In this article, we will learn how to scrape property listings from Booking.com using R. We will use libraries like rvest and httr to fetch the HTML content and parse/extract details like property name, location, ratings etc.
Prerequisites
To follow along, you will need:
Loading Libraries
Load the required libraries:
library(rvest)
library(httr)
rvest for parsing HTML and httr for sending HTTP requests.
Defining URL
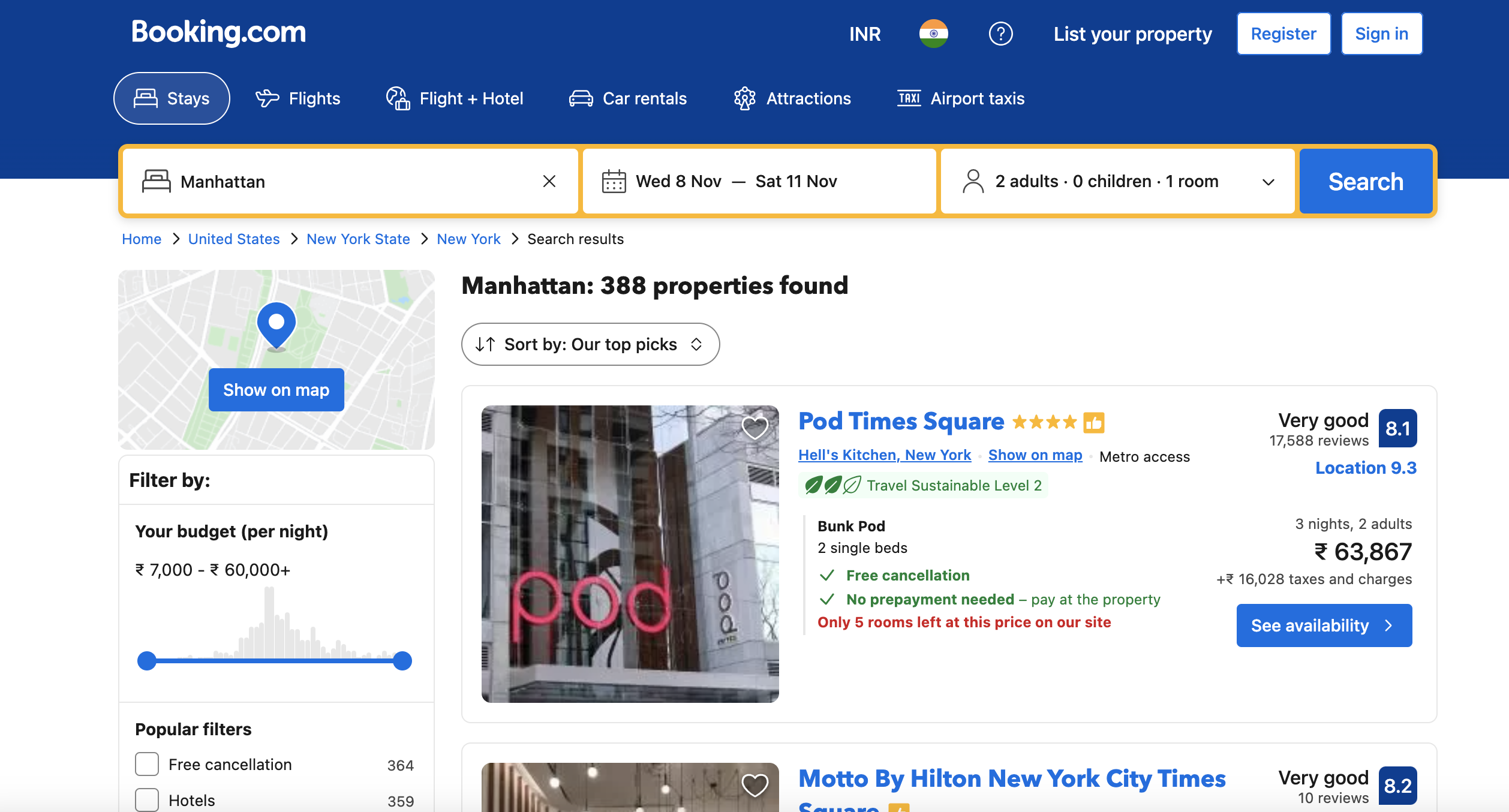
—
Define the target URL:
url <- "<https://www.booking.com/searchresults.en-gb.html?ss=New+York&checkin=2023-03-01&checkout=2023-03-05&group_adults=2>"
Setting User Agent
Set a valid User Agent string:
user_agent <- "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
Fetching HTML Page
Use httr to send GET request:
headers <- c(User_Agent = user_agent)
response <- httr::GET(url, httr::add_headers(.headers=headers))
html <- content(response, "text")
We configure the user agent and fetch the HTML page.
