Parsing through an unfamiliar code base can be intimidating for beginner programmers. When facing lines of code, it's hard to know where to start or what exactly is happening.
In this article, we'll walk step-by-step through a sample program that scrapes posts from Reddit. We'll learn how it:
here is the page we are talking about
By the end, you'll understand the key concepts so you can adapt the code for your own scraping projects!
Downloading the Page
First, we create a
NSString *redditUrl = @"<https://www.reddit.com>";
Next, we convert that string into a
NSURL *url = [NSURL URLWithString:redditUrl];
Think of the
We then create a
NSMutableURLRequest *request = [NSMutableURLRequest requestWithURL:url];
Requests allow us to specify things like headers. Here, we add a User-Agent header to mimic a desktop browser:
[request setValue:@"Mozilla/5.0..." forHTTPHeaderField:@"User-Agent"];
Finally, we use
NSURLSessionDataTask *task = [[NSURLSession sharedSession] dataTaskWithRequest:request completionHandler:^(NSData *data, NSURLResponse *response, NSError *error) {
// Handle response
}];
[task resume];
This downloads the contents of the Reddit homepage for us to start scraping!
Parsing the HTML
Inside the completion handler, we first check if any errors occurred. If not, we:
- Cast the
NSURLResponse to aNSHTTPURLResponse so we can read the status code - Check for a 200 OK status
- Convert the
NSData *data into a string containing HTML
if (error) {
// Handle error
} else {
NSHTTPURLResponse *httpResponse = (NSHTTPURLResponse *)response;
if (httpResponse.statusCode == 200) {
NSString *htmlContent = [[NSString alloc] initWithData:data encoding:NSUTF8StringEncoding];
}
}
With the HTML stored as a string, we can parse it. We use the
Think of this like converting the HTML string into an object we can programmatically analyze.
htmlDocPtr doc = htmlReadDoc((const xmlChar *)[htmlContent UTF8String], NULL, NULL, HTML_PARSE_RECOVER | HTML_PARSE_NOERROR | HTML_PARSE_NOWARNING);
The parsing options passed in handle small errors without stopping. This helps account for "real world" HTML that may not be perfectly formatted.
Extracting Post Data
Inspecting the elements
Upon inspecting the HTML in Chrome, you will see that each of the posts have a particular element shreddit-post and class descriptors specific to them…
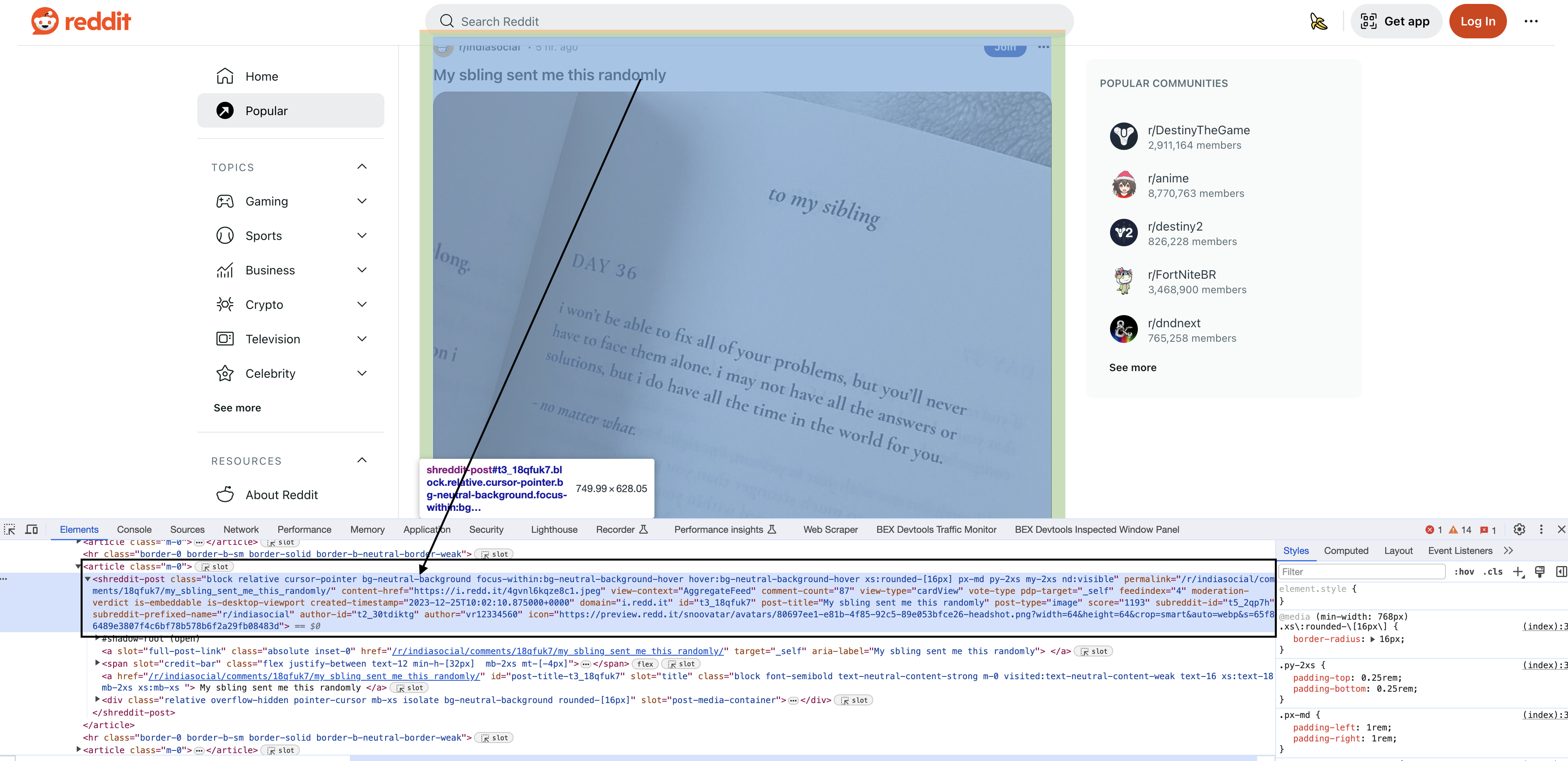
With the document parsed, we can now use XPath selectors to pull out pieces of information.
