Scraping and downloading all images from a website is a handy technique for researchers, developers, and personal projects. Modern C++ libraries make this surprisingly easy but a bit of HTML, CSS and programming knowledge is needed to pull it off.
This is page we are talking about…
Overview of the C++ Image Scraping Code
While individual libraries and selectors differ based on the target site, the high-level structure usually follows this template:
Initialize libraries like libcurl and libxml2 in C++.
Send an HTTP request using libcurl to download the target page HTML.
Parse the HTML content using libxml2's DOM traversal functions.
Use CSS selectors to identify and extract image URLs into a list.
Iterate through the list of URLs to download each image file using libcurl with unique filenames.
Handle issues like broken images, invalid CSS selectors gracefully.
That covers the broad strokes but the specifics require deeper understanding...
Initializing the C++ Image Scraping Tools
The first step sets up the libraries we'll leverage later for actually downloading and parsing content from the web:
For those unfamiliar, libcurl handles the HTTP requests and responses while libxml2 processes HTML and XML documents so we can analyze and extract data using standard DOM traversal methods.
We set some options throughout the program to configure aspects like the user agent string and callbacks but the initialization gets our foundation in place.
Sending Requests and Receiving the HTML Response
Next we use libcurl to actually send a GET request to the Wikipedia URL and store the full HTML content of the page in a string variable called response.
The key aspects that enable receiving and processing the entire raw HTML are:
// Set callback function to store response
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
// Response data will be saved here
std::string response_data;
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &response_data);
We define a custom callback function WriteCallback that receives the chunks of response data and accumulates them in our string.
With that foundation set up, we simply call curl_easy_perform to send the request and get back the full HTML response from Wikipedia to start our scraping workflow.
Parsing HTML with libxml2
Once the HTML content is fetched, it's parsed using libxml2:
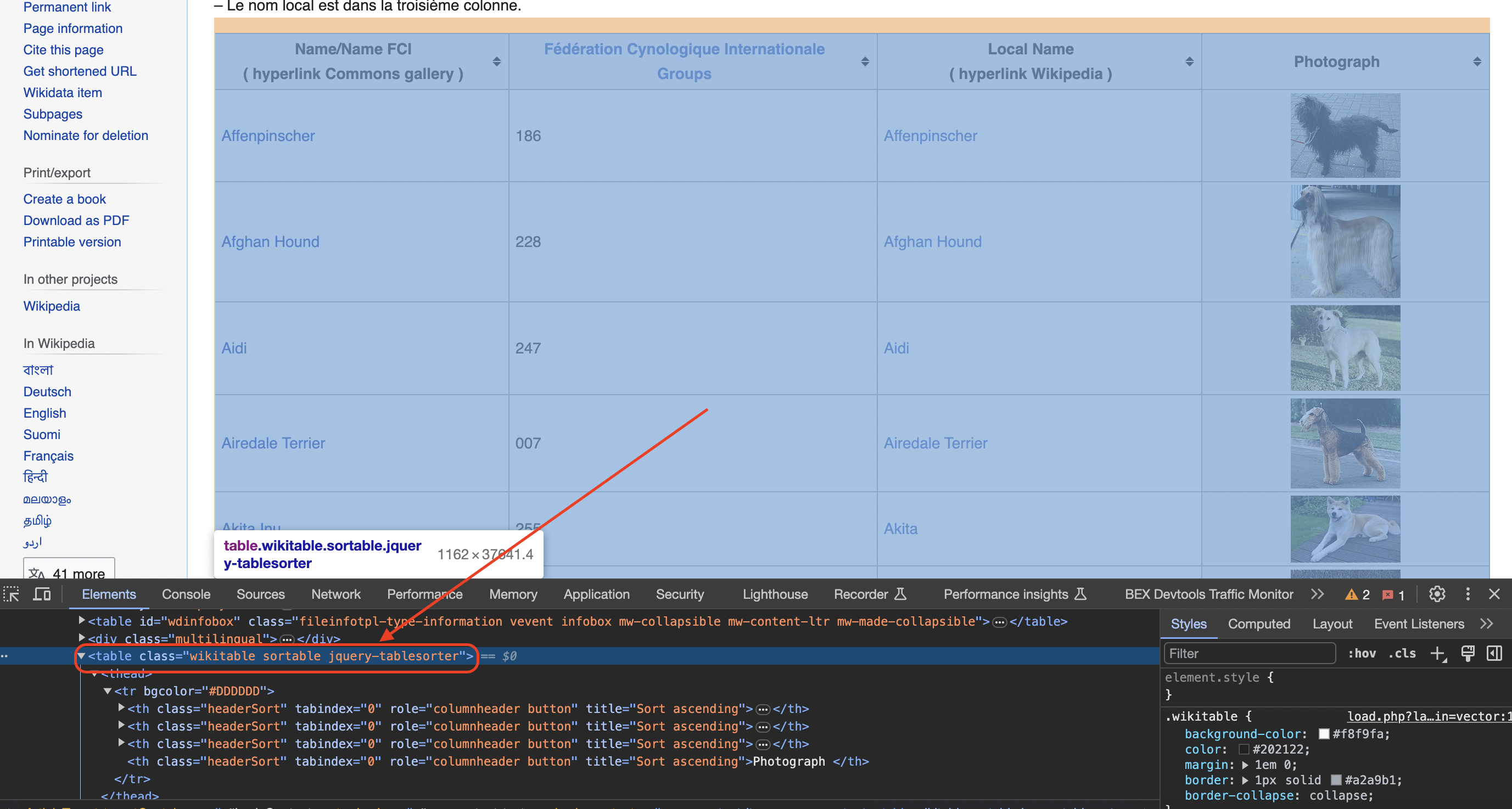
The code iterates through the nodes of the document to find a
element with the class 'wikitable sortable'.
