search-result").unwrap());
Loop through listings to extract info:
for listing in listings {
let title = listing.find(selectors::Selector::parse(".title").unwrap()).text();
let price = listing.find(selectors::Selector::parse(".price").unwrap()).text();
let location = listing.find(selectors::Selector::parse(".location").unwrap()).text();
let link = listing.find(selectors::Selector::parse("a").unwrap()).get_attribute("href");
println!("{} {} {} {}", title, price, location, link);
}
The full Rust code is:
use reqwest;
use selectors;
let url = "<https://sfbay.craigslist.org/search/apa>";
let resp = reqwest::get(url)?.text()?;
let doc = selectors::Document::from(resp.as_str());
let listings = doc.find(selectors::Selector::parse("li.cl-static-search-result").unwrap());
for listing in listings {
let title = listing.find(selectors::Selector::parse(".title").unwrap()).text();
let price = listing.find(selectors::Selector::parse(".price").unwrap()).text();
let location = listing.find(selectors::Selector::parse(".location").unwrap()).text();
let link = listing.find(selectors::Selector::parse("a").unwrap()).get_attribute("href");
println!("{} {} {} {}", title, price, location, link);
}
This walks through the Rust code to scrape Craigslist listings. Let me know if any part needs clarification!