xmlXPathContextPtr xpathCtx = xmlXPathNewContext(doc);
NSString *xpathExpression = @"//div[contains(@class,'shreddit-post')]";
xmlXPathObjectPtr xpathObj = xmlXPathEvalExpression((const xmlChar *)[xpathExpression UTF8String], xpathCtx);
Walking through this:
The key thing to understand here is that
Some examples of XPaths:
In our Reddit scraping code, the XPaths to extract specific fields would go here. Make sure not to modify these string literals!
With the matched nodes selected, we can now loop through and extract info:
for (int i = 0; i < count; i++) {
RedditPost *post = [[RedditPost alloc] init];
// Extract data
post.permalink = @"";
post.contentHref = @"";
// ...
}
We create
Later on, we can access these objects to work with the scraped content!
Putting It All Together
While individual concepts like requests, XPath and DOM manipulation may be unfamiliar at first, by relating them to more tangible analogies and walking through the flow step-by-step, we can decode what this scraping script is doing under the hood!
The key points to remember are:
And voila, we've scraped Reddit!
Here is the full code sample again to tinker with:
#import <Foundation/Foundation.h>
#import <libxml2/libxml/HTMLparser.h>
// Define a data structure to store extracted information
@interface RedditPost : NSObject
@property (nonatomic, strong) NSString *permalink;
@property (nonatomic, strong) NSString *contentHref;
@property (nonatomic, strong) NSString *commentCount;
@property (nonatomic, strong) NSString *postTitle;
@property (nonatomic, strong) NSString *author;
@property (nonatomic, strong) NSString *score;
@end
@implementation RedditPost
@end
int main(int argc, const char * argv[]) {
@autoreleasepool {
// Define the Reddit URL you want to download
NSString *redditUrl = @"https://www.reddit.com";
// Create a NSURL object from the URL string
NSURL *url = [NSURL URLWithString:redditUrl];
if (url) {
// Create a NSMutableURLRequest with the URL
NSMutableURLRequest *request = [NSMutableURLRequest requestWithURL:url];
// Set the User-Agent header
[request setValue:@"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36" forHTTPHeaderField:@"User-Agent"];
// Send a GET request
NSURLSessionDataTask *task = [[NSURLSession sharedSession] dataTaskWithRequest:request completionHandler:^(NSData *data, NSURLResponse *response, NSError *error) {
if (error) {
NSLog(@"Failed to download Reddit page: %@", [error localizedDescription]);
} else {
// Check if the response status code is 200 (OK)
NSHTTPURLResponse *httpResponse = (NSHTTPURLResponse *)response;
if (httpResponse.statusCode == 200) {
// Get the HTML content as a string
NSString *htmlContent = [[NSString alloc] initWithData:data encoding:NSUTF8StringEncoding];
// Parse the HTML content using libxml2
htmlDocPtr doc = htmlReadDoc((const xmlChar *)[htmlContent UTF8String], NULL, NULL, HTML_PARSE_RECOVER | HTML_PARSE_NOERROR | HTML_PARSE_NOWARNING);
if (doc) {
// Create an array to store RedditPost objects
NSMutableArray *redditPosts = [NSMutableArray array];
// Example of how to extract information from the parsed HTML document
xmlXPathContextPtr xpathCtx = xmlXPathNewContext(doc);
if (xpathCtx) {
// Use XPath expressions to extract data
NSString *xpathExpression = @"//div[contains(@class,'shreddit-post')]";
xmlXPathObjectPtr xpathObj = xmlXPathEvalExpression((const xmlChar *)[xpathExpression UTF8String], xpathCtx);
if (xpathObj) {
int count = xpathObj->nodesetval->nodeNr;
for (int i = 0; i < count; i++) {
// Create a RedditPost object to store data
RedditPost *post = [[RedditPost alloc] init];
// Extract data for each post
// You will need to modify these XPath expressions to match Reddit's actual structure
post.permalink = @"";
post.contentHref = @"";
post.commentCount = @"";
post.postTitle = @"";
post.author = @"";
post.score = @"";
[redditPosts addObject:post];
}
xmlXPathFreeObject(xpathObj);
}
xmlXPathFreeContext(xpathCtx);
}
// Now you have an array of RedditPost objects with extracted data
for (RedditPost *post in redditPosts) {
NSLog(@"Permalink: %@", post.permalink);
NSLog(@"Content Href: %@", post.contentHref);
NSLog(@"Comment Count: %@", post.commentCount);
NSLog(@"Post Title: %@", post.postTitle);
NSLog(@"Author: %@", post.author);
NSLog(@"Score: %@", post.score);
NSLog(@"\n");
}
// Example of how to free the parsed document when done
xmlFreeDoc(doc);
} else {
NSLog(@"Failed to parse HTML content");
}
} else {
NSLog(@"Failed to download Reddit page (status code %ld)", (long)httpResponse.statusCode);
}
}
}];
// Start the task
[task resume];
} else {
NSLog(@"Invalid Reddit URL");
}
}
return 0;
}The concepts here appear in all kinds of web scraping tasks, so grasping these core ideas empowers you to start scraping data across the internet!