In this beginner-friendly guide, we will walk through a complete Scala program to scrape content from Reddit. We will extract key information like post titles, permalinks, authors and scores from Reddit posts on a webpage.
here is the page we are talking about
This will demonstrate a practical real-world example of web scraping using Scala's helpful libraries to download webpages and parse their content.
Understanding the Imports
Let's briefly go over what each import is doing:
import play.api.libs.ws._
import play.api.libs.ws.ahc._
These imports provide the web scraping capability through Play Framework's WS library (AhcWSClient).
import scala.concurrent.ExecutionContext.Implicits.global
import scala.concurrent.Await
import scala.concurrent.duration._
These imports allow asynchronous HTTP requests and waiting for their responses.
import org.jsoup.Jsoup
import org.jsoup.nodes.Document
Jsoup is a Java library used to parse and extract data from HTML and XML documents. We will use it to analyze the content we download.
Walkthrough of Main Components
Let's now understand this code section-by-section:
val redditUrl = "<https://www.reddit.com>"
This defines the Reddit URL we want to scrape. We are getting the front page.
val headers = Seq(
"User-Agent" -> "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
)
This header makes the request appear to be from a real Chrome browser. Sites like Reddit block automated scrapers so this fools their defenses.
val wsClient = AhcWSClient()
This creates an Async HTTP client using the AhcWSClient() factory method.
val responseFuture = wsClient.url(redditUrl).withHttpHeaders(headers:_*).get()
val response = Await.result(responseFuture, 10.seconds)
Here we make the GET request to the Reddit URL with our spoofed browser headers. We await the response for 10 seconds.
if (response.status == 200) {
// process content
} else {
println(s"Failed, status code ${response.status}")
}
We check if the status code returned is 200 OK. If so, we have successfully downloaded the page and can process the content.
val htmlContent = response.body[String]
This extracts the HTML content from the response body as a String.
scala.tools.nsc.io.File(filename).writeAll(htmlContent)
We write the HTML string into a file for later analysis.
val document: Document = Jsoup.parse(htmlContent)
Jsoup parses the HTML string into a Document object we can now query.
Extracting Data with Selectors
The most complex part of this program is extracting the exact data we want from the HTML content.
Inspecting the elements
Upon inspecting the HTML in Chrome, you will see that each of the posts have a particular element shreddit-post and class descriptors specific to them…
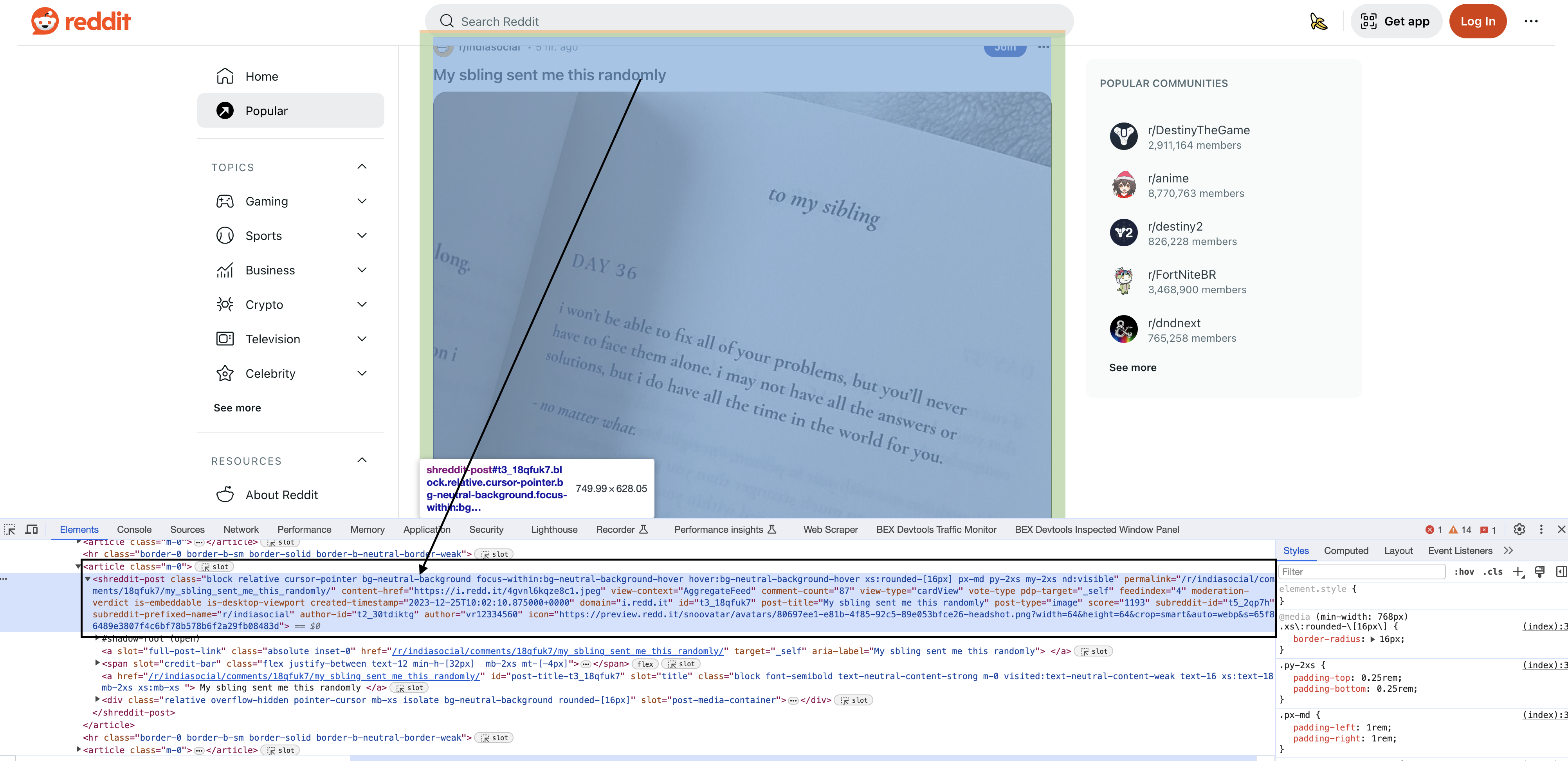
Jsoup provides CSS-style selectors to target elements by IDs, classes, attributes etc. This takes practice but is very powerful.
Let's break down this selector:
val blocks = document.select(".block.relative.cursor-pointer.bg-neutral-background.focus-within:bg-neutral-background-hover.hover:bg-neutral-background-hover.xs:rounded-\\[16px\\].p-md.my-2xs.nd:visible")
The
Our selector finds all elements with the CSS classes
