In the early stages of a web crawling project or when you need to scale to just a few hundred requests, a simple proxy rotator that populates itself from free proxy pools can be useful.
We can use a website like sslproxies.org to fetch public proxies periodically and use them in our R scripts.
This is what the site looks like:
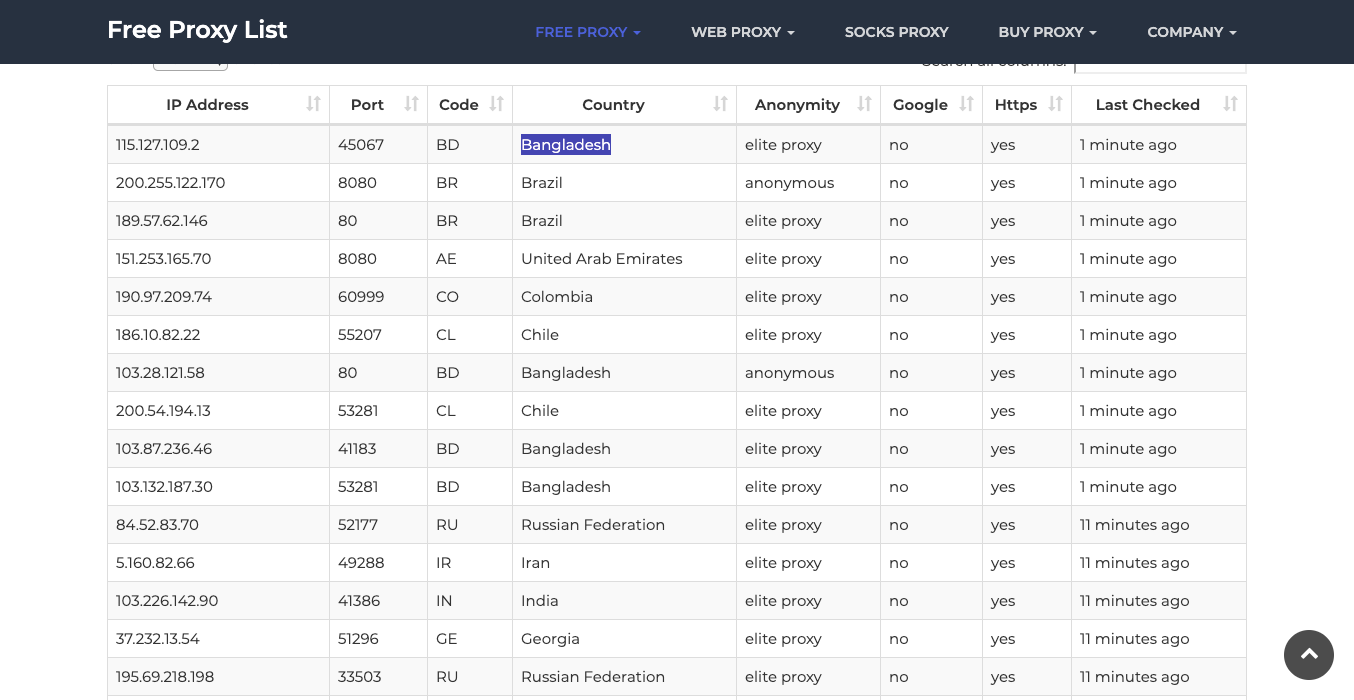
And if you check the HTML using the inspect tool, you will see the full content is encapsulated in a table with the id proxylisttable
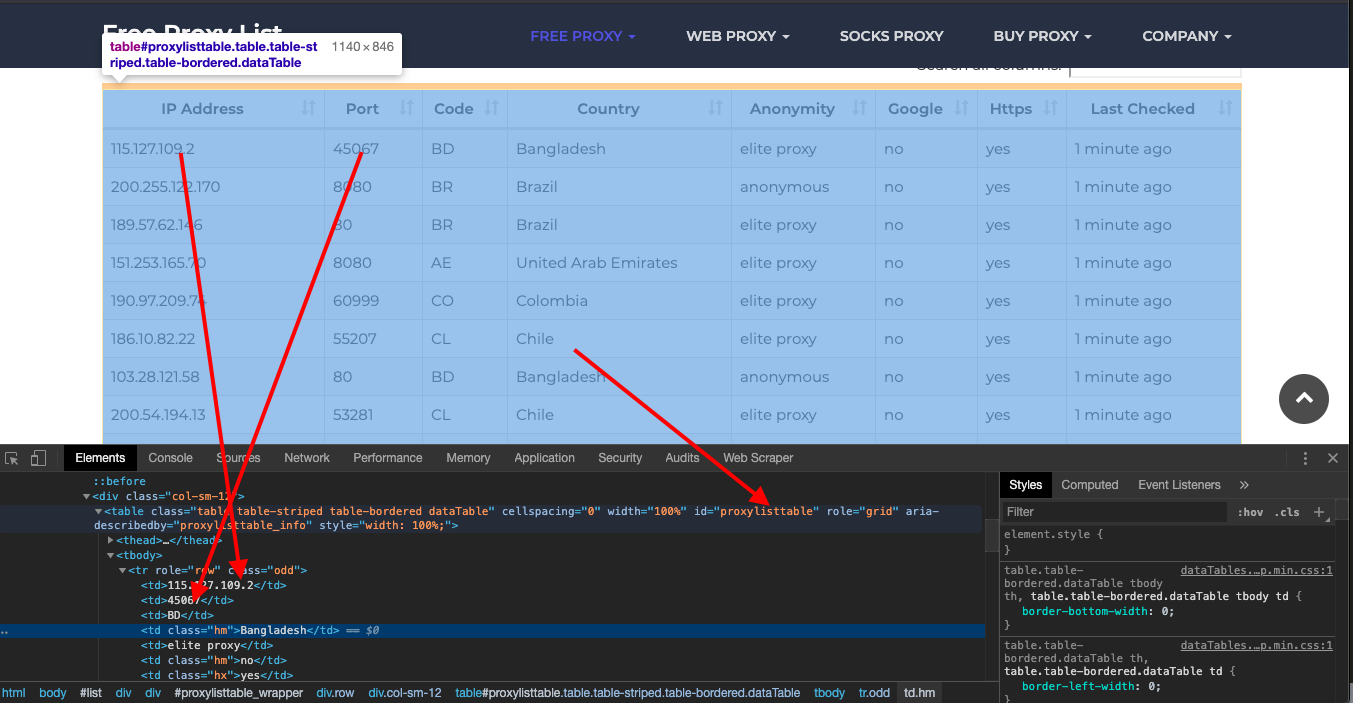
The IP and port are the first and second elements in each row.
We can use the following code to select the table and its rows to iterate on and further pull out the first and second elements of the elements.
Let's walk through a simple tutorial to do this in R. We'll use the rvest package for web scraping.
Setup
First, install and load the rvest package:
install.packages("rvest")
library(rvest)
Fetching Proxies
Our basic fetch code looks like this:
url <- '<https://sslproxies.org/>'
header <- list(
'User-Agent' = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
)
response <- rvest::get(url, headers = header)
This gets the HTML from sslproxies.org using a browser User-Agent string.
The full proxy list is in a table with id
proxies <- vector('list', 0)
proxy_table <- response %>%
html_nodes('#proxylisttable tr')
for(row in proxy_table){
ip <- row %>%
html_nodes('td') %>%
.[[1]] %>%
html_text()
port <- row %>%
html_nodes('td') %>%
.[[2]] %>%
html_text()
proxies <- c(proxies, list(ip = ip, port = port))
}
This loops through the table rows, extracts the IP and port from the table cells, and adds them to a proxies list.
Fetch Proxies Function
Let's wrap this in a function we can call whenever we want to refresh the proxies:
fetch_proxies <- function() {
url <- '<https://sslproxies.org/>'
header <- list(
'User-Agent' = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
)
response <- rvest::get(url, headers = header)
proxies <- vector('list', 0)
proxy_table <- response %>%
html_nodes('#proxylisttable tr')
for(row in proxy_table){