xmlDocGetRootElement gets the root element of the document.
xmlNodePtr is a pointer to an XML node.
xmlGetProp fetches the value of a property (in this case, the class name of the table).
Processing Rows and Columns
Upon locating the table, the code processes each row (
) and column (
or
):
for (xmlNodePtr row = xmlFirstElementChild(table); row != nullptr; row = xmlNextElementSibling(row)) {
if (xmlStrcmp(row->name, reinterpret_cast<const xmlChar*>("tr")) == 0) {
xmlNodePtr column = xmlFirstElementChild(row);
std::string name, group, local_name, photograph;
int columnIndex = 0;
// ... Process each column
}
}
xmlFirstElementChild and xmlNextElementSibling are used to iterate over the rows of the table.
The inner loop processes each column, extracting text and, in the case of the image column, the src attribute of the tag.
Handling Image URLs
In the specific column for images, the code looks for an tag and extracts the URL:
if (imgTag && xmlStrcmp(imgTag->name, reinterpret_cast<const xmlChar*>("img")) == 0) {
const xmlChar* imgSrc = xmlGetProp(imgTag, reinterpret_cast<const xmlChar*>("src"));
if (imgSrc) {
photograph = reinterpret_cast<const char*>(imgSrc);
// ... Code to download the image
}
}
xmlGetProp gets the src attribute of the tag, which is the URL of the image.
Storing Extracted Data
The extracted data (dog breed names, groups, local names, and image URLs) is stored in vectors:
std::vector<std::string> names;
std::vector<std::string> groups;
std::vector<std::string> local_names;
std::vector<std::string> photographs;
// ... Append data to these vectors
Each piece of data extracted from the columns is appended to these vectors for later use.
Downloading Images with Error Handling
The last major phase is to iterate through the extracted image URLs and actually download each file using libcurl. This part looks similar to our initial request but instead of getting HTML content back, we write the binary image data directly to a file.
We also add checks for common issues:
// Download and save each image URL
for(string url : downloads) {
// Open a file stream
std::ofstream img_file(filename);
// Download image
curl_easy_setopt(curl, CURLOPT_URL, url);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &img_file);
res = curl_easy_perform(curl);
// Validate file size to check for issues
int file_size = img_file.tellp();
if (file_size < 500) {
// Handle errors gracefully
print("Error downloading ", url);
}
// Close this image file
img_file.close();
}
We open unique image files to store each download locally, set the binary write callback to that file stream, kick off the download with curl_easy_perform, and finally check that a valid large file was written to catch any errors.