Parsing HTML
Read HTML using rvest:
page <- read_html(html)
Extracting Cards
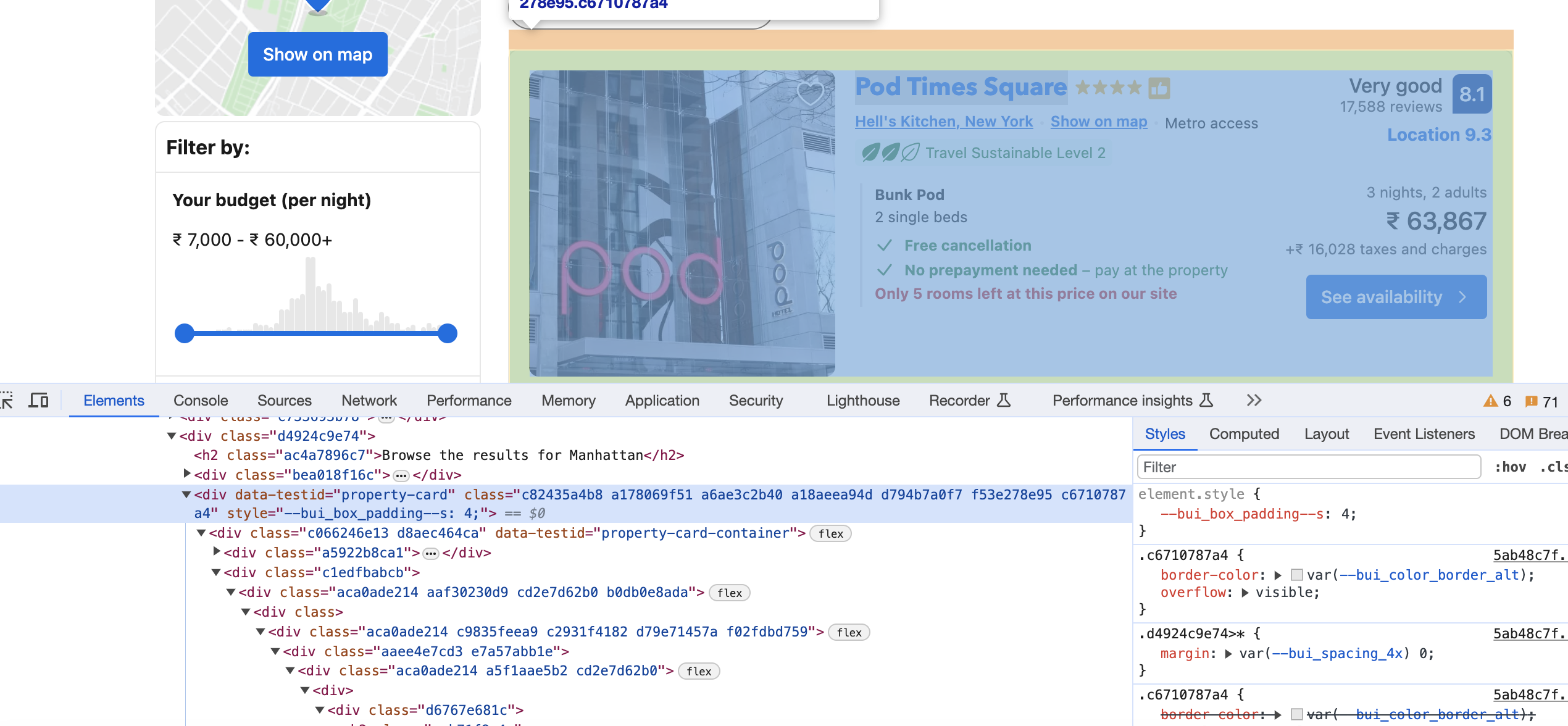
Get elements with data-testid attribute:
cards <- html_nodes(page, "div[data-testid='property-card']")
This extracts the property cards.
Processing Each Card
Loop through the cards:
for (card in cards) {
# Extract data from card
}
Inside we can extract details from each
Extracting Title
Get h3 text:
title <- html_text(html_node(card, "h3"))
Extracting Location
Get address span text:
location <- html_text(html_node(card, "span[data-testid='address']"))
Extracting Rating
Get aria-label attribute value:
rating <- html_attr(html_node(card, "div.e4755bbd60"), "aria-label")
Filter by class.
Extracting Review Count
Get div text:
review_count <- html_text(html_node(card, "div.abf093bdfe"))
Extracting Description
Get description div text:
description <- html_text(html_node(card, "div.d7449d770c"))
Printing Output
Print the extracted data:
print(paste("Title:", title))
print(paste("Location:", location))
print(paste("Rating:", rating))
print(paste("Review Count:", review_count))
print(paste("Description:", description))
Full Script
Here is the complete R scraping script:
library(rvest)
library(httr)
url <- "<https://www.booking.com/searchresults.en-gb.html?ss=New+York&checkin=2023-03-01&checkout=2023-03-05&group_adults=2>"
user_agent <- "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
headers <- c(User_Agent = user_agent)
response <- httr::GET(url, httr::add_headers(.headers=headers))
html <- content(response, "text")
page <- read_html(html)
cards <- html_nodes(page, "div[data-testid='property-card']")
for (card in cards) {
title <- html_text(html_node(card, "h3"))
location <- html_text(html_node(card, "span[data-testid='address']"))
rating <- html_attr(html_node(card, "div.e4755bbd60"), "aria-label")
review_count <- html_text(html_node(card, "div.abf093bdfe"))
description <- html_text(html_node(card, "div.d7449d770c"))
print(paste("Title:", title))
print(paste("Location:", location))
print(paste("Rating:", rating))
print(paste("Review Count:", review_count))
print(paste("Description:", description))
}
This extracts key data from Booking.com listings using R. The same technique can be applied to any website.
While these examples are great for learning, scraping production-level sites can pose challenges like CAPTCHAs, IP blocks, and bot detection. Rotating proxies and automated CAPTCHA solving can help.
Proxies API offers a simple API for rendering pages with built-in proxy rotation, CAPTCHA solving, and evasion of IP blocks. You can fetch rendered pages in any language without configuring browsers or proxies yourself.
This allows scraping at scale without headaches of IP blocks. Proxies API has a free tier to get started. Check out the API and sign up for an API key to supercharge your web scraping.
With the power of Proxies API combined with Python libraries like Beautiful Soup, you can scrape data at scale without getting blocked.