ip <- row %>%
html_nodes('td') %>%
.[[1]] %>%
html_text()
port <- row %>%
html_nodes('td') %>%
.[[2]] %>%
html_text()
proxies <- c(proxies, list(ip = ip, port = port))
}
return(proxies)
}
Call it to populate the proxies:
proxies <- fetch_proxies()
Selecting a Random Proxy
To use a random proxy from the list:
proxy_index <- sample(seq_along(proxies), size = 1)
ip <- proxies[[proxy_index]]$ip
port <- proxies[[proxy_index]]$port
This picks a random index, then extracts the IP and port.
Full Code
Here is the full code:
# Install rvest
install.packages("rvest")
library(rvest)
# Fetch proxies function
fetch_proxies <- function() {
url <- '<https://sslproxies.org/>'
header <- list(
'User-Agent' = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
)
response <- rvest::get(url, headers = header)
proxies <- vector('list', 0)
proxy_table <- response %>%
html_nodes('#proxylisttable tr')
for(row in proxy_table){
ip <- row %>%
html_nodes('td') %>%
.[[1]] %>%
html_text()
port <- row %>%
html_nodes('td') %>%
.[[2]] %>%
html_text()
proxies <- c(proxies, list(ip = ip, port = port))
}
return(proxies)
}
# Populate proxies
proxies <- fetch_proxies()
# Select random proxy
proxy_index <- sample(seq_along(proxies), size = 1)
ip <- proxies[[proxy_index]]$ip
port <- proxies[[proxy_index]]$port
print(paste("IP:", ip))
print(paste("Port:", port))
This provides a simple proxy rotator in R that can help avoid blocks when scraping.
If you want to use this in production and want to scale to thousands of links, then you will find that many free proxies won't hold up under the speed and reliability requirements. In this scenario, using a rotating proxy service to rotate IPs is almost a must.
Otherwise, you tend to get IP blocked a lot by automatic location, usage, and bot detection algorithms.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
A simple API can access the whole thing like below in any programming language.
curl "<http://api.proxiesapi.com/?key=API_KEY&url=https://example.com>"
We have a running offer of 1000 API calls completely free. Register and get your free API Key here.