Web scraping dynamic websites that load content dynamically can be challenging. However, the Selenium browser automation tool makes it possible!
Overview
Traditional scraping tools like Beautiful Soup are designed for static HTML pages. When websites rely heavily on JavaScript to load content, those tools fail.
Selenium provides a way to automate web browsers programmatically. This allows you to:
In this guide, we'll cover the key steps to scrape dynamic sites with Selenium:
Setting Up Selenium
To start, install Selenium and import it:
from selenium import webdriver
Then launch a browser (we'll use Chrome here):
driver = webdriver.Chrome()
You can now use this
Locating Page Elements
To extract data, first identify the elements that contain what you need.
Use the browser inspector to view the HTML and locate elements by:
For example, to get video elements on YouTube:
from selenium.webdriver.common.by import By
videos = driver.find_elements(By.CLASS_NAME, 'style-scope ytd-rich-item-renderer')
Make sure to import
Extracting Data from Elements
Once you've located an element, extract text or other attributes using:
title = title_element.text
For nested elements, first find the parent element:
title_element = video.find_element(By.XPATH, './/h3/a')
Then extract text from the nested element.
Storing Scraped Data
To save scraped data, store in lists or dicts and convert to DataFrame:
data = []
for video in videos:
title = ...
views = ...
vid = {'title': title, 'views': views}
data.append(vid)
df = pd.DataFrame(data)
You can then export to CSV, JSON, databases, etc.
Putting It All Together
Let's walk through a full scraping script:
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
url = '<https://www.youtube.com/@MicrosoftDeveloper/videos>'
driver = webdriver.Chrome()
driver.get(url)
videos = driver.find_elements(By.CLASS_NAME, 'style-scope ytd-rich-item-renderer')
data = []
for video in videos:
title_element = video.find_element(By.XPATH, './/h3/a')
title = title_element.text
views_element = video.find_element(By.XPATH, './/span[contains(@class,"inline-metadata-item")]')
views = views_element.text
age_elements = video.find_elements(By.XPATH, './/span[contains(@class, "inline-metadata-item")]')
second_age = age_elements[1]
age = second_age.text
vid = {'title': title, 'views': views, 'age': age}
data.append(vid)
df = pd.DataFrame(data)
print(df)
driver.quit()
You should see the results printed like this…
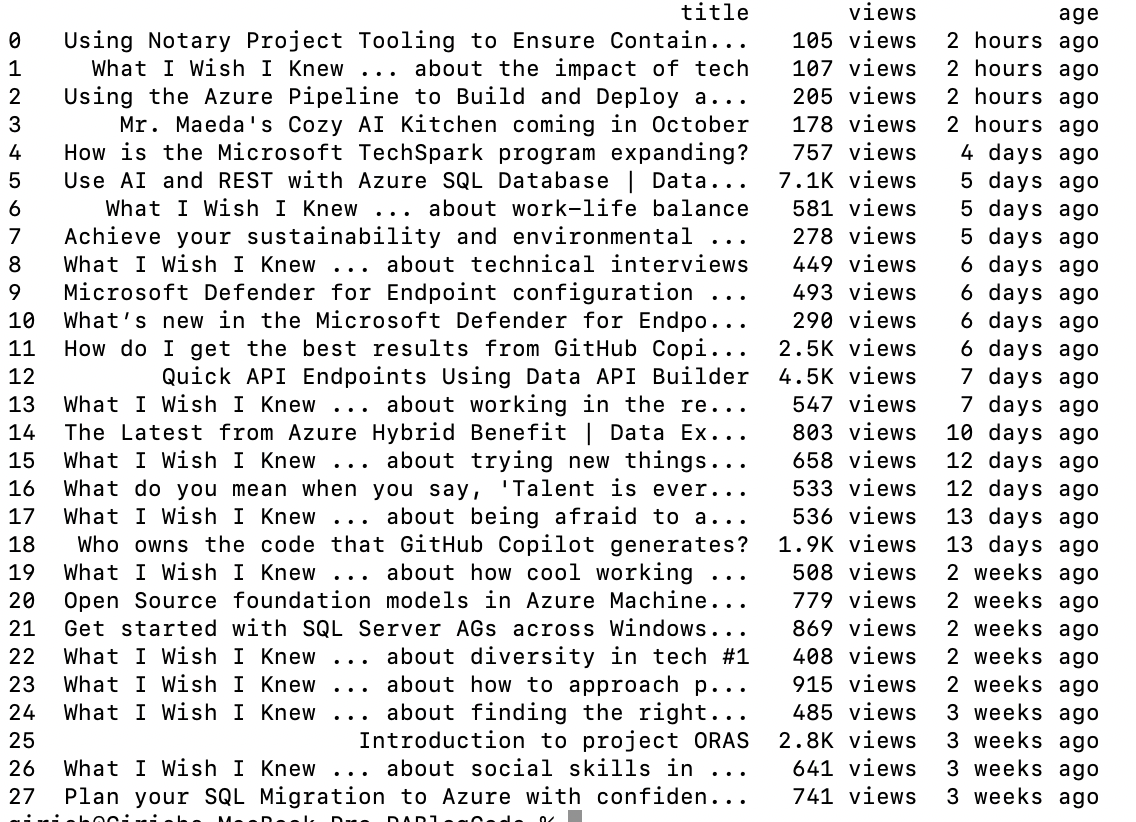
While Selenium provides a great way to learn web scraping fundamentals, it has some limitations in robustness and scale when it comes to commercial scraping projects.
For production-level web scraping, consider using a specialized service like ProxiesAPI.com. It handles all the complexities of automation and scraping behind a rotating proxy network.
With features like:
You can scrape any site with a simple API call, without worrying about blocks.
New users get 1000 free API calls. Get your API key here to turbo-charge your web scraping project!
Focus on data extraction, and let Proxies API take care of the scraping infrastructure.