The full code
To tie the entire process together, here is a complete program to scrape images from a dogs Wikipedia page:
#include <iostream>
#include <string>
#include <fstream>
#include <vector>
#include <curl/curl.h>
#include <libxml/HTMLparser.h>
#include <libxml/xpath.h>
// URL of the Wikipedia page
const std::string url = "https://commons.wikimedia.org/wiki/List_of_dog_breeds";
// User-agent header to simulate a browser request
const std::string userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36";
// Function to write response data to a string
size_t WriteCallback(void* contents, size_t size, size_t nmemb, std::string* output) {
size_t totalSize = size * nmemb;
output->append(static_cast<char*>(contents), totalSize);
return totalSize;
}
int main() {
// Initialize libcurl
CURL* curl = curl_easy_init();
if (!curl) {
std::cerr << "Failed to initialize libcurl." << std::endl;
return 1;
}
// Set libcurl options
curl_easy_setopt(curl, CURLOPT_URL, url.c_str());
curl_easy_setopt(curl, CURLOPT_USERAGENT, userAgent.c_str());
// Response data will be stored here
std::string response_data;
// Set the write callback function to capture response data
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &response_data);
// Send an HTTP GET request
CURLcode res = curl_easy_perform(curl);
// Check if the request was successful (status code 200)
if (res == CURLE_OK) {
// Initialize libxml2
htmlDocPtr doc = htmlReadDoc(reinterpret_cast<const xmlChar*>(response_data.c_str()), nullptr, nullptr, HTML_PARSE_RECOVER | HTML_PARSE_NOERROR);
if (doc) {
// Find the table with class 'wikitable sortable'
xmlNodePtr table = nullptr;
xmlNodePtr cur = xmlDocGetRootElement(doc);
while (cur != nullptr) {
if (cur->type == XML_ELEMENT_NODE && xmlStrcmp(cur->name, reinterpret_cast<const xmlChar*>("table")) == 0) {
const xmlChar* className = xmlGetProp(cur, reinterpret_cast<const xmlChar*>("class"));
if (className && xmlStrcmp(className, reinterpret_cast<const xmlChar*>("wikitable sortable")) == 0) {
table = cur;
break;
}
}
cur = cur->next;
}
if (table) {
// Initialize lists to store the data
std::vector<std::string> names;
std::vector<std::string> groups;
std::vector<std::string> local_names;
std::vector<std::string> photographs;
// Create a folder to save the images
std::string imageFolder = "dog_images";
if (mkdir(imageFolder.c_str(), 0755) != 0 && errno != EEXIST) {
std::cerr << "Failed to create the image folder." << std::endl;
return 1;
}
// Iterate through rows in the table (skip the header row)
for (xmlNodePtr row = xmlFirstElementChild(table); row != nullptr; row = xmlNextElementSibling(row)) {
if (xmlStrcmp(row->name, reinterpret_cast<const xmlChar*>("tr")) == 0) {
xmlNodePtr column = xmlFirstElementChild(row);
std::string name, group, local_name, photograph;
int columnIndex = 0;
while (column != nullptr) {
if (xmlStrcmp(column->name, reinterpret_cast<const xmlChar*>("td")) == 0 ||
xmlStrcmp(column->name, reinterpret_cast<const xmlChar*>("th")) == 0) {
std::string columnText = reinterpret_cast<const char*>(xmlNodeGetContent(column));
switch (columnIndex) {
case 0:
name = columnText;
break;
case 1:
group = columnText;
break;
case 2:
local_name = columnText;
break;
case 3:
{
xmlNodePtr imgTag = xmlFirstElementChild(column);
if (imgTag && xmlStrcmp(imgTag->name, reinterpret_cast<const xmlChar*>("img")) == 0) {
const xmlChar* imgSrc = xmlGetProp(imgTag, reinterpret_cast<const xmlChar*>("src"));
if (imgSrc) {
photograph = reinterpret_cast<const char*>(imgSrc);
// Download the image and save it to the folder
if (!photograph.empty()) {
std::string image_url = photograph;
CURL* img_curl = curl_easy_init();
if (img_curl) {
std::string image_filename = imageFolder + "/" + name + ".jpg";
std::ofstream img_file(image_filename, std::ios::binary);
curl_easy_setopt(img_curl, CURLOPT_URL, image_url.c_str());
curl_easy_setopt(img_curl, CURLOPT_WRITEDATA, &img_file);
curl_easy_perform(img_curl);
curl_easy_cleanup(img_curl);
}
}
}
}
}
break;
}
columnIndex++;
}
column = xmlNextElementSibling(column);
}
// Append data to respective lists
names.push_back(name);
groups.push_back(group);
local_names.push_back(local_name);
photographs.push_back(photograph);
}
}
// Print or process the extracted data as needed
for (size_t i = 0; i < names.size(); i++) {
std::cout << "Name: " << names[i] << std::endl;
std::cout << "FCI Group: " << groups[i] << std::endl;
std::cout << "Local Name: " << local_names[i] << std::endl;
std::cout << "Photograph: " << photographs[i] << std::endl;
std::cout << std::endl;
}
} else {
std::cerr << "Failed to find the table with class 'wikitable sortable'." << std::endl;
}
// Cleanup libxml2
xmlFreeDoc(doc);
} else {
std::cerr << "Failed to parse the HTML document." << std::endl;
}
} else {
std::cerr << "Failed to retrieve the web page. CURLcode: " << res << std::endl;
}
// Cleanup libcurl
curl_easy_cleanup(curl);
return 0;
}
In more advanced implementations you will need to even rotate the User-Agent string so the website cant tell its the same browser!
If we get a little bit more advanced, you will realize that the server can simply block your IP ignoring all your other tricks. This is a bummer and this is where most web crawling projects fail.
Overcoming IP Blocks
Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project which gets the job done consistently and one that never really works.
Plus with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
With millions of high speed rotating proxies located all over the world,
With our automatic IP rotation
With our automatic User-Agent-String rotation (which simulates requests from different, valid web browsers and web browser versions)
With our automatic CAPTCHA solving technology,
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
We have a running offer of 1000 API calls completely free. Register and get your free API Key here.
Browse by tags:
Browse by language:
The easiest way to do Web Scraping
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you