This Go program scrapes all dog breed images from a Wikipedia page and saves them to a local folder.
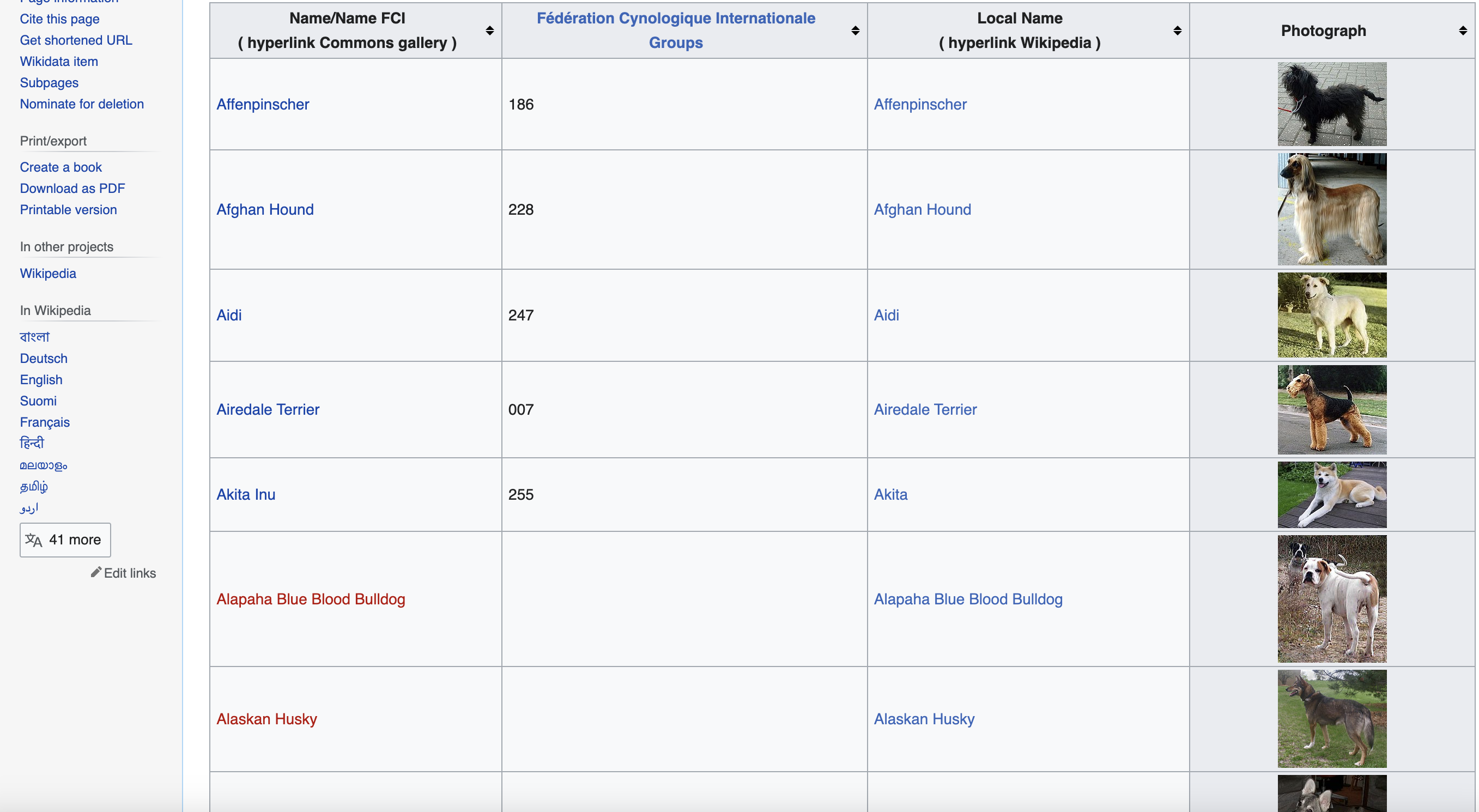
This is page we are talking about…
Prerequisites
To run this web scraping code, you will need:
Now let's walk through what the code is doing step-by-step:
Main Function and Variables
First we import the necessary Go packages:
import (
"fmt"
"os"
"io/ioutil"
"net/http"
"github.com/PuerkitoBio/goquery"
)
Then we define the main function where the scraping logic resides:
func main() {
}
Inside main, we define some variables:
// URL of the Wikipedia page
url := "<https://commons.wikimedia.org/wiki/List_of_dog_breeds>"
// Headers to simulate a browser
headers := map[string]string{
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
}
// HTTP client with custom headers
client := &http.Client{}
Sending the HTTP Request
We create a GET request to the Wikipedia URL defined earlier:
req, err := http.NewRequest("GET", url, nil)
We attach the custom headers to simulate a browser:
for key, value := range headers {
req.Header.Set(key, value)
}
Finally, we use the HTTP client to send the request and get the response:
// Send the request
resp, err := client.Do(req)
We also check that the status code is 200 to confirm success.