This uniquely targets the Reddit post block elements even though the class names are generic.
Let's walk through extracting each field:
Permalink
val permalink = block.attr("permalink")
The
Content URL
val contentHref = block.attr("content-href")
Similar to above, this selector extracts the post's content URL from the
Comment Count
val commentCount = block.attr("comment-count")
The number of comments is stored conveniently in the
Post Title
val postTitle = block.select("div[slot=title]").text().trim
Here we search within each block for a
Author
val author = block.attr("author")
Each block contains the post author's name in an
Score
val score = block.attr("score")
The post score comes from the
And that's the process! As you can see, CSS selectors are immensely powerful for locating and extracting anything in an HTML document.
Putting It All Together
Now that we've broken down the components, here is the full code to scrape Reddit posts:
import play.api.libs.ws._
import play.api.libs.ws.ahc._
import scala.concurrent.ExecutionContext.Implicits.global
import scala.concurrent.Await
import scala.concurrent.duration._
import org.jsoup.Jsoup
import org.jsoup.nodes.Document
object RedditScraper extends App {
// Define the Reddit URL you want to download
val redditUrl = "https://www.reddit.com"
// Define a User-Agent header
val headers = Seq(
"User-Agent" -> "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
)
// Create an AsyncHttpClient instance
val wsClient = AhcWSClient()
// Send a GET request to the URL with the User-Agent header
val responseFuture = wsClient.url(redditUrl).withHttpHeaders(headers: _*).get()
val response = Await.result(responseFuture, 10.seconds)
// Check if the request was successful (status code 200)
if (response.status == 200) {
// Get the HTML content of the page
val htmlContent = response.body[String]
// Specify the filename to save the HTML content
val filename = "reddit_page.html"
// Save the HTML content to a file
scala.tools.nsc.io.File(filename).writeAll(htmlContent)
println(s"Reddit page saved to $filename")
// Parse the HTML content
val document: Document = Jsoup.parse(htmlContent)
// Find all blocks with the specified tag and class
val blocks = document.select(".block.relative.cursor-pointer.bg-neutral-background.focus-within:bg-neutral-background-hover.hover:bg-neutral-background-hover.xs:rounded-[16px].p-md.my-2xs.nd:visible")
// Iterate through the blocks and extract information from each one
blocks.forEach { block =>
val permalink = block.attr("permalink")
val contentHref = block.attr("content-href")
val commentCount = block.attr("comment-count")
val postTitle = block.select("div[slot=title]").text().trim
val author = block.attr("author")
val score = block.attr("score")
// Print the extracted information for each block
println(s"Permalink: $permalink")
println(s"Content Href: $contentHref")
println(s"Comment Count: $commentCount")
println(s"Post Title: $postTitle")
println(s"Author: $author")
println(s"Score: $score")
println("\n")
}
} else {
println(s"Failed to download Reddit page (status code ${response.status})")
}
// Close the AsyncHttpClient
wsClient.close()
}