Parsing the HTML
To extract data, we first need to parse the HTML content from the response. We use the goquery package:
// Parse HTML
doc, err := goquery.NewDocumentFromReader(resp.Body)
This parses the entire HTML document into a structure we can query using CSS selectors.
Finding the Data Table
Inspecting the page
You can see when you use the chrome inspect tool that the data is in a table element with the class wikitable and sortable
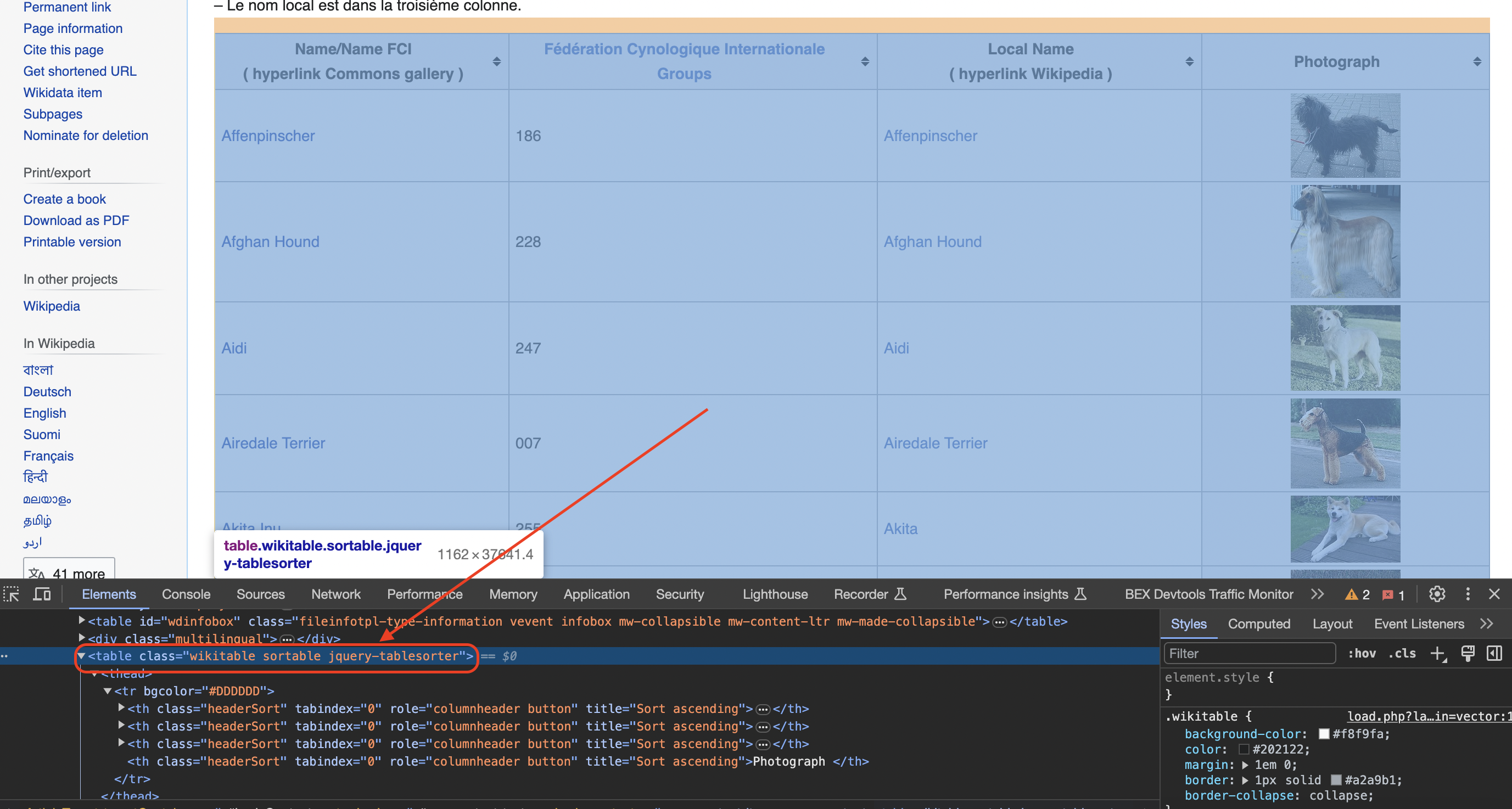
We use this class to find the table element:
// Find the data table
table := doc.Find(".wikitable.sortable")
Initializing Data Slices
To store all the extracted data, we define empty slices of strings:
// Slices to store data
names := []string{}
groups := []string{}
localNames := []string{}
photographs := []string{}
We will append the scraped data to these slices later.
Creating Local Image Folder
We also want to save the images locally, so we create a folder called "dog_images":
// Create folder for images
os.Mkdir("dog_images", os.ModePerm)
Extracting Data from Rows
Now we iterate through each row, skipping the header:
table.Find("tr").Each(func(index int, rowHtml *goquery.Selection) {
if index > 0 {
// extract data from each row
}
})
Inside this loop, we find and extract the data from each table cell:
// Get cells
columns := rowHtml.Find("td, th")
// Extract data
name := columns.Eq(0).Find("a").Text()
group := columns.Eq(1).Text()
localName := columns.Eq(2).Find("span").Text()
Some key points on understanding the selectors:
This is how we extract the name, group, and local name for each breed.
Downloading images uses a similar approach:
// Check for image
imgTag := columns.Eq(3).Find("img")
// Get image source URL
photograph, _ := imgTag.Attr("src")
// Download image
if photograph != "" {
// download code
}
We find the
Saving Data
After extracting each field in the row, we append it to our slices:
// Append data to slices
names = append(names, name)
groups = append(groups, group)
// ...
This accumulates all the data.
Printing Extracted Data
Finally, we can print out or process the data as needed:
for i := 0; i < len(names); i++ {
fmt.Println("Name:", names[i])
fmt.Println("Group:", groups[i])
// ...
}
This prints each breed's name, group, local name, and image URL that we extracted earlier.
The full code downloads and saves all images as well.
Summary
In this article we covered:
You can build on this to scrape any site using Go and goquery! Some ideas for next steps:
package main
import (
"fmt"
"os"
"io/ioutil"
"net/http"
"github.com/PuerkitoBio/goquery"
)
func main() {
// URL of the Wikipedia page
url := "https://commons.wikimedia.org/wiki/List_of_dog_breeds"
// Define a user-agent header to simulate a browser request
headers := map[string]string{
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
}
// Create an HTTP client with the specified headers
client := &http.Client{}
req, err := http.NewRequest("GET", url, nil)
if err != nil {
fmt.Println("Failed to create an HTTP request:", err)
return
}
for key, value := range headers {
req.Header.Set(key, value)
}
// Send an HTTP GET request to the URL with the headers
resp, err := client.Do(req)
if err != nil {
fmt.Println("Failed to send an HTTP request:", err)
return
}
defer resp.Body.Close()
// Check if the request was successful (status code 200)
if resp.StatusCode == 200 {
// Parse the HTML content of the page
doc, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
fmt.Println("Failed to parse HTML:", err)
return
}
// Find the table with class 'wikitable sortable'
table := doc.Find(".wikitable.sortable")
// Initialize slices to store the data
names := []string{}
groups := []string{}
localNames := []string{}
photographs := []string{}
// Create a folder to save the images
os.Mkdir("dog_images", os.ModePerm)
// Iterate through rows in the table (skip the header row)
table.Find("tr").Each(func(index int, rowHtml *goquery.Selection) {
if index > 0 {
// Extract data from each column
columns := rowHtml.Find("td, th")
if columns.Length() == 4 {
name := columns.Eq(0).Find("a").Text()
group := columns.Eq(1).Text()
// Check if the second column contains a span element
spanTag := columns.Eq(2).Find("span")
localName := spanTag.Text()
// Check for the existence of an image tag within the fourth column
imgTag := columns.Eq(3).Find("img")
photograph, _ := imgTag.Attr("src")
// Download the image and save it to the folder
if photograph != "" {
imageResp, err := http.Get(photograph)
if err == nil {
defer imageResp.Body.Close()
imageData, _ := ioutil.ReadAll(imageResp.Body)
imageFilename := "dog_images/" + name + ".jpg"
ioutil.WriteFile(imageFilename, imageData, os.ModePerm)
}
}
// Append data to respective slices
names = append(names, name)
groups = append(groups, group)
localNames = append(localNames, localName)
photographs = append(photographs, photograph)
}
}
})
// Print or process the extracted data as needed
for i := 0; i < len(names); i++ {
fmt.Println("Name:", names[i])
fmt.Println("FCI Group:", groups[i])
fmt.Println("Local Name:", localNames[i])
fmt.Println("Photograph:", photographs[i])
fmt.Println()
}
} else {
fmt.Println("Failed to retrieve the web page. Status code:", resp.StatusCode)
}
}In more advanced implementations you will need to even rotate the User-Agent string so the website cant tell its the same browser!
If we get a little bit more advanced, you will realize that the server can simply block your IP ignoring all your other tricks. This is a bummer and this is where most web crawling projects fail.
Overcoming IP Blocks
Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project which gets the job done consistently and one that never really works.
Plus with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.
Browse by tags:
Browse by language:
The easiest way to do Web Scraping
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
Try ProxiesAPI for free
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...
Don't leave just yet!
Enter your email below to claim your